[toc]
on-policy:
off-policy:
基于模型:动态规划
无模型解决方案:TD, MC,
概率模型:
贝叶斯强化学习
部分可观察马尔可夫决策过程(POMDP)
PAC-MDP ( 马尔可夫决策过程学习 )
SEED RL: Scalable, EfficientDeep-RL,每秒处理数百万张图片的分布式强化学习框架。
概念解析
人工智能
- 学派
- 符号主义:逻辑推断,贝叶斯学习
- 连结主义:神经网络
- 行为主义:控制论和强化学习
- 机器学习-广义分类
- 监督学习
- 无监督学习
- 强化学习
on-policy off-policy
on-policy 与 off-policy的本质区别在于:更新Q值时所使用的方法是沿用既定的策略(on-policy)还是使用新策略(off-policy)。
在Sarsa中更新Q函数时用的A就是贪婪策略得出来的,下一回合也用的是这个A去进行step。两个A一定相同就是(同策略)on-policy。
但是在Q_learning中,更新时的a时Qmax得到的,而下一回合的A是用贪婪策略(在更新后的Qmax基础上有探索)得到的,这时的a和A就有可能不一样,就是(异策略)off-policy。
算法Survey
马尔可夫决策过程MDP
一个马尔科夫决策过程MDP由可能的状态集合S、动作集合A、状态转移函数P和即时回报函数R组成一个四元组M=(S,A,P,R);给定一个MDP,强化学习的任务是找到一个策略(确定性或非确定性),能够获得最大的期望累计回报,为了使回报有界,通常引入一个衰减因子(Discount Favtor) γ∈(0,1)或决策深度(Horizon) T>0,此时学习目标可以表示为找到最优控制策略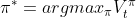 。
。
更高样本效率的探索策略
随机探索策略
在agent选择动作时故意加入随机性,例如ꜫ-greedy,以1-ꜫ选择当前估值最高动作,以ꜫ概率从可能动作中按照均匀分布随机选择。Boltzmann selection探索策略也是按照一定概率分布选择动作,当前估计价值越高的动作被选中的机会越多。
系统性探索策略
尝试评估当前信息匮乏程度以及这种匮乏导致的价值估计的不确定性大小,综合考虑当前估计价值与不确定性来进行选择。一些系统性探索策略遵循“乐观策略”,即在对价值进行估计时,如果当前相关数据较少而信息不足,那就故意将此价值高估,让智能体相信相应决策会带来良好效果,促使它去选择这些具有较高不确定性的动作,随着数据量增加,信息变得充分,这种高估程度也就逐渐降低。当算法最终认定一个动作不具有高度价值而决定不再选择该动作时,由于已经有了足够多的数据,算法因错误判断价值而失去找出更好策略机会的可能性较小,这就保证了算法在最坏情况下也具有较好的样本效率。例如R-MAX、MBIE、UCRL。
PAC(Probably Approximately Correct,高度近似正确)学习理论是比较成熟的样本效率分析理论体系,PAC理论又称PAC-MDP理论,主要分析在一个无限长的学习过程中学习算法选择非最优动作的次数,称为该算法的样本复杂度。如果一个算法的样本复杂度有上界,那就说明该算法无论面对如何困难的学习问题,都能在无限长的学习过程中只犯有限次的“失误”,从而间接说明算法的样本效率较高。除PAC外,还要Regret分析、KWIK分析、平均损失分析等,从不同指标分析了一些系统性探索策略的样本效率,指出了它们的有效性。
A3C
GA3C
GPU-based Asynchronous Advantage Actor-Critic是A3C的GPU实现。
A3C的内容可见并行强化学习算法:A2C/A3C,A3C的每一个Worker都需要采样、训练,需要充足的CPU资源。GPU有很强的并行计算优势;直觉上,将学习计算部分挪到GPU,收集数据环境交互部分放到CPU,会使系统更紧凑高效,同时也能匹配其他深度学习任务的硬件架构。
学习过程
1,整体采用的是批处理策略,即缓存到达batch size后统一处理;2,每个Agent(Worker)负责收集数据(s, a, r, s’),注册到队列Training Queue,由Trainer管理供以后训练使用;3,但Agent不负责采样本身π(a|s),而是将需求注册到队列Prediction Queue,由Predictor管理;4,Predictor是个While True Thread,当缓存到达其batch size后,调用GPU上的策略预测网络π(a|s)进行采样;5,类似地,Trainer也是个While True Thread,满足batch size后调用GPU进行训练。
注意点
1,模型网络只有一套,存储在GPU上;2,就是说,每一次采样,都使用即时的网络参数;3,模型训练期间,也同时在采样,难免会出现采样时的policy网络参数与最后学习时的参数不一致,所以GA3C部分数据有一定的延迟,不是严格的on-policy;4,具体得看训练的batch size及当时GPU状态,GPU算力资源充足、batch size合理的情况下,受影响的数据应该是很少的。
SEED RL
基本架构:
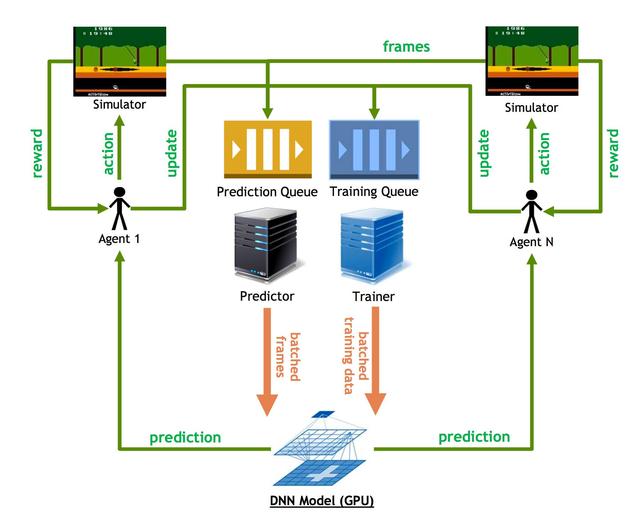
Actor
Learner
基本结构与GA3C相似
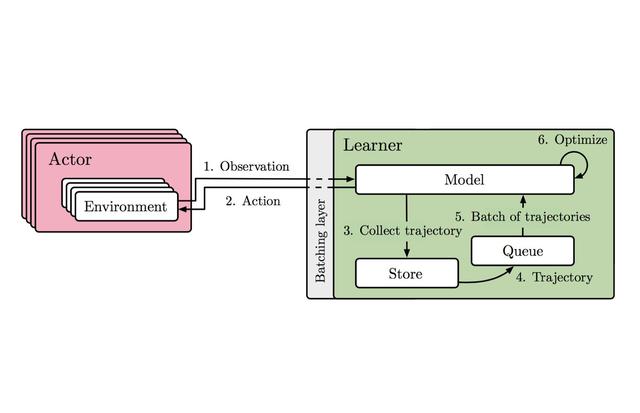
学习过程
- 整体采用批处理机制,批量采样、批量学习。
- Inference thread是While True Thread,负责生成π(a|s)并保存trajectories (s, a, r, s’)。
- Data prefetching也是While True Thread,当trajectories完成时,通过quene存入replay buffer。
- Training thead也是While True Thread,通过Device Buffer进行批量学习。
总结
- 与GA3C相比,直接支持off-policy,而不是不时的数据延迟lag。
- 与IMPALA相比,Actor只专注环境交互,不再进行动作采样;网络参数只有一套,推理采样及学习都在Learner上。
- 与R2D2相比,Replay Buffer直接在Learner上,取消分布式优先经验回放机制。
- Actor与Learner采用gRPC通信,有效降低采样延迟。
- 每个Actor拥有多个环境Environments,提高吞吐量,高效利用CPUs和GPU。Actor与Learner不需要传输完整的Experience,降低带宽,有利于更大规模扩展。