[TOC]
np初始化
np.arange()
np.random
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
x=np.random.randn(3,5)
print(x)
x=np.random.rand(2,4)
print(x)
x=np.random.randint(1,11,(3,4))
y=np.random.randint(10)
print("x:",x)
print("y:",y)
x: [[9 2 4 6]
[1 3 7 7]
[8 5 5 5]]
y: 3
x=np.random.choice(5, 3, replace=False, p=[0.1, 0, 0.3, 0.6, 0])
np.random.random()
np.random.seed()
np.random.normal
|
np.meshgrid()
生成网格点坐标矩阵
np.eye()
函数的原型:numpy.eye(N,M=None,k=0,dtype=<class ‘float’>,order=’C)
返回的是一个二维2的数组(N,M),对角线的地方为1,其余的地方为0.
参数介绍:
(1)N:int型,表示的是输出的行数
(2)M:int型,可选项,输出的列数,如果没有就默认为N
(3)k:int型,可选项,对角线的下标,默认为0表示的是主对角线,负数表示的是低对角,正数表示的是高对角。
(4)dtype:数据的类型,可选项,返回的数据的数据类型
(5)order:{‘C’,‘F’},可选项,也就是输出的数组的形式是按照C语言的行优先’C’,还是按照Fortran形式的列优先‘F’存储在内存中
案例:(普通的用法)
1
2
3
4
5
6
7
8
9
10
11
12
13
| import numpy as np
a=np.eye(3)
print(a)
a=np.eye(4,k=1)
print(a)
a=np.eye(4,k=-1)
print(a)
a=np.eye(4,k=-3)
print(a)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| [[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
[[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]
[0. 0. 0. 0.]]
[[0. 0. 0. 0.]
[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]]
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[1. 0. 0. 0.]]
|
高级用法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| import numpy as np
labels=np.array([[1],[2],[0],[1]])
print("labels的大小:",labels.shape,"\n")
a=np.eye(3)[1]
print("如果对应的类别号是1,那么转成one-hot的形式",a,"\n")
a=np.eye(3)[2]
print("如果对应的类别号是2,那么转成one-hot的形式",a,"\n")
a=np.eye(3)[1,0]
print("1转成one-hot的数组的第一个数字是:",a,"\n")
a=np.eye(3)[[1,2,0,1]]
print("如果对应的类别号是1,2,0,1,那么转成one-hot的形式\n",a)
res=np.eye(3)[labels.reshape(-1)]
print("labels转成one-hot形式的结果:\n",res,"\n")
print("labels转化成one-hot后的大小:",res.shape)
labels的大小: (4, 1)
如果对应的类别号是1,那么转成one-hot的形式 [0. 1. 0.]
如果对应的类别号是2,那么转成one-hot的形式 [0. 0. 1.]
1转成one-hot的数组的第一个数字是: 0.0
如果对应的类别号是1,2,0,1,那么转成one-hot的形式
[[0. 1. 0.]
[0. 0. 1.]
[1. 0. 0.]
[0. 1. 0.]]
labels转成one-hot形式的结果:
[[0. 1. 0.]
[0. 0. 1.]
[1. 0. 0.]
[0. 1. 0.]]
labels转化成one-hot后的大小: (4, 3)
|
np.identity()
这个函数和之前的区别在于,这个只能创建方阵,也就是N=M
函数的原型:np.identity(n,dtype=None)
参数:n,int型表示的是输出的矩阵的行数和列数都是n
dtype:表示的是输出的类型,默认是float
返回的是nxn的主对角线为1,其余地方为0的数组
1
2
3
4
5
6
7
8
9
| import numpy as np
a=np.identity(3)
print(a)
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
|
np.ravel()
np.expand_dims()
1
2
3
4
5
6
| import numpy as np
a = np.zeros((32,32))
print(a.shape)
a1 = np.expand_dims(a,0)
print(a1.shape)
>>> (32,32) (1,32,32)
|
方式2
1
2
3
4
5
6
| import numpy as np
a = np.zeros((32,32))
print(a.shape)
a1 = a[None,:,:]
print(a1.shape)
>>> (32,32) (1,32,32)
|
np.sequeeze()
1
2
3
4
5
6
7
| import numpy as np
a = np.zeros((1,32,32))
print(a.shape)
a1 = a.squeeze()
print(a1.shape)
>>> (1,32,32) (32,32)
|
另一种方式
1
2
3
4
5
| import numpy as np
a = np.zeros((3,32,32))
print(a.shape)
a1 = a[0,:,:]
print(a1.shape)
|
np.flatten()
两者的功能是一致的,将多维数组降为一维,但是两者的区别是返回拷贝还是返回视图
np.flatten()返回一份拷贝,对拷贝所做修改不会影响原始矩阵,
np.ravel()返回的是视图,修改时会影响原始矩阵
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import numpy as np
a = np.array([[1 , 2] , [3 , 4]])
b = a.flatten()
print('b:' , b)
c = a.ravel()
print('c:' , c)
d = a.ravel('F')
print('d:' , d)
b[0] = 10
print('a:' , a)
c[0] = 10
print('a:' , a)
|
1
2
3
4
5
6
7
| b: [1 2 3 4]
c: [1 2 3 4]
d: [1 3 2 4]
a: [[1 2]
[3 4]]
a: [[10 2]
[ 3 4]]
|
allclose
1
2
3
| numpy.allclose(a, b, rtol=1e-05, atol=1e-08, equal_nan=False)[source]
absolute(a - b) <= (atol + rtol * absolute(b))
|
eg: 判断两个数据的误差小于2:
1
| np.allclose(a, b, atol=2)
|
这两个数据,可以是相同维度的,例如
1
2
| a = [149.820974 188.13338026 145.44900513]
b = [151.086161 186.89028926 144.17222595]
|
diag
np.argmax()
1
2
3
4
| import numpy as np
a = np.array([3, 1, 2, 4, 6, 1])
b=np.argmax(a)
print(b)
|
https://wenku.baidu.com/view/1d3dbe48ac1ffc4ffe4733687e21af45b307fe78.html
https://blog.csdn.net/weixin_38145317/article/details/79650188
np.where()
np.where(condition, x, y)
满足条件(condition),输出x,不满足输出y。
如果是一维数组,相当于[xv if c else yv for (c,xv,yv) in zip(condition,x,y)]
1
2
3
4
5
| >>> aa = np.arange(10)
>>> np.where(aa,1,-1)
array([-1, 1, 1, 1, 1, 1, 1, 1, 1, 1]) # 0为False,所以第一个输出-1
>>> np.where(aa > 5,1,-1)
array([-1, -1, -1, -1, -1, -1, 1, 1, 1, 1])
|
np.where(condition)
只有条件 (condition),没有x和y,则输出满足条件 (即非0) 元素的坐标 (等价于numpy.nonzero)。这里的坐标以tuple的形式给出,通常原数组有多少维,输出的tuple中就包含几个数组,分别对应符合条件元素的各维坐标。
1
2
3
| >>> a = np.array([2,4,6,8,10])
>>> np.where(a > 5)
(array([2, 3, 4]),)
|
1
2
3
4
| bid_history = [0, 1, 2, 0, 2]
np.argwhere(bid_history==max(bid_history))
>>>array([[2],
[4]], dtype=int64)
|
np.repeat
1
2
3
| a = np.zeros(54, dtype=np.int8)
batch_num = 4
batch_a = np.repeat(a[np.newaxis,:], batch_num, axis=0)
|
Slice
:: (逆向序列)
1
2
3
4
| a = np.arange(10)
print(a)
print(a[-3:][::])
print(a[-3:][::-1])
|
1
2
3
| [0 1 2 3 4 5 6 7 8 9]
[7 8 9]
[9 8 7]
|
statck相关
stack() Join a sequence of arrays along a new axis.
vstack() Stack along first axis. == np.concatenate(tup, axis=0)
hstack() Stack along second axis. (column wise). == np.concatenate(tup, axis=1)
dstack() Stack arrays in sequence depth wise (along third dimension).==np.concatenate(tup, axis=2)
concatenate() Join a sequence of arrays along an existing axis.
np.stack()
np.hstack()
np.vstack()
np.dstack()
np.concatenate()
np.split()
np.hsplit
np.vsplit
np.dsplit
1
2
3
4
5
6
7
| split : 1D; indices_or_sections ``[2, 3]`` would, for ``axis=0``, result in
- ary[:2]
- ary[2:3]
- ary[3:]
hsplit : Split array into multiple sub-arrays horizontally (column-wise).
vsplit : Split array into multiple sub-arrays vertically (row wise).
dsplit : Split array into multiple sub-arrays along the 3rd axis (depth).
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import numpy as np
a = np.zeros((4, 3))
b = np.ones((4, 1))
print(a.shape)
print(a)
print(b)
c = np.hstack((a, b))
print(c)
d = np.ones((1, 3))
print(d)
c = np.vstack((a, d))
print(c)
|
Out:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| (4, 3)
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
[[1.]
[1.]
[1.]
[1.]]
[[0. 0. 0. 1.]
[0. 0. 0. 1.]
[0. 0. 0. 1.]
[0. 0. 0. 1.]]
[[1. 1. 1.]]
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]
[1. 1. 1.]]
Process finished with exit code 0
|
np矩阵运算:
mean 均值
var 方差
item
dot
数量积又称内积(Kronecker product)、点积(Dot product),对应元素相乘相加,结果是一个标量(即一个数)。

cross
向量积又称外积、叉积(Cross product)
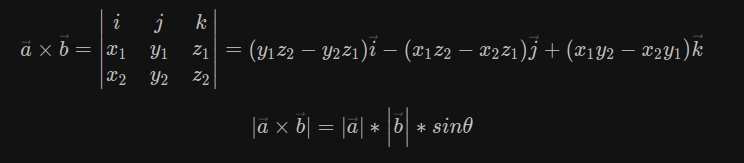
multiply或*
普通乘积:对应元素相乘,结果还是向量。
np.linalg
np.linalg.norm 求范数
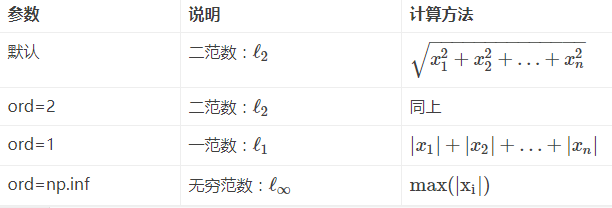
序列化NP
bcolz
1
2
3
4
5
6
| Write:
carr=bcolz.carray(arr, rootdir=fname, mode='w');
carr.flush()
Read:
carr=bcolz.carray(arr, rootdir=fname, mode='r');
|
https://vimsky.com/zh-tw/examples/detail/python-method-bcolz.carray.html
pickle
path相关
glob模块是最简单的模块之一,内容非常少。用它可以查找符合特定规则的文件路径名。跟使用windows下的文件搜索差不多。查找文件只用到三个匹配符:””, “?”, “[]”。””匹配0个或多个字符;”?”匹配单个字符;”[]”匹配指定范围内的字符,如:[0-9]匹配数字。
1
2
3
4
5
6
7
| import glob
print (glob.glob(r"/home/qiaoyunhao/*/*.png"),"\n")
print (glob.glob(r'../*.py'))
|