[TOC]
3D-CNN Method
| iDT | ||
| LRCN | CVPR 2015 | |
| LSTM composite model | ||
| C3D | 2015 | |
| TSN | ECCV 2016 | |
| R3DCNN | NVIDIA | 2016 |
| P3D | MSRA | ICCV 2017 |
| R3D/2.5D | 2017 | |
| T3D | 2017 | |
| R2+1D | 2018 |
–
General Lib:
[ video model zoo (caffe2) ] https://github.com/facebookresearch/VMZ
Currently, this codebase supports the following models:
- R(2+1)D, MCx models [1].
- CSN models [2].
- R(2+1)D and CSN models pre-trained on large-scale (65 million!) weakly-supervised public Instagram videos (IG-65M) [3].
C3D
[github caffe ]https://github.com/facebook/C3D
[ github tensorflow ]https://github.com/hx173149/C3D-tensorflow
[github pytorch] https://github.com/jfzhang95/pytorch-video-recognition
3x3x3 kernel

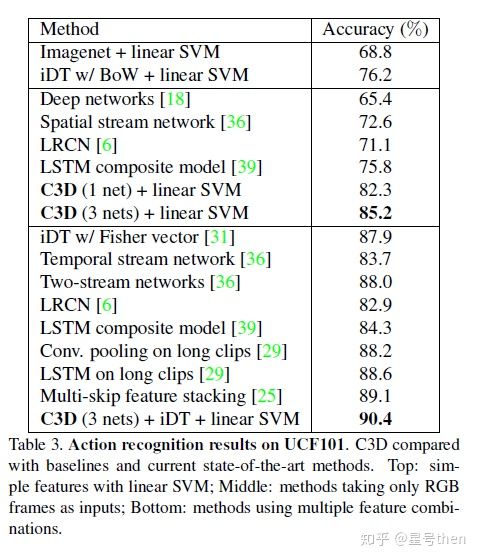
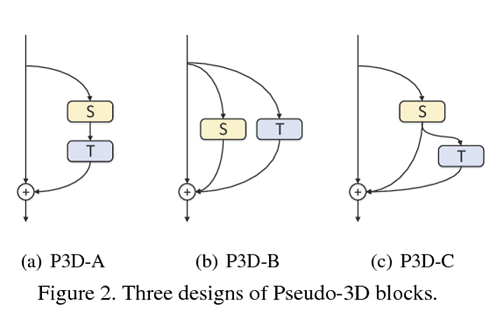
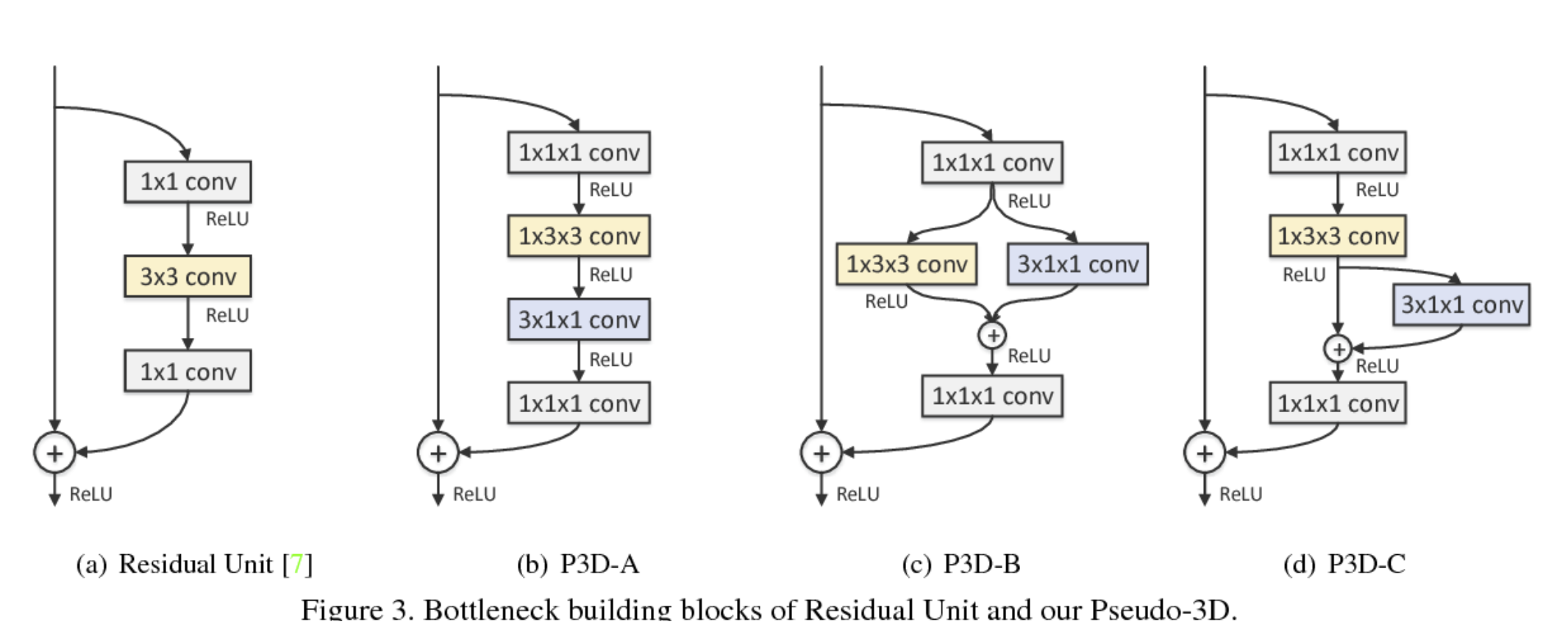
P3D
[ caffe ] https://github.com/ZhaofanQiu/pseudo-3d-residual-networks
[ pytorch ] https://github.com/jfzhang95/pytorch-video-recognition
Learning spatio-temporal representation with pseudo-3d residual networks. In ICCV, 2017.
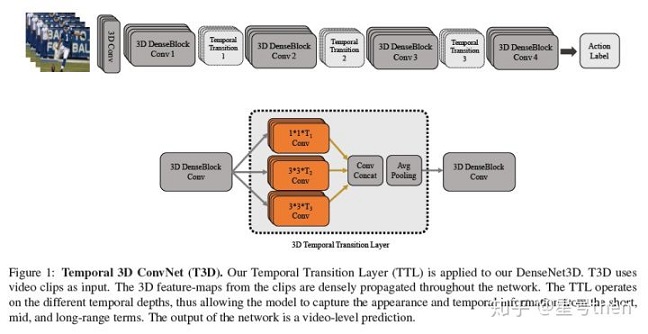
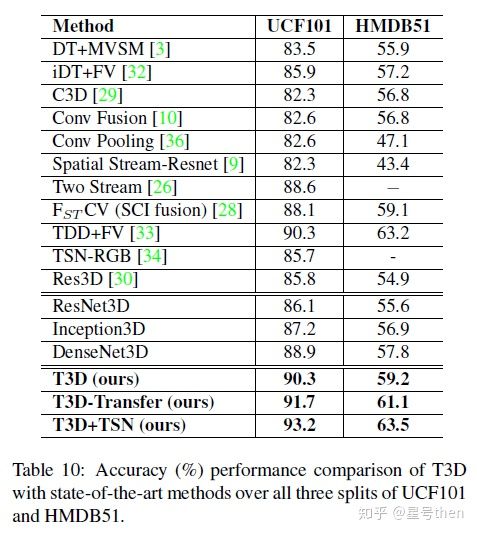
T3D*
Architecture: DenseNet + 3D
[ github pytorch] https://github.com/MohsenFayyaz89/T3D
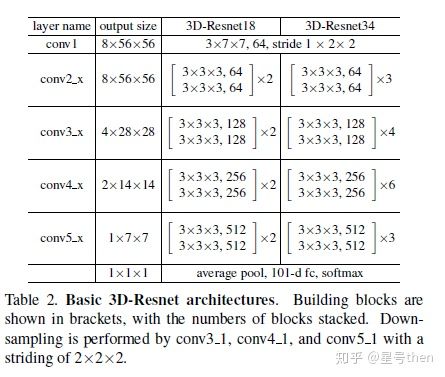
Res3D/R3D
architecture: ResNet + 3DConv
[github pytorch] https://github.com/jfzhang95/pytorch-video-recognition
R2.5D
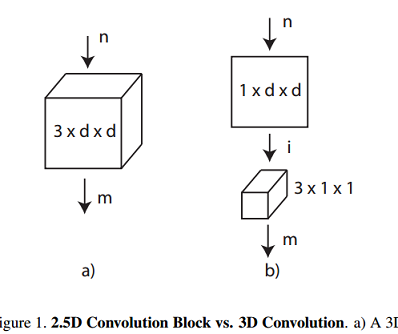
R2+1D
[ offical video model zoo (caffe2) ] https://github.com/facebookresearch/VMZ
[ github PyTorch] https://github.com/leftthomas/R2Plus1D-C3D
[ github pytorch] https://github.com/jfzhang95/pytorch-video-recognition
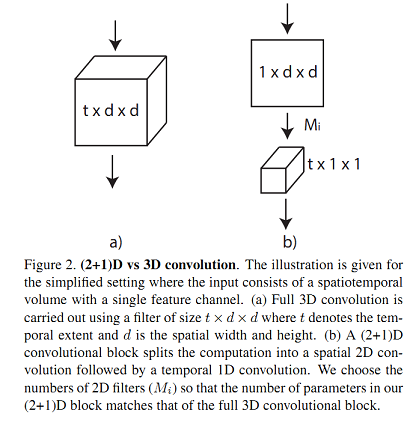
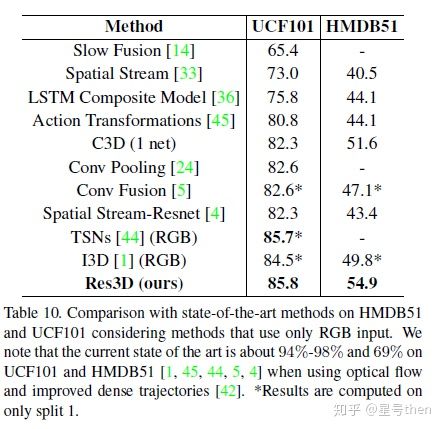
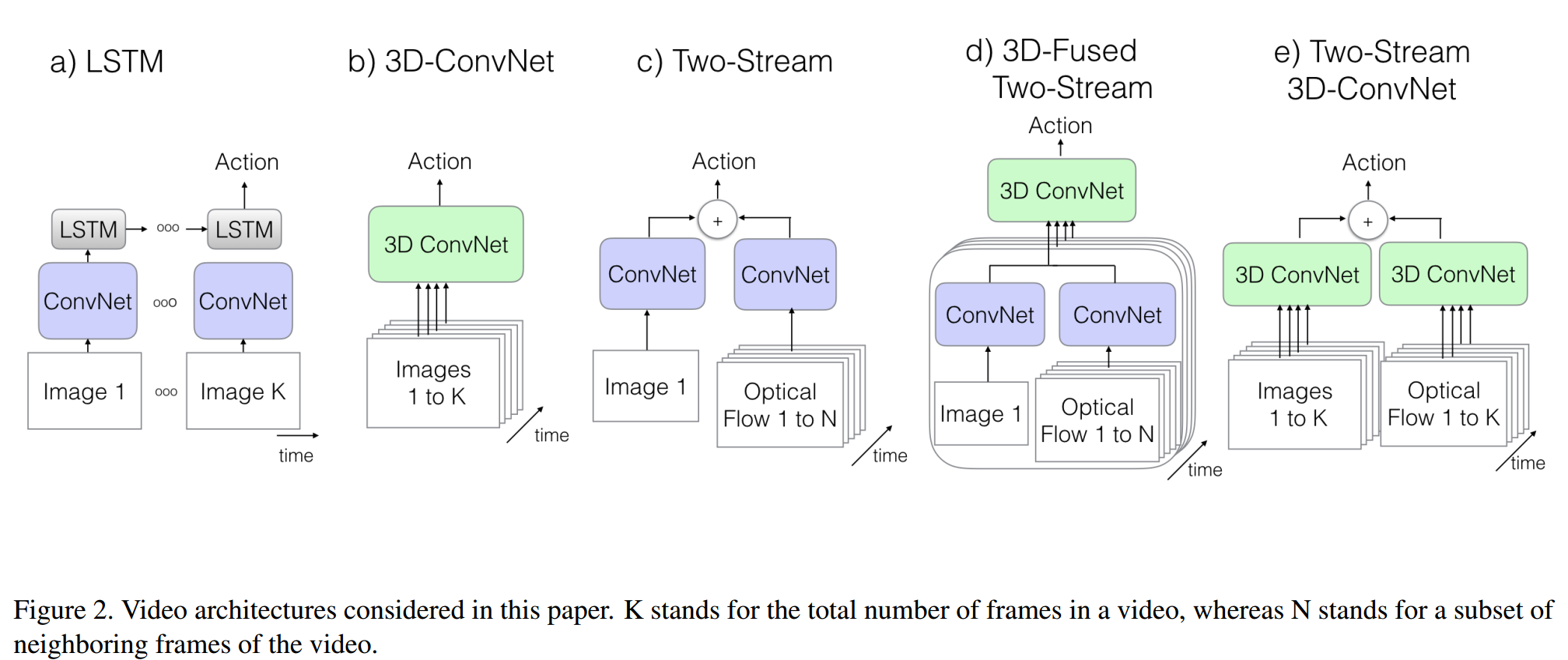
R3DCNN
[NVIDIA]https://research.nvidia.com/sites/default/files/publications/NVIDIA_R3DCNN_cvpr2016.pdf
[tensorflow ]https://github.com/breadbread1984/R3DCNN
[tensorflow ] https://github.com/kilsenp/R3DCNN-tensorflow
architecture: C3D + RNN
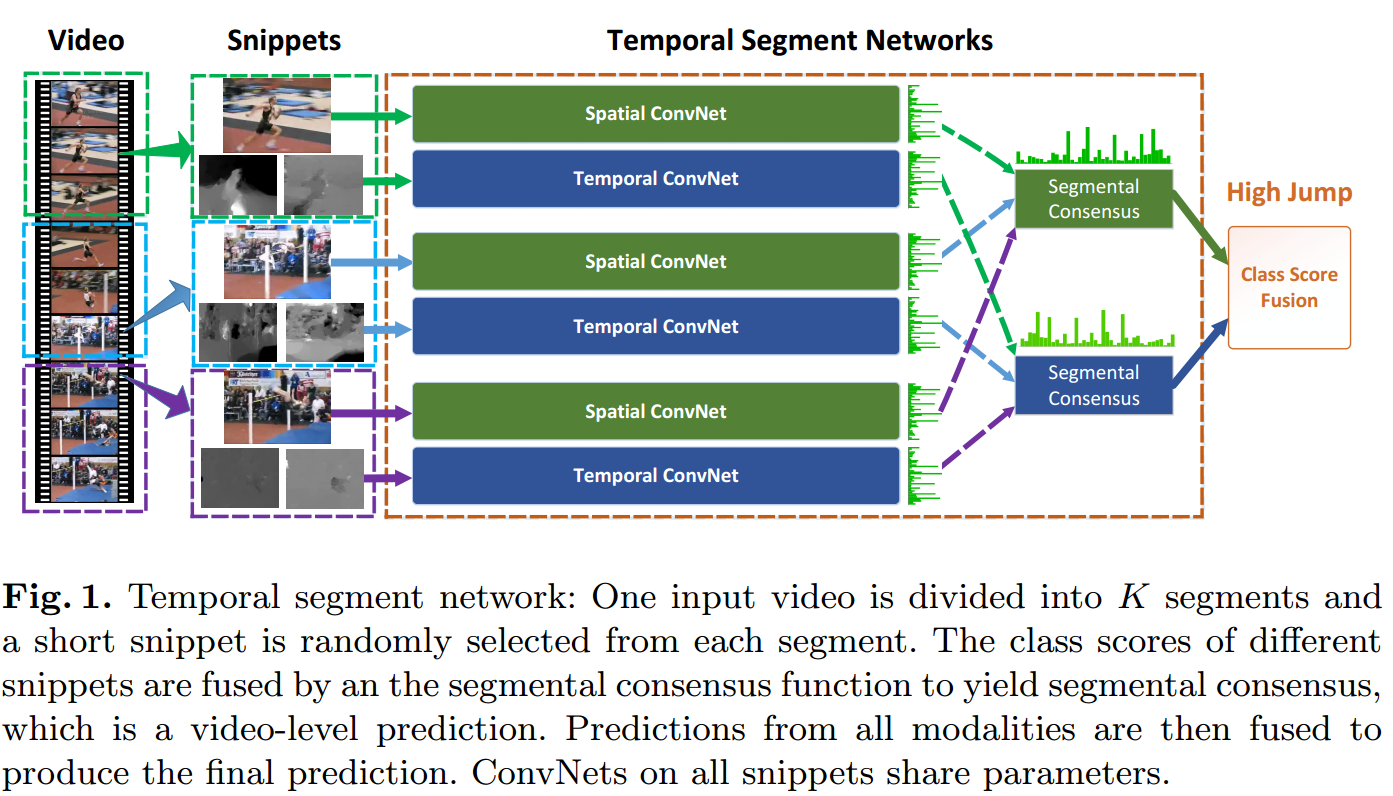
TSN
[github caffe ] https://github.com/yjxiong/temporal-segment-networks
[ caffe opensource ] https://github.com/yjxiong/caffe
[Paper] https://arxiv.org/pdf/1608.00859.pdf
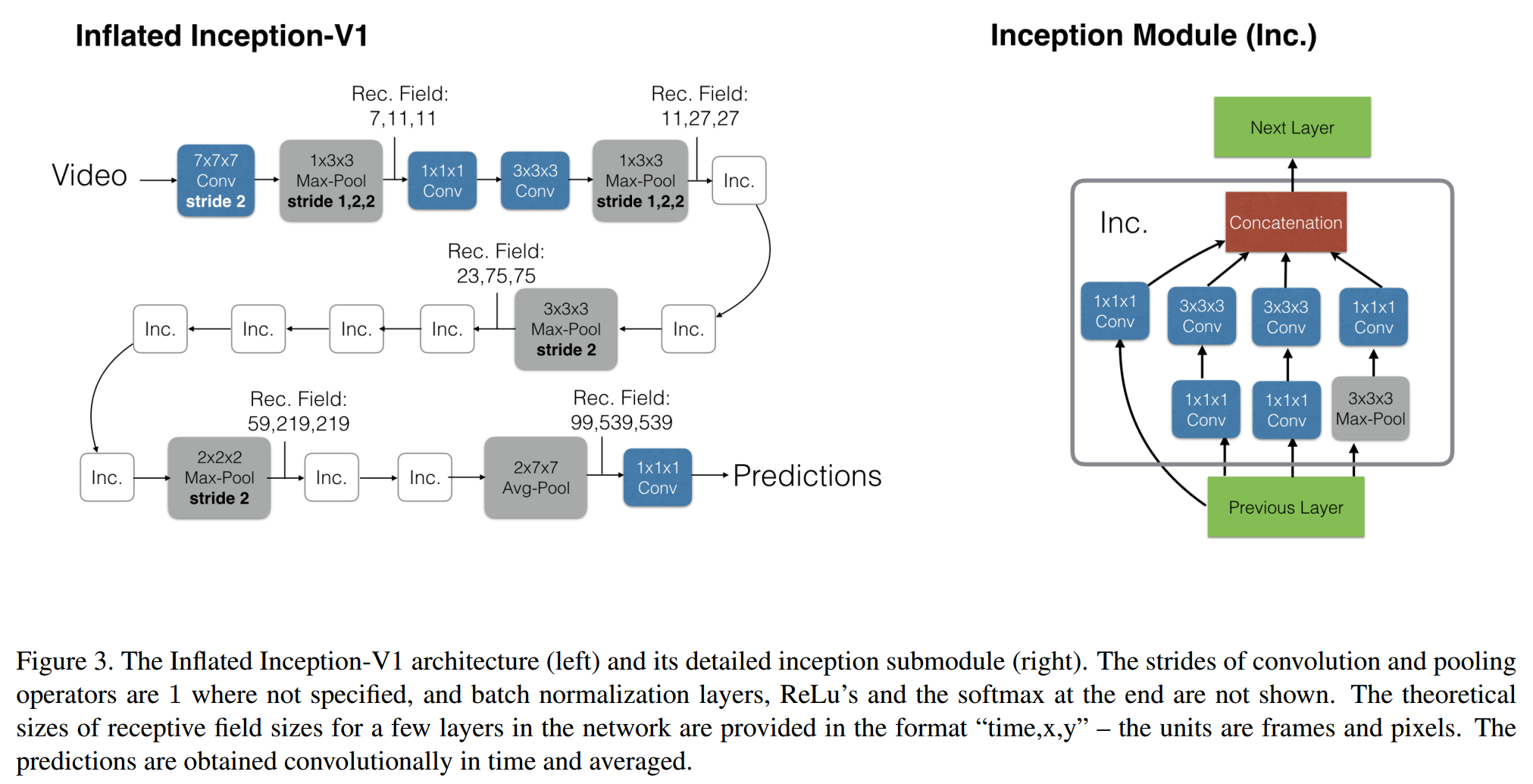
I3D
Architecture: Inception base
[git keras ] https://github.com/OanaIgnat/i3d_keras
[Paper ] https://arxiv.org/pdf/1705.07750.pdf
END
手工特征提取方法(iDT)
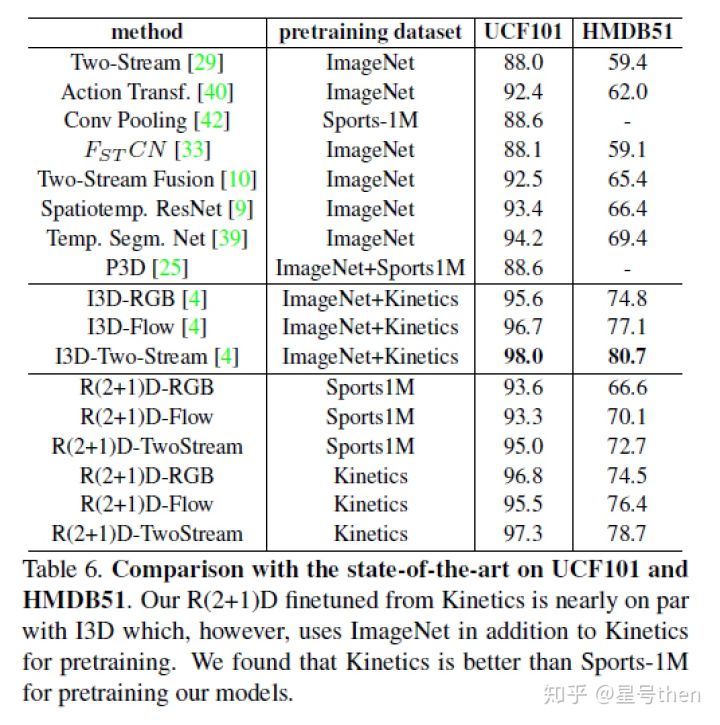
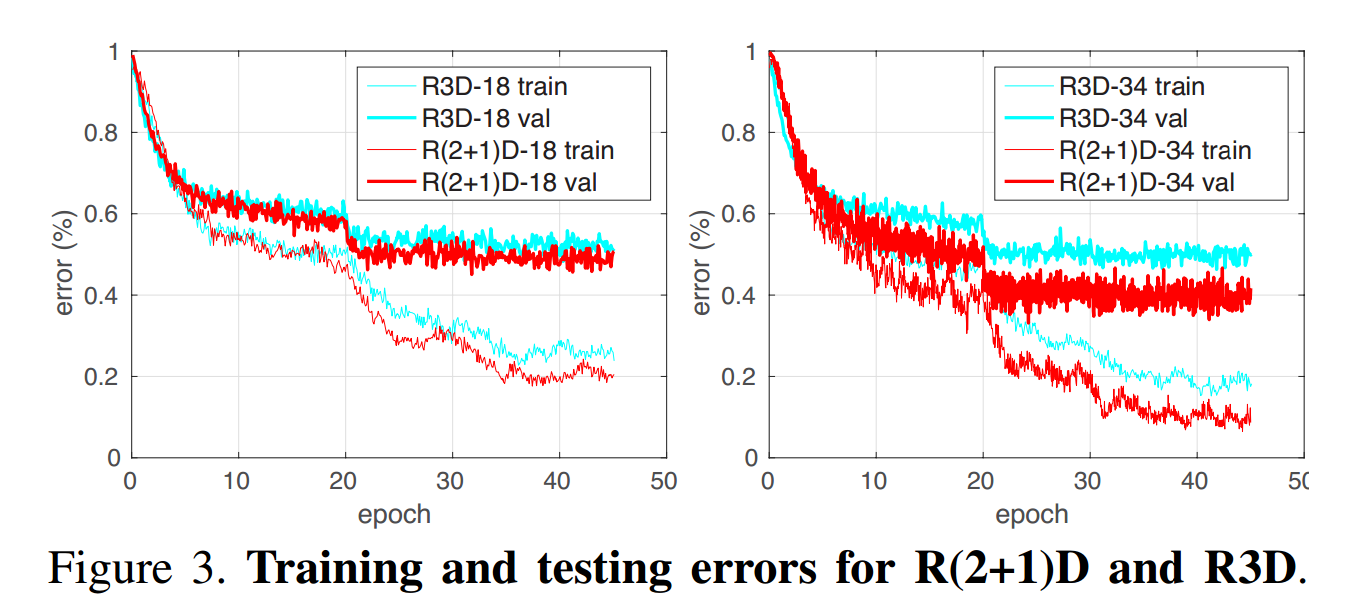
R2+1D的错误率比R3D的更小(约0.2个百分点)
3D-Conv 的适用场景:视频识别,图像识别
UCF100
C3D-: 82.3% or 82-90%
P3D:
T3D: 90-93%
R3D-: 85.8%
R21D:
model_blocktype = {
‘r2plus1d’: ‘2.5d’,
‘r3d’: ‘3d’,
‘ir-csn’: ‘3d-sep’,
‘ip-csn’: ‘0.3d’
}
reference
论文笔记——基于的视频行为识别/动作识别算法笔记(三) https://zhuanlan.zhihu.com/p/41659502
[1]. D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning spatiotemporal features with 3d convolutional networks. In ICCV, 2015. 1, 2, 3, 7
[2]. Z. Qiu, T. Yao, , and T. Mei. Learning spatio-temporal representation with pseudo-3d residual networks. In ICCV, 2017. 1, 2, 4, 7, 8
[3]. A. Diba, M. Fayyaz, V. Sharma, AH. Karami, MM Arzani. Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification. arXiv:1711.08200v1, 22 Nov 2017
[4]. [Res3D/R3D] T. Du, J. Ray, S. Zheng, SF. Chang, M. Paluri. ConvNet Architecture Search for Spatiotemporal Feature Learning. arXiv:1708.05038v1 16 Aug 2017
[5]. T. Du, H. Wang, L. Torresani, J. Ray, Y.Lecun. A Closer Look at Spatiotemporal Convolutions for Action Recognition. arXiv:1711.11248v3 12 Apr 2018
J. Carreira and A. Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In CVPR, 2017. 1, 3, 5, 7, 8