APIs
[TOC]
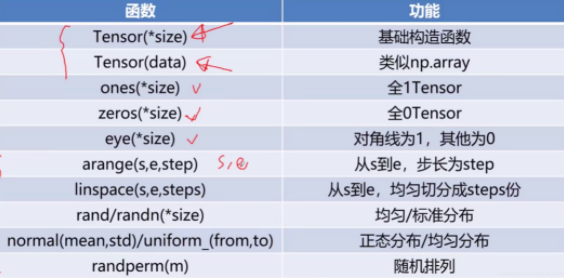
Tensor pytorch 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 data = [[1 ,2 ],[3 ,4 ]] x_data = torch.tensor(data, dtype=torch.float ) float_tensor = torch.FloatTensor([4 ,5 ,6 ]) np_array = np.array(data) x_np_data = torch.from_numpy(data) x_ones = torch.ones_like(x_data) x_rand = torch.rand_like(x_data, dtype=torch.float ) shape = (2 ,3 ) x_ones = torch.ones(shape) x_zeros = torch.zeros(shape) x_rand = torch.rand(shape) tensor.numpy()
libtorch(c++) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 int data[10 ] = {3 ,4 ,6 }torch::Tensor x_data = torch::from_blob (data,{3 },torch::kFloat) std::vector<float > std_vector = {3 ,4 ,6 }; torch::Tensor vector_data = torch::from_brob (std_vector.data (),{3 },torch::kFloat); torch::Tensor x = torch::zeros ({3 ,4 }); torch::Tensor x_zeros = torch::zeros_like (x); torch::Tensor x_ones = torch::ones_like (x); torch::Tensor x_rand = torch::rand_like (x); torch::Tensor y = x torch::Tensor z = x.clone (); torch::Tensor x_ones = torch::ones ({3 ,4 }); torch::Tensor x_zeros = torch::zeros ({3 ,4 }); torch::Tensor x_eye = torch::eye (4 ); torch::Tensor x_full = torch::full ({3 ,4 },10 ); torch::Tensor x_rand = torch::rand ({3 ,4 }); torch::Tensor x_randn = torch::randn ({3 ,4 }); torch::Tensor x_randint = torch::randint (0 ,4 ,{3 ,3 });
张量操作 pytorch 1 2 3 4 5 6 tensor = torch.rand(4 ,4 ) a = tensor[:, 1 ] Tensor[Mask]
libtorch(c++) 1 2 3 4 5 6 7 8 9 10 11 12 auto x = torch::rand({3 ,4 });y = x[1 ]; y = x[1 ][3 ]; auto x = torch::rand({3 ,4 });auto y = x.select(0 ,1 ); auto x = torch::rand({3 ,4 });auto y = x.narrow(0 , 2 , 2 ); auto y = x.slice(0 , 1 , 3 );
3、 提取指定元素形成新的张量(关键字index:就代表是提取出来相应的元素组成新的张量)
1 2 3 4 5 6 7 8 9 10 11 12 std ::cout <<b.index_select(0 ,torch::tensor({0 , 3 , 3 })).sizes();std ::cout <<b.index_select(1 ,torch::tensor({0 ,2 })).sizes(); std ::cout <<b.index_select(2 ,torch::arange(0 ,8 )).sizes(); Tensor x_data = torch::rand({3 ,4 }); Tensor mask = torch::zeros({3 ,4 }); mask[1 ][1 ] = 1 ; mask[0 ][0 ] = 1 ; Tensor x = x_data.index({ mask.to(kBool) });
张量基本运算 3.1 pytorch
1 2 3 x = torch.rand((3 ,4 )) y = x @ x.T y = x.matmul(x.T)
3.2 torchlib
1 2 auto x = torch::rand ({3 ,4 });x.mm (x.t ());
Init Weight 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 torch.nn.init.xavier_uniform_(conv.weight) torch.nn.init.xavier_uniform_(conv.bias, 0 ) for m in net.modules(): if isinstance (m, torch.nn.Conv2d): nn.kaiming_normal_(m.weight, mode = 'fan_in' ) nn.init.kaiming_normal_(m.weight, mode='fan_out' , nonlinearity='relu' )
API-tensor torch — PyTorch 2.0 documentation
torch.reshape() torch.reshape用来改变tensor的shape。 torch.reshape(tensor,shape)
tensor.squeeze() 维度压缩
如果 input 的形状为 (A×1×B×C×1×D) ,那么返回的tensor的形状则为 (A×B×C×D)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 >>> x = torch.zeros(2 , 1 , 2 , 1 , 2 )>>> x.size()torch.Size([2 , 1 , 2 , 1 , 2 ]) >>> y = torch.squeeze(x)>>> y.size()torch.Size([2 , 2 , 2 ]) >>> y = torch.squeeze(x, 0 )>>> y.size()torch.Size([2 , 1 , 2 , 1 , 2 ]) >>> y = torch.squeeze(x, 1 )>>> y.size()torch.Size([2 , 2 , 1 , 2 ]) >>> y = torch.squeeze(x, (1 , 2 , 3 ))torch.Size([2 , 2 , 2 ])
tensor.unsqueenze() 1 2 3 4 5 6 7 8 >>> x = torch.tensor([1 , 2 , 3 , 4 ])>>> torch.unsqueeze(x, 0 )tensor([[ 1 , 2 , 3 , 4 ]]) >>> torch.unsqueeze(x, 1 )tensor([[ 1 ], [ 2 ], [ 3 ], [ 4 ]])
torch.gather函数 (todo)
图解PyTorch中的 []https://zhuanlan.zhihu.com/p/352877584
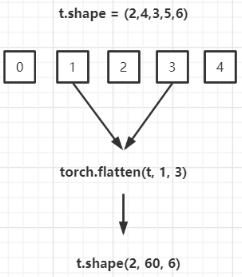
torch.flatten() 扁平化
torch.flatten(t, start_dim=0, end_dim=-1) 的实现原理如下。假设类型为 torch.tensor 的张量 t 的形状如下所示:(2,4,3,5,6),则 torch.flatten(t, 1, 3).shape 的结果为 (2, 60, 6)。将索引为 start_dim 和 end_dim 之间(包括该位置)的数量相乘【1,2,3维度的数据扁平化处理合成一个维度】,其余位置不变。因为默认 start_dim=0,end_dim=-1,所以 torch.flatten(t) 返回只有一维的数据。
mean() 求均值
var() 求方差
item() .item()用于在只包含一个元素的tensor 中提取值,注意是只包含一个元素,否则的话使用.tolist()
tolist() tensor转换为Python List
permute
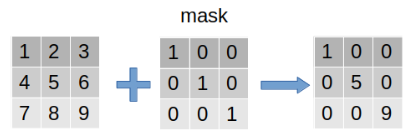
mask pytorch提供mask机制用来提取数据中“感兴趣”的部分。过程如下:左边的矩阵是原数据,中间的mask是遮罩矩阵,标记为1的表明对这个位置的数据“感兴趣”-保留,反之舍弃。整个过程可以视作是在原数据上盖了一层mask,只有感兴趣的部分(值为1)显露出来,而其他部分则背遮住。
参数:
input:输入的原数据
mask:遮罩矩阵
value:被“遮住的”部分填充的数据,可以取0、1等值,数据类型不限,int、float均可
返回值:一个和input相同size的masked-tensor
使用:
output = torch.masked_fill(input, mask, value)
output = input.masked_fill(mask, value)
参数:
input:输入的原数据
mask:遮罩矩阵
out:输出的结果,和原tensor不共用内存,一般在左侧接收,而不在形参中赋值
返回值:一维tensor,数据为“选中”的数据
使用:
torch.masked_select(input, mask, out)
output = input.masked_select(mask)
1 2 selected_ele = torch.masked_select(input=imgs, mask=mask) # true表示selected,false则未选中,所以这里没有取反 # tensor([182., 92., 86., 157., 148., 56.])
说明:将从input中mask得到的数据赋值到source-tensor中
参数:
input:输入的原数据
mask:遮罩矩阵
source:遮罩矩阵的”样子“(全零还是全一或是其他),true表示遮住了
返回值:一个和source相同size的masked-tensor
使用:
output = torch.masked_scatter(input, mask, source)
output = input.masked_scatter(mask, source)
API-Model train(mode=True) 将module设置为 training mode。
仅仅当模型中有Dropout和BatchNorm是才会有影响。
eval() 将模型设置成evaluation模式
仅仅当模型中有Dropout和BatchNorm是才会有影响。
训练 pytorch多机多卡分布式训练
BN使用注意事项 model.eval()之后,pytorch会管理BN的参数,所以不需要TF那般麻烦;
$$
其中gamma、beta为可学习参数(在pytorch中分别改叫weight和bias),训练时通过反向传播更新;而running_mean、running_var则是在前向时先由X计算出mean和var,再由mean和var以动量momentum来更新running_mean和running_var。
所以在训练阶段,running_mean和running_var在每次前向时更新一次;
在测试阶段,则通过net.eval()固定该BN层的running_mean和running_var,此时这两个值即为训练阶段最后一次前向时确定的值,并在整个测试阶段保持不变 。
torchrun torchrun (Elastic Launch) — PyTorch 2.3 documentation
关于集群分布式torchrun命令踩坑记录(自用)-CSDN博客
【分布式训练】单机多卡的正确打开方式(三):PyTorch
Model Save & Load save model 1 2 3 4 5 6 7 8 torch.save({ 'model_state_dict' : {k: _models[k].state_dict() for k in _models}, 'optimizer_state_dict' : {k: optimizers[k].state_dict() for k in optimizers}, "stats" : stats, 'flags' : vars (flags), 'frames' : frames, 'position_frames' : position_frames }, checkpointpath)
save state_dict() 1 torch.save(learner_model.get_model(position).state_dict(), model_weights_dir)
Saving & Loading Model Save:
1 torch.save(model.state_dict(), PATH)
Load:
1 2 3 model = TheModelClass(*args, **kwargs) model.load_state_dict(torch.load(PATH)) model.eval ()
Save/Load Entire Model Officle
Save:
Load:
1 2 3 model = torch.load(PATH) model.eval ()
Export:
1 2 model_scripted = torch.jit.script(model) model_scripted.save('model_scripted.pt' )
Load:
1 2 model = torch.jit.load('model_scripted.pt' ) model.eval ()
Saving & Loading a General Checkpoint for Inference and/or Resuming Training Save:
1 2 3 4 5 6 7 torch.save({ 'epoch' : epoch, 'model_state_dict' : model.state_dict(), 'optimizer_state_dict' : optimizer.state_dict(), 'loss' : loss, ... }, PATH)
Load:
1 2 3 4 5 6 7 8 9 10 11 12 model = TheModelClass(*args, **kwargs) optimizer = TheOptimizerClass(*args, **kwargs) checkpoint = torch.load(PATH) model.load_state_dict(checkpoint['model_state_dict' ]) optimizer.load_state_dict(checkpoint['optimizer_state_dict' ]) epoch = checkpoint['epoch' ] loss = checkpoint['loss' ] model.eval () model.train()
Saving Multiple Models in One File Save:
1 2 3 4 5 6 7 torch.save({ 'modelA_state_dict': modelA.state_dict(), 'modelB_state_dict': modelB.state_dict(), 'optimizerA_state_dict': optimizerA.state_dict(), 'optimizerB_state_dict': optimizerB.state_dict(), ... }, PATH)
Load:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 modelA = TheModelAClass(*args, **kwargs) modelB = TheModelBClass(*args, **kwargs) optimizerA = TheOptimizerAClass(*args, **kwargs) optimizerB = TheOptimizerBClass(*args, **kwargs) checkpoint = torch.load(PATH) modelA.load_state_dict(checkpoint['modelA_state_dict']) modelB.load_state_dict(checkpoint['modelB_state_dict']) optimizerA.load_state_dict(checkpoint['optimizerA_state_dict']) optimizerB.load_state_dict(checkpoint['optimizerB_state_dict']) modelA.eval() modelB.eval() # - or - modelA.train() modelB.train()
Warmstarting Model Using Parameters from a Different Model Saving & Loading Model Across Devices Save:
1 torch.save(modelA.state_dict(), PATH)
Load:
1 2 modelB = TheModelBClass(*args, **kwargs) modelB.load_state_dict(torch.load(PATH), strict=False)
Save on GPU, Load on CPU Save:
1 torch.save(model.state_dict(), PATH)
Load:
1 2 3 device = torch.device('cpu') model = TheModelClass(*args, **kwargs) model.load_state_dict(torch.load(PATH, map_location=device))
Save on GPU, Load on GPU Save:
1 torch.save(model.state_dict(), PATH)
Load:
1 2 3 4 5 device = torch.device("cuda" ) model = TheModelClass(*args, **kwargs) model.load_state_dict(torch.load(PATH)) model.to(device)
Save on CPU, Load on GPU Save:
1 torch.save(model.state_dict(), PATH)
Load:
1 2 3 4 5 device = torch.device("cuda") model = TheModelClass(*args, **kwargs) model.load_state_dict(torch.load(PATH, map_location="cuda:0")) # Choose whatever GPU device number you want model.to(device) # Make sure to call input = input.to(device) on any input tensors that you feed to the model
Saving torch.nn.DataParallel Models Save:
1 torch.save(model.module.state_dict(), PATH)
Load:
1 # Load to whatever device you want
模型参数(打印print) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import torchdef print_model_param_names (model ): for name, param in model.named_parameters(): print (name) def print_model_param_values (model ): for name, param in model.named_parameters(): print (name, param.data) model = torch.nn.Sequential( torch.nn.Linear(10 , 5 ), torch.nn.ReLU(), torch.nn.Linear(5 , 1 ) ) print_model_param_names(model) print_model_param_values(model)
此我们可以使用clone()方法来创建它们的副本。具体来说,我们可以使用clone()方法来创建一个张量的深拷贝,然后使用detach()方法来将其从计算图中分离,从而得到一个不会影响原始张量的新张量。
1 2 3 4 5 6 7 8 9 params = {} for name, param in model.named_parameters(): print ('Parameter name:' , name) print ('Parameter value:' , param) params[name] = param.clone().detach().numpy() model = None