NVlab
[TOC]
VAE生成模型
Variational autoencoder == 变分自编码器
可以输入一个低维空间的Z,映射到高维空间的真实数据。比如,生成不同样的数字,人脸,卡通头像等等。
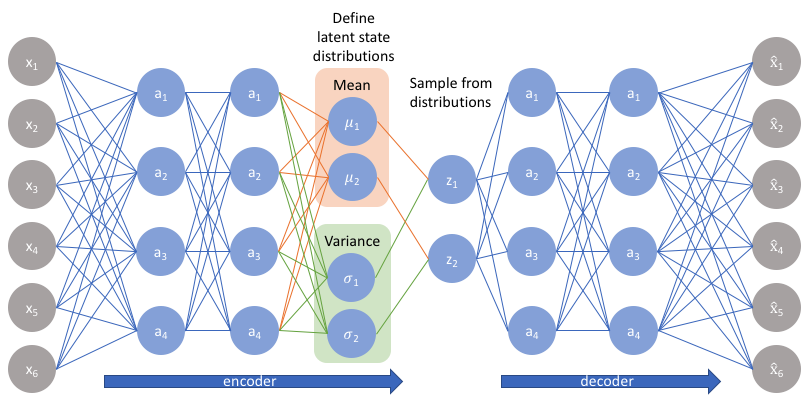
2)VAE与GAN之间的差异性
既然VAE与GAN都是属于最近很火的生成网络序列,那么他们之间有什么不同呢?
假设,给定一系列猫的照片,我希望你能够对应我随机输入的一个n维向量,生成一张新的猫的照片,你需要怎么去做?对于GAN就是典型的深度学习时代的逻辑,你不是不清楚这个n维向量与猫的图片之间的关系嘛,没关系,我直接拟合出来猫的图片对于n维向量的分布,通过对抗学习的方式获得较好的模型效果,这个方法虽然很暴力,但是却是有效的。(暴力求解)
VAE则不同,他通过说我希望生成一张新的猫脸,那么这个n维向量代表的就是n个决定最终猫脸模样的隐形因素。对于每个因素,都对应产生一种分布,从这些分布关系中进行采样,那么我就可以通过一个深度网络恢复出最终的猫脸。VAE相比较于GAN它的效果往往会略微模糊一点,但是也不失为一种良好的解决方案。并且相对于GAN的暴力求解,VAE的建模思路无疑要复杂的多,它更能体现理科思维的艺术感。
https://blog.csdn.net/weixin_40955254/article/details/82315224 — Good
VAE是直接计算生成图片和原始图片的均方误差
GAN 对抗来学习
https://antkillerfarm.github.io/gan%20&%20vae/2019/05/05/VAE_3.html
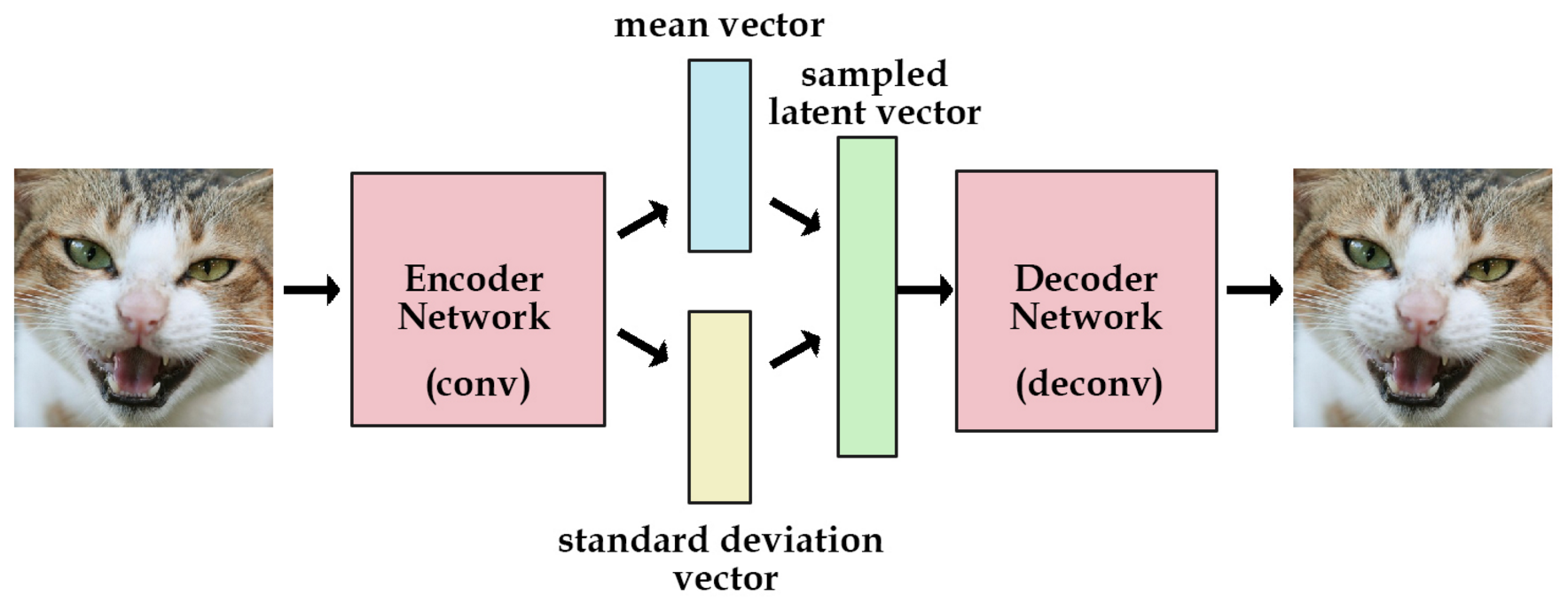
不像标准自编码器那样产生实数值向量,VAE的编码器会产生两个向量:一个是均值向量,一个是标准差向量。
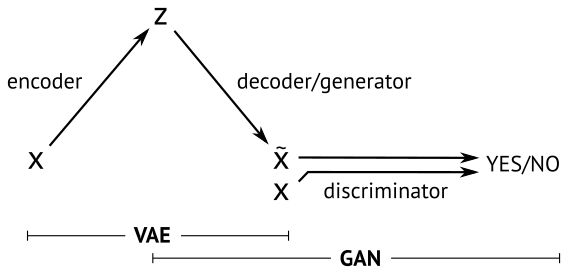
可以通过编码解码的步骤,直接比较重建图片和原始图片的差异,但是GAN做不到。
https://www.cnblogs.com/huangshiyu13/p/6209016.html
GAN生成模型
Generative Adversarial Nets
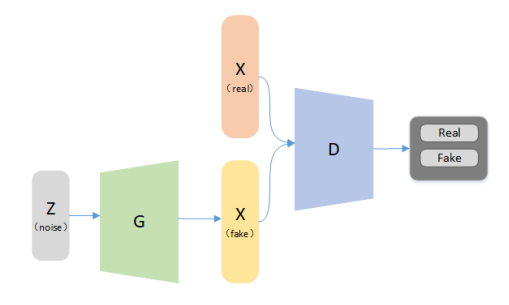
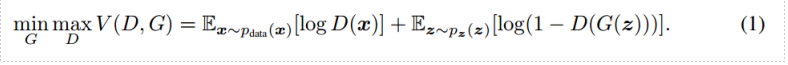
从判别器 D 的角度看,它希望自己能尽可能区分真实样本和虚假样本,因此希望 D(x) 尽可能大,D(G(z)) 尽可能小, 即 V(D,G)尽可能大。从生成器 G 的角度看,它希望自己尽可能骗过 D,也就是希望 D(G(z)) 尽可能大,即 V(D,G) 尽可能小。两个模型相对抗,最后达到全局最优。
从数据分布来说,就是开始的噪声noise,在G不断修正后,产生的分布,和目标数据分布达到一致:
cGAN(Conditional GAN)
- MG-VTON 采用了此技术
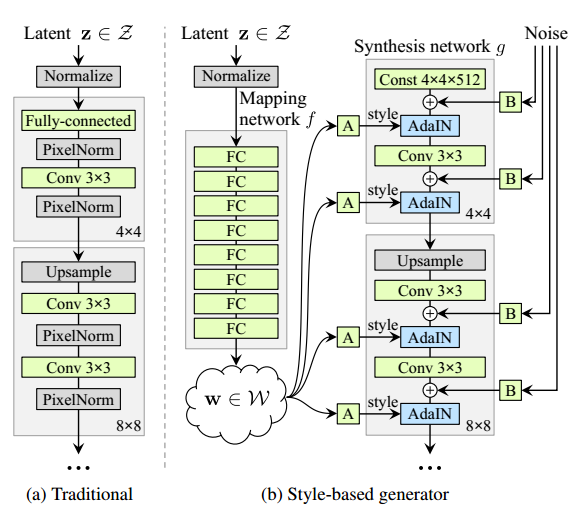
StyleGAN
A Style-Based Generator Architecture for Generative Adversarial Networks
https://github.com/NVlabs/stylegan
https://arxiv.org/abs/1812.04948
网络架构
Custom Date
准备好数据集
把数据集储存为多重分辨率的Tfrecords
数据集表示为一个目录,里面的每张图像都有多种不同的分辨率,用于高效的streaming。每个分辨率都有一个自己的*.tfrecords文件。数据有标注的话,也是用一个分开的文件来储存的。
1> python dataset_tool.py create_lsun datasets/lsun-bedroom-full ~/lsun/bedroom_lmdb --resolution 256 2> python dataset_tool.py create_lsun_wide datasets/lsun-car -512x384 ~/lsun/car_lmdb --width 512--height 384 3> python dataset_tool.py create_lsun datasets/lsun-cat-full ~/lsun/cat_lmdb --resolution 256 4> python dataset_tool.py create_cifar10 datasets/cifar10 ~/cifar10 # 自定义 5> python dataset_tool.py create_from_images datasets/custom-dataset ~/custom-images
训练
官方提供的训练过程分四步:
1.编辑train.py,通过取消注释或者修改某些行,来指定数据集和训练配置;
2.用train.py来运行训练脚本;
3.结果会写在一个新目录里,叫results/ - ;
4.训练直至完成,几天时间可能是要的。
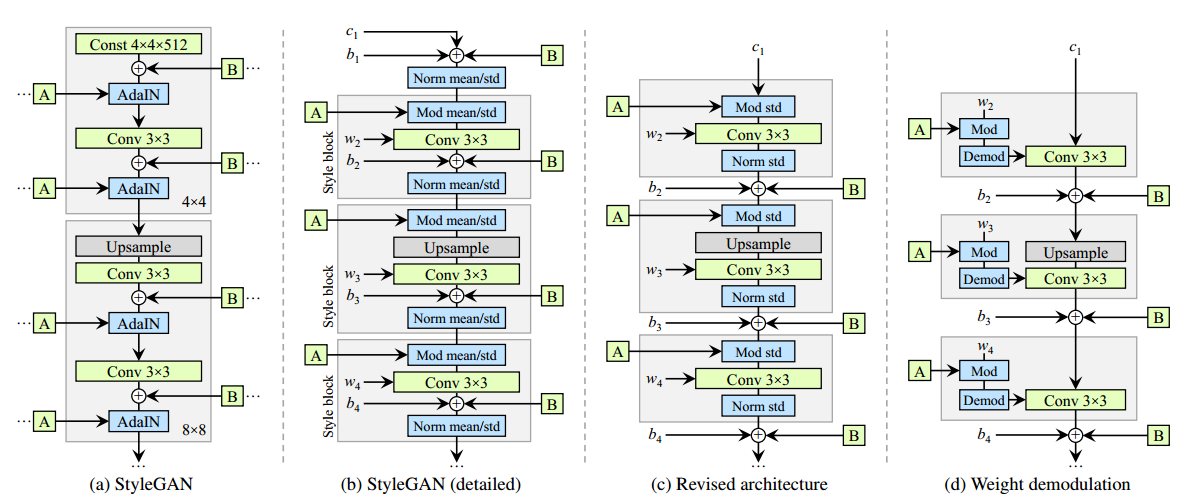
StyleGAN2
Analyzing and Improving the Image Quality of StyleGAN
https://github.com/NVlabs/stylegan2
https://arxiv.org/abs/1912.04958
StyleGAN2 Google Colab Example
网络结构:
数据集(origin)
https://github.com/NVlabs/ffhq-dataset
| Path | Size | Files | Format | Description |
|---|---|---|---|---|
| ffhq-dataset | 2.56 TB | 210,014 | Main folder | |
| ├ ffhq-dataset-v2.json | 255 MB | 1 | JSON | Metadata including copyright info, URLs, etc. |
| ├ images1024x1024 | 89.1 GB | 70,000 | PNG | Aligned and cropped images at 1024×1024 (同in-the-wild-image, 大小统一格式化) |
| ├ thumbnails128x128 | 1.95 GB | 70,000 | PNG | Thumbnails at 128×128 |
| ├ in-the-wild-images | 955 GB | 70,000 | PNG | Original images from Flickr(Human top) |
| ├ tfrecords | 273 GB | 9 | tfrecords | Multi-resolution data for StyleGAN and StyleGAN2 |
| └ zips | 1.28 TB | 4 | ZIP | Contents of each folder as a ZIP archive. |
数据集合(baiduYUN):
| images1024x1024 | 链接:https://pan.baidu.com/s/1Tdu2G2E8PLKsLnICUi13EQ 提取码:jtjv |
|
参考资料: ffhq-dataset(images1024x1024)
相关Blog
1、零成本体验StyleGAN2:
style gan论文翻译
Colab代码直接使用,细节逼真难以分辨 https://www.jiqizhixin.com/articles/2019-12-21-3
2、StyleGAN效果图
用StyleGAN风格迁移模型生成人脸 https://www.jianshu.com/p/c728a7cc1a6b
 |
||
 |
||
 |
3、StyleGAN 人脸生成器(网红脸)
http://www.gwylab.com/download.html
https://mp.weixin.qq.com/s/T9i7Pr054YylB3SI0k_88A 超模脸、网红脸、萌娃脸…换头像不重样?我开源了5款人脸生成器