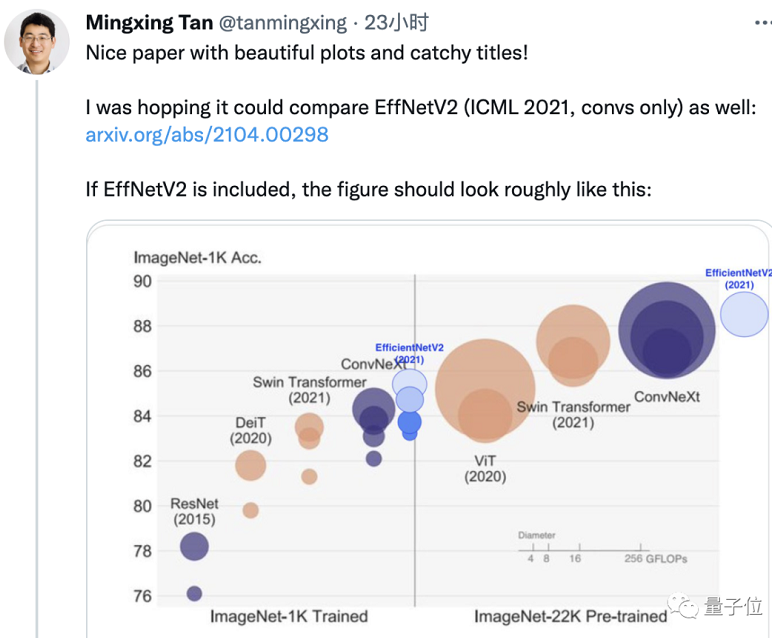
2021年, Transformer频频跨界视觉领域
先是图像分类上被谷歌ViT突破,后来目标检测和图像分割又被微软Swin Transformer拿下。
ViT
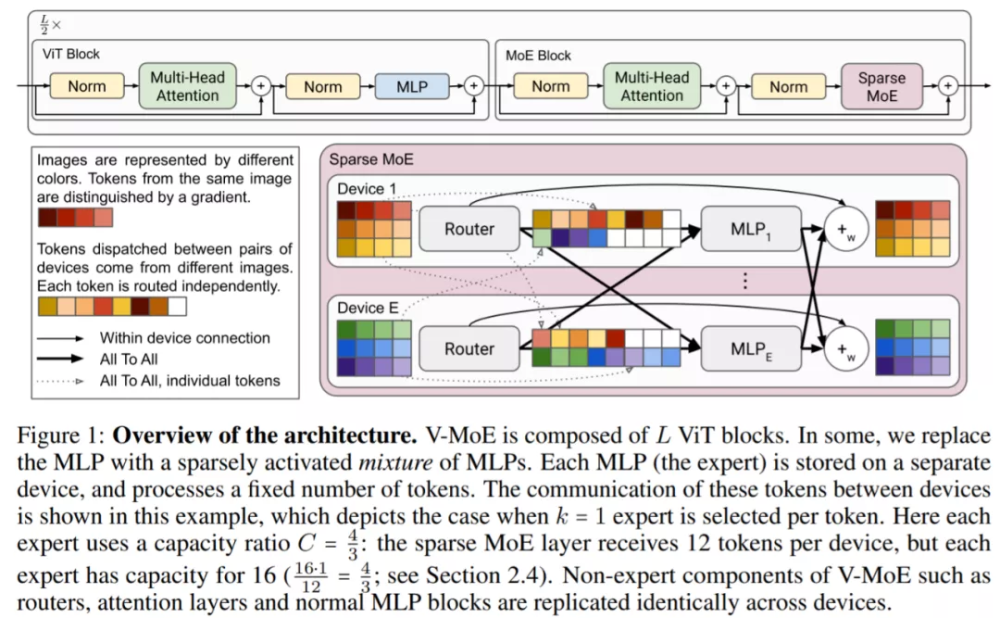
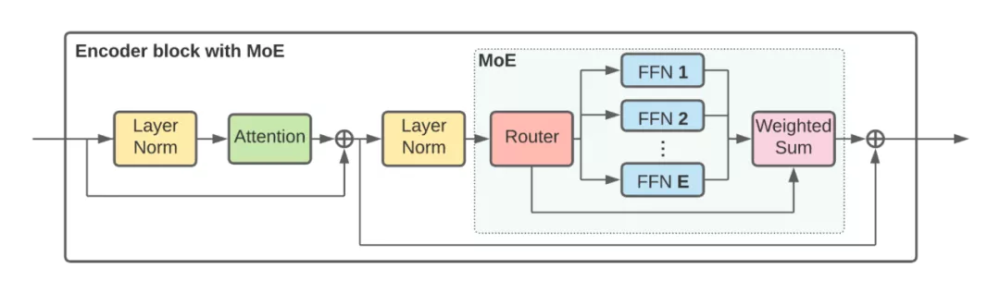
为了大规模扩展视觉模型,该研究将 ViT 架构中的一些密集前馈层 (FFN) 替换为独立 FFN 的稀疏混合(称之为专家)。可学习的路由层为每个独立的 token 选择对应的专家。也就是说,来自同一图像的不同 token 可能会被路由到不同的专家。在总共 E 位专家(E 通常为 32)中,每个 token 最多只能路由到 K(通常为 1 或 2)位专家。这允许扩展模型的大小,同时保持每个 token 计算的恒定。下图更详细地显示了 V-MoE 编码器块的结构。
https://new.qq.com/omn/20220116/20220116A03WQ600.html
Swin Transformer
微软
ConvNeXt
Facebook与UC伯克利
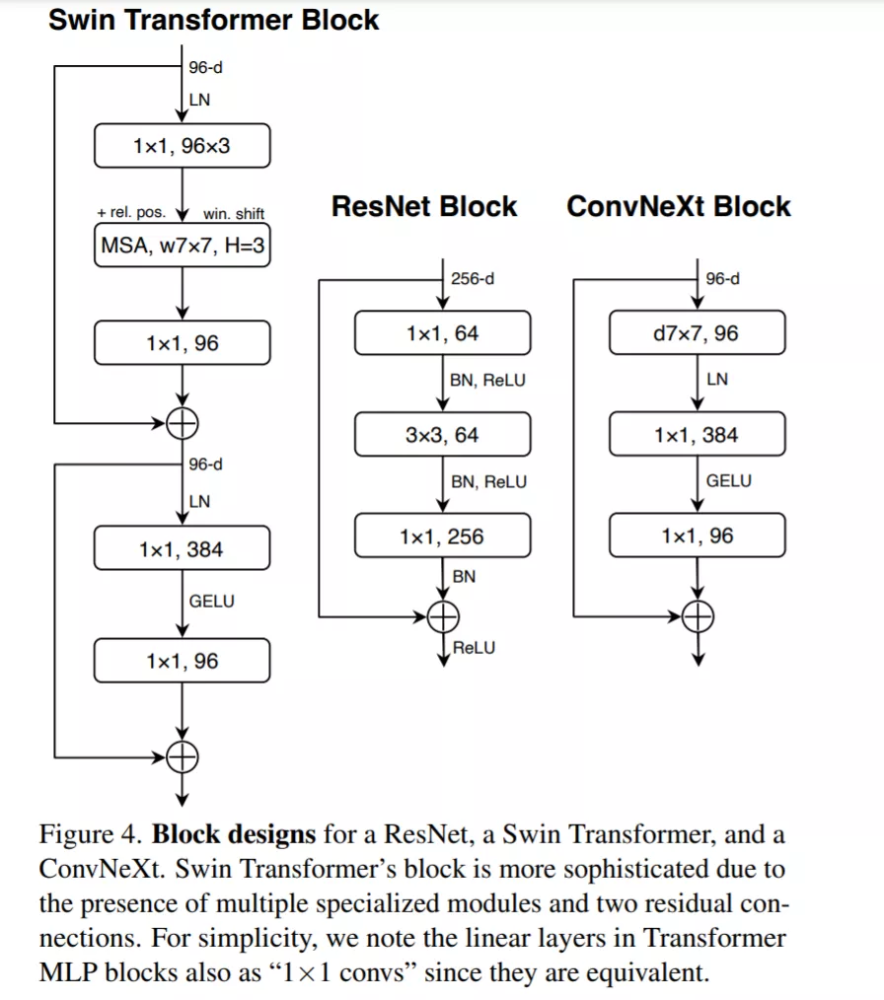
该研究制定了一系列设计决策,总结为 1) 宏观设计,2) ResNeXt,3) 反转瓶颈,4) 卷积核大小,以及 5) 各种逐层微设计。
Transformer 中一个重要的设计是创建了反转瓶颈,即 MLP 块的隐藏维度比输入维度宽四倍,如下图 4 所示。
EfficientNet v2