[TOC]
Conv网络结构,任务 资源汇总
1.4k awesome-image-classification
8.6k deep_learning_object_detection
21.7k awesome-deep-learning-papers
1.4k imgclsmob - Convolutional neural networks for computer vision
超分辨
2020 Face Super-Resolution Guided by 3D Facial Priors
Awesome - Image Classification
| ConvNet | ImageNet top1 acc | ImageNet top5 acc | Published In |
|---|---|---|---|
| VGG | 76.3 | 93.2 | ICLR2015 |
| GoogleNet | - | 93.33 | CVPR2015 |
| PReLU-nets | - | 95.06 | ICCV2015 |
| ResNet | - | 96.43 | CVPR2015 |
| Inceptionv3 | 82.8 | 96.42 | CVPR2016 |
| Inceptionv4 | 82.3 | 96.2 | AAAI2016 |
| Inception-ResNet-v2 | 82.4 | 96.3 | AAAI2016 |
| Inceptionv4 + Inception-ResNet-v2 | 83.5 | 96.92 | AAAI2016 |
| ResNext | - | 96.97 | CVPR2017 |
| PolyNet | 82.64 | 96.55 | CVPR2017 |
| NasNet | 82.7 | 96.2 | CVPR2018 |
| MobileNetV2 | 74.7 | - | CVPR2018 |
| PNasNet | 82.9 | 96.2 | ECCV2018 |
| AmoebaNet | 83.9 | 96.6 | arXiv2018 |
| SENet | - | 97.749 | CVPR2018 |
ResNet
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
- pdf: https://arxiv.org/abs/1512.03385
- code: facebook-torch : https://github.com/facebook/fb.resnet.torch
- code: torchvision : https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
- code: keras-applications : https://github.com/keras-team/keras-applications/blob/master/keras_applications/resnet.py
- code: unofficial-keras : https://github.com/raghakot/keras-resnet
- code: unofficial-tensorflow : https://github.com/ry/tensorflow-resnet
Inceptionv3
Rethinking the Inception Architecture for Computer Vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew Wojna
- pdf: https://arxiv.org/abs/1512.00567
- code: torchvision : https://github.com/pytorch/vision/blob/master/torchvision/models/inception.py
- code: keras-applications : https://github.com/keras-team/keras-applications/blob/master/keras_applications/inception_v3.py
Inceptionv4
Inception-ResNet-v2
Inceptionv4 + Inception-ResNet-v2
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi
- pdf: https://arxiv.org/abs/1602.07261
- code: unofficial-keras : https://github.com/kentsommer/keras-inceptionV4
- code: unofficial-keras : https://github.com/titu1994/Inception-v4
- code: unofficial-keras : https://github.com/yuyang-huang/keras-inception-resnet-v2
ResNext
Aggregated Residual Transformations for Deep Neural Networks
Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He
- pdf: https://arxiv.org/abs/1611.05431
- code: official : https://github.com/facebookresearch/ResNeXt
- code: keras-applications : https://github.com/keras-team/keras-applications/blob/master/keras_applications/resnext.py
- code: unofficial-pytorch : https://github.com/prlz77/ResNeXt.pytorch
- code: unofficial-keras : https://github.com/titu1994/Keras-ResNeXt
- code: unofficial-tensorflow : https://github.com/taki0112/ResNeXt-Tensorflow
- code: unofficial-tensorflow : https://github.com/wenxinxu/ResNeXt-in-tensorflow
PolyNet
PolyNet: A Pursuit of Structural Diversity in Very Deep Networks
Xingcheng Zhang, Zhizhong Li, Chen Change Loy, Dahua Lin
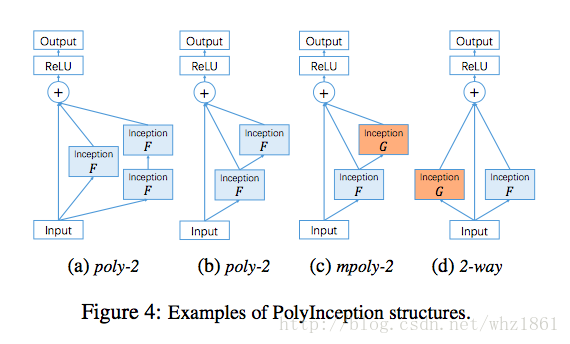
NasNet
Learning Transferable Architectures for Scalable Image Recognition
Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le
- pdf: https://arxiv.org/abs/1707.07012
- code: unofficial-keras : https://github.com/titu1994/Keras-NASNet
- code: keras-applications : https://github.com/keras-team/keras-applications/blob/master/keras_applications/nasnet.py
- code: unofficial-pytorch : https://github.com/wandering007/nasnet-pytorch
- code: unofficial-tensorflow : https://github.com/yeephycho/nasnet-tensorflow
MobileNet
MobileNetV2
InvertedResidual: 是 MobileNetV2 架构中提出的一种创新结构设计
Linear Bottleneck Layer: 每个残差模块首先通过一个深度可分离卷积(Depthwise Separable Convolution)进行通道数压缩,形成所谓的线性瓶颈层。这个步骤减少了计算量和参数量。
Expansion Layer: 接着使用1x1的卷积来进行通道扩张,增加特征图的深度(即通道数),而非像常规残差块那样直接对输入进行操作。这样做的目的是为了在不增加过多计算负担的前提下增强网络的表达能力。
Depthwise Convolution: 扩展后的特征图再经过深度卷积操作,进行空间特征提取。
最后的 Projection Layer: 使用另一个1x1卷积将特征图的通道数还原至原始数量,然后与原始输入相加形成残差连接。
整个过程可以理解为一种”倒置”的残差模块,因为它先进行特征扩展再进行空间卷积,而不是通常的先空间卷积再特征映射。这样的设计既保留了残差网络的优点,又有效利用了深度可分离卷积的轻量化特性,从而实现了在有限计算资源下的高效模型设计。
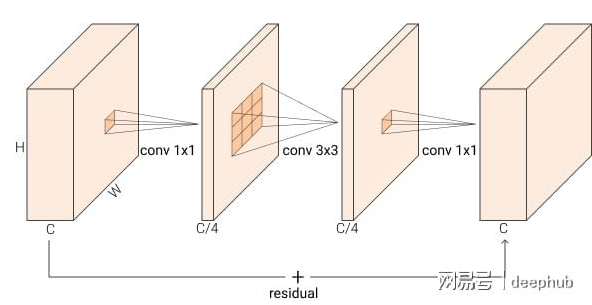
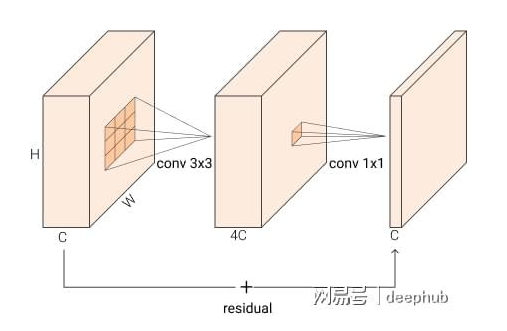
BottleNeck (Residual)
BxCxHxW —1x1-> BxC/4xHxW –3x3—> BxC/4xHxW –1x1–> BxCxHxW
( r=4)
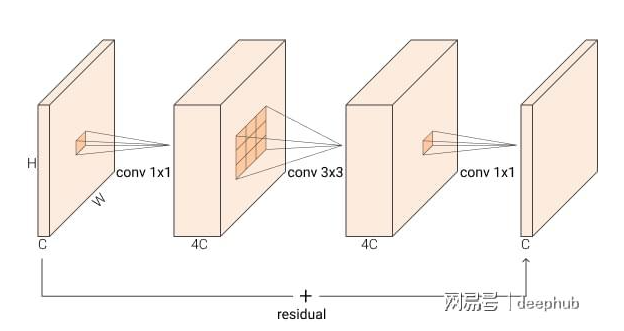
Inverted Residual :
BxCxHxW -> BxCexHxW -> BxCexHxW -> BxCxHxW; 其中 e 是膨胀比,默认设置为 4,而不是像正常的瓶颈块那样变宽 -> 窄 -> 宽,他们做相反的事情 窄 -> 宽 -> 窄。
Fused Inverted Residuals:
PNasNet
Progressive Neural Architecture Search
Chenxi Liu, Barret Zoph, Maxim Neumann, Jonathon Shlens, Wei Hua, Li-Jia Li, Li Fei-Fei, Alan Yuille, Jonathan Huang, Kevin Murphy
- pdf: https://arxiv.org/abs/1712.00559
- code: tensorflow-slim : https://github.com/tensorflow/models/blob/master/research/slim/nets/nasnet/pnasnet.py
- code: unofficial-pytorch : https://github.com/chenxi116/PNASNet.pytorch
- code: unofficial-tensorflow : https://github.com/chenxi116/PNASNet.TF
AmoebaNet
Regularized Evolution for Image Classifier Architecture Search
Esteban Real, Alok Aggarwal, Yanping Huang, Quoc V Le
- pdf: https://arxiv.org/abs/1802.01548
- code: tensorflow-tpu : https://github.com/tensorflow/tpu/tree/master/models/official/amoeba_net
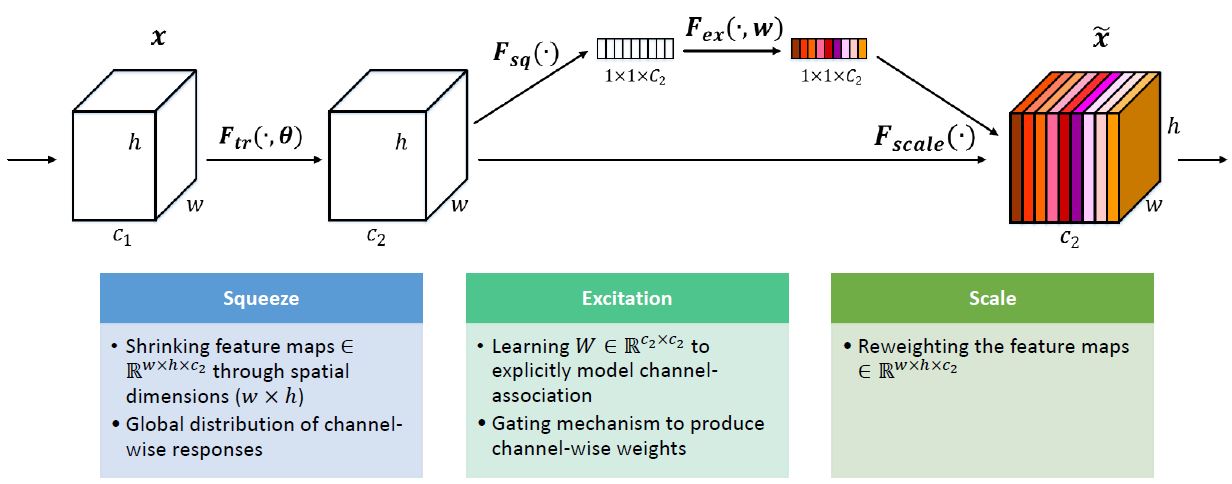
SENet
Squeeze-and-Excitation Networks
Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu
- pdf: https://arxiv.org/abs/1709.01507
- code: official : https://github.com/hujie-frank/SENet
- code: unofficial-pytorch : https://github.com/moskomule/senet.pytorch
- code: unofficial-tensorflow : https://github.com/taki0112/SENet-Tensorflow
- code: unofficial-caffe : https://github.com/shicai/SENet-Caffe
- code: unofficial-mxnet : https://github.com/bruinxiong/SENet.mxnet
| SE-Incetion | SE-ResNet |
|---|---|
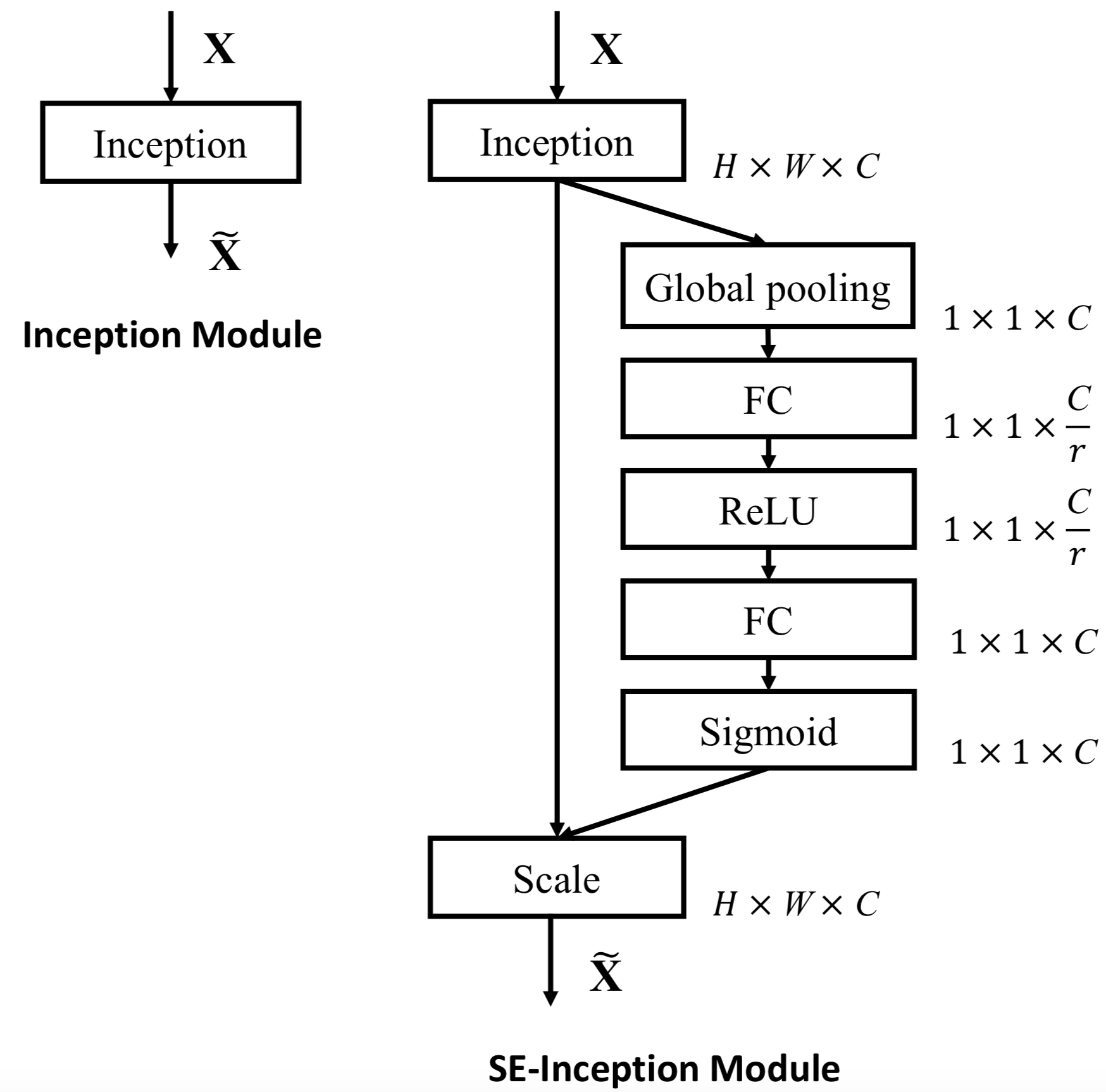 |
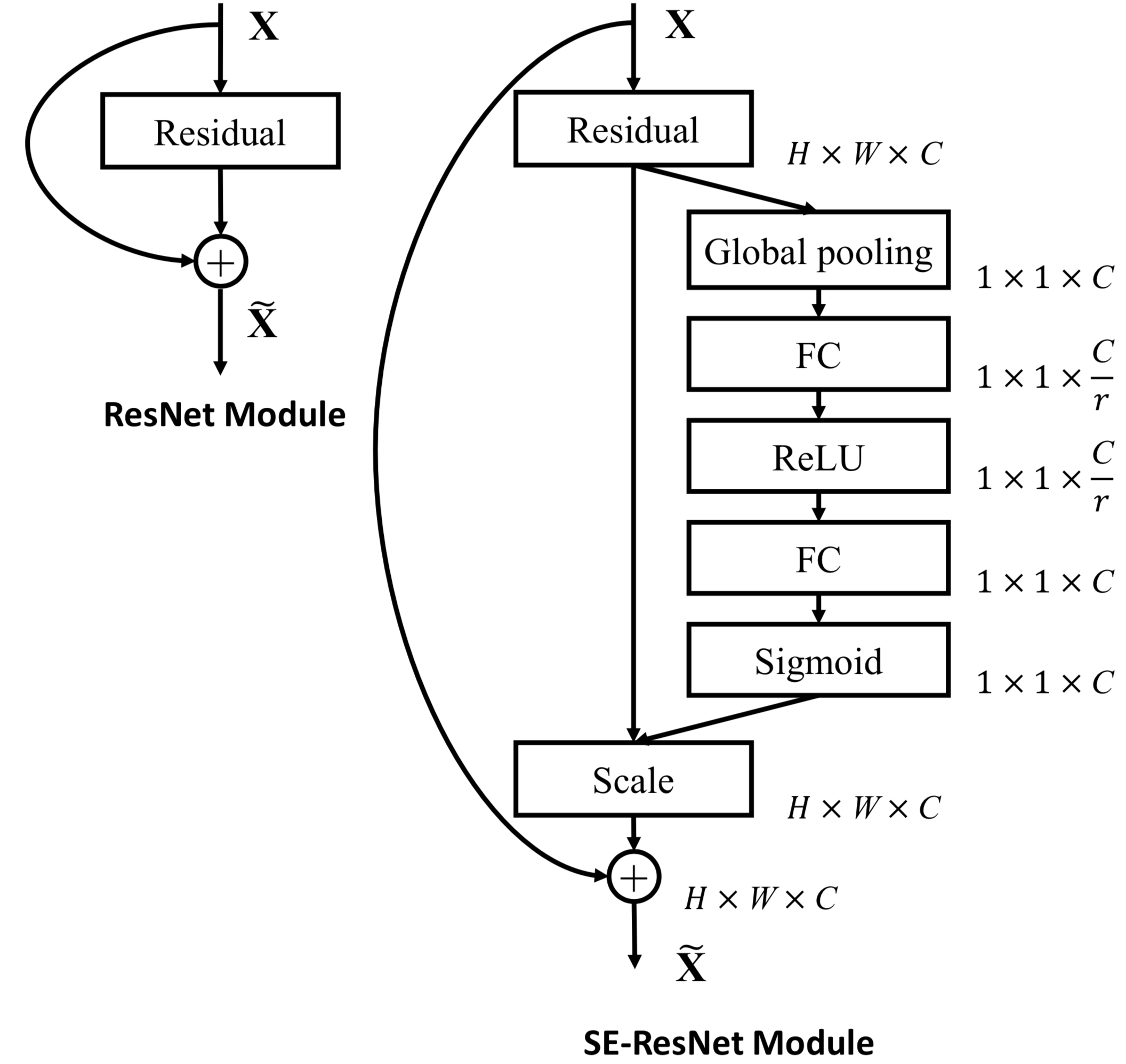 |
Transformer
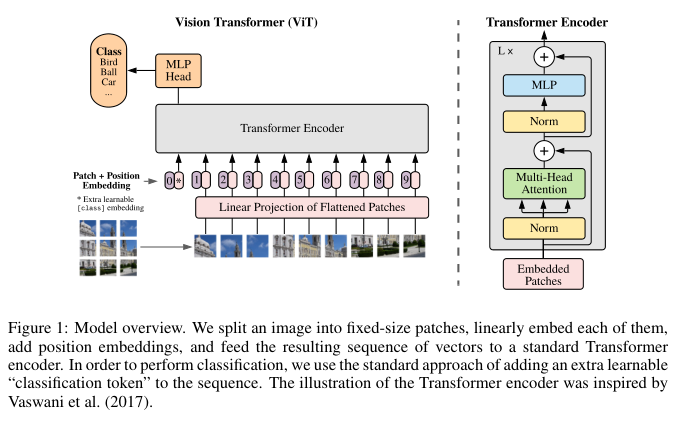
ViT(Vision Transformer)
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
组合PatchEmbedding、TransformerEncoder 和 ClassificationHead创建最终的ViT架构。