[TOC]
高分辨率
- 单张照片
- 多张照片
SISR 高清图片
SRCNN [ECCV2014]
开山之作,三个卷积层,输入图像是低分辨率图像经过双三次(bicubic)插值和高分辨率一个尺寸后输入CNN。
图像块的提取和特征表示,特征非线性映射和最终的重建。使用均方误差(MSE)作为损失函数。
code: http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html
SCN ICCV 2015
FSRCNN [ECCV2016]
特征提取:低分辨率图像,选取的核9×9设置为5×5。
**收缩:**1×1的卷积核进行降维。
**非线性映射:**用两个串联的3×3的卷积核可以替代一个5×5的卷积核。
扩张:1×1的卷积核进行扩维。
反卷积层:卷积层的逆操作,如果步长为n,那么尺寸放大n倍,实现了上采样的操作。
FSRCNN与SRCNN都是香港中文大学Dong Chao, Xiaoou Tang等人的工作。FSRCNN是对之前SRCNN的改进。
主要在三个方面:
一是在最后使用了一个反卷积层放大尺寸,因此可以直接将原始的低分辨率图像输入到网络中,而不是像之前SRCNN那样需要先通过bicubic方法放大尺寸。
二是改变特征维数,使用更小的卷积核和使用更多的映射层。
三是可以共享其中的映射层,如果需要训练不同上采样倍率的模型,只需要fine-tuning最后的反卷积层。
相对于SRCNN:
在最后使用了一个反卷积层放大尺寸,因此可以直接将原始的低分辨率图像输入到网络中;改变特征维数,使用更小的卷积核和使用更多的映射层;可以共享其中的映射层,如果需要训练不同上采样倍率的模型,只需要fine-tuning最后的反卷积层。
https://blog.csdn.net/sinat_39372048/article/details/81628945
code: http://mmlab.ie.cuhk.edu.hk/projects/FSRCNN.html
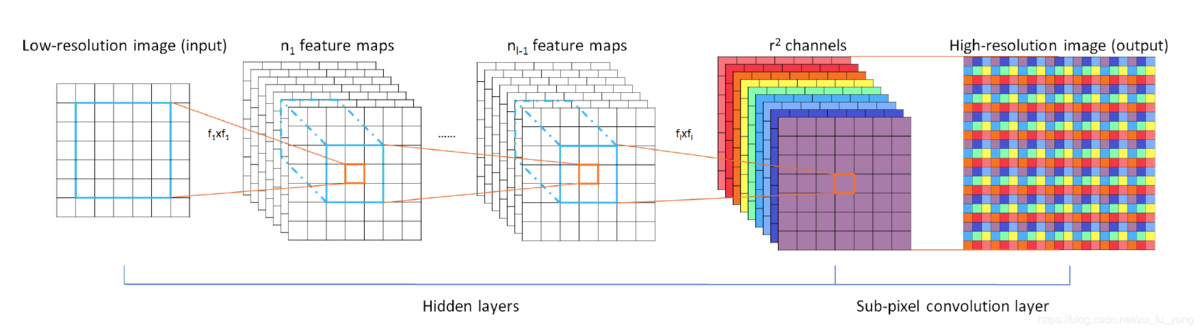
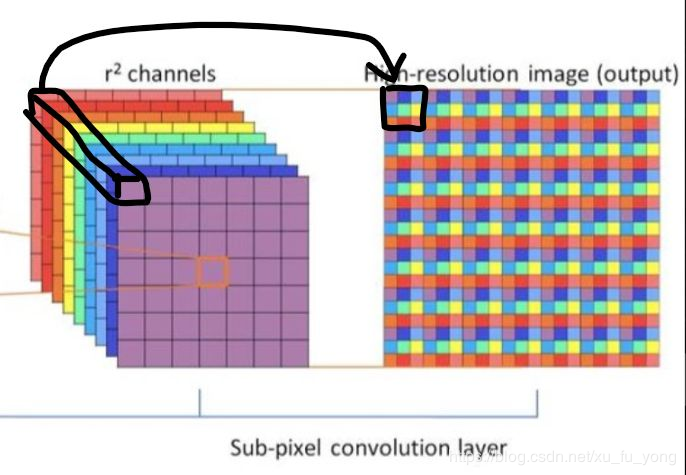
ESPCN [CVPR2016]
核心概念是亚像素卷积层,输入原始低分辨率图像,三个卷积层,将 $H \times W \times r^2$ 的特征图像被重新排列成 $rH \times rW \times 1$的高分辨率图像。
ESPCN激活函数采用tanh替代了ReLU。损失函数为均方误差。
github(tensorflow): https://github.com/drakelevy/ESPCN-TensorFlow
github(pytorch): https://github.com/leftthomas/ESPCN
github(caffe): https://github.com/wangxuewen99/Super-Resolution/tree/master/ESPCN
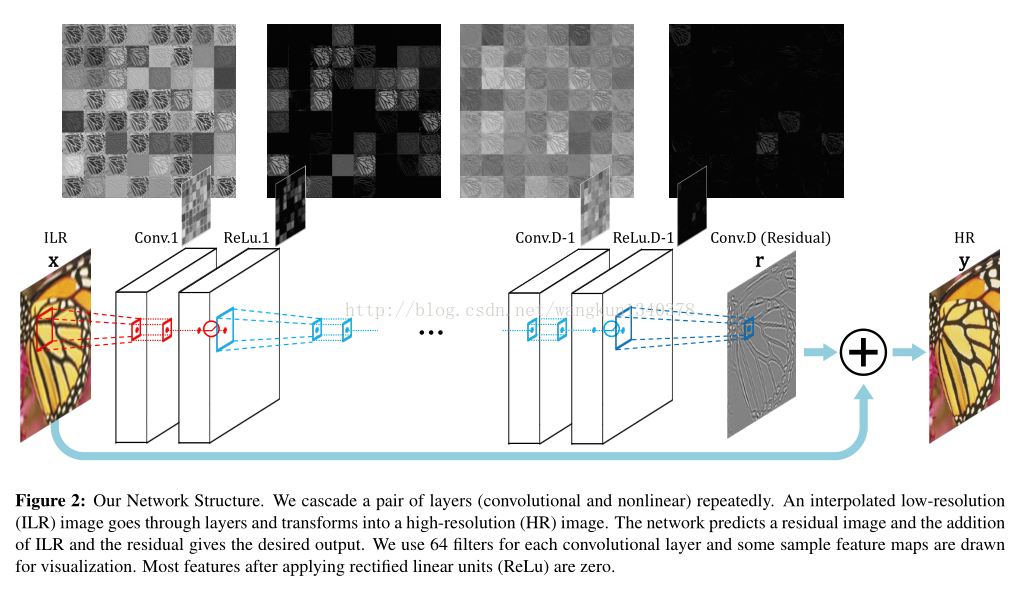
VDSR–7 [CVPR2016]
该论文利用残差学习,加深网络结构(20层),在图像的超分辨率上取得了较好的效果。
只学习高分辨率图像和低分辨率图像之间的高频部分残差即可——残差网络
输入低分辨率图像插值后的图像,再将这个图像与网络学到的残差相加得到最终的网络的输出。
特点:
1.加深了网络结构(20层),:更深的网络结构使得后面的网络层拥有更大的感受野,该文章采取3X3的卷积核,从而使得深度为D的网络,拥有(2D+1)X(2D+1)的感受野,从而可以根据更多的像素点去推断结果像素点
2.采用残差学习(自适应梯度裁剪将梯度限制在某一范围)。
3.卷积补0操作,保证特征图和最终的输出图像在尺寸上都保持一致。
4.多尺度图像共同训练
code: https://cv.snu.ac.kr/research/VDSR/
github(caffe): https://github.com/huangzehao/caffe-vdsr
github(tensorflow): https://github.com/Jongchan/tensorflow-vdsr
github(pytorch): https://github.com/twtygqyy/pytorch-vdsr
https://blog.csdn.net/wangkun1340378/article/details/74231352
DRCN [CVPR 2016]
递归神经网络结构
输入的是插值后的图像,分为三个模块,第一个是Embedding network,相当于特征提取,第二个是Inference network, 相当于特征的非线性映射,第三个是Reconstruction network,即从特征图像恢复最后的重建结果。其中的Inference network是一个递归网络,即数据循环地通过该层多次。将这个循环进行展开,等效于使用同一组参数的多个串联的卷积层.
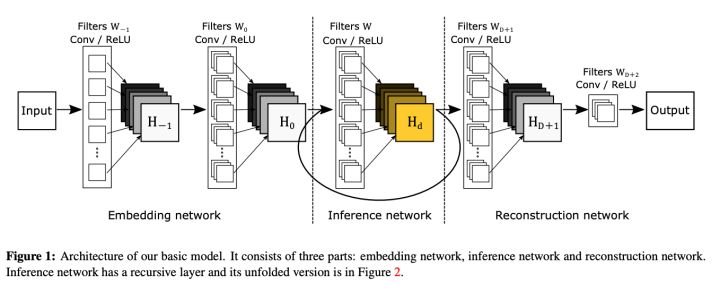
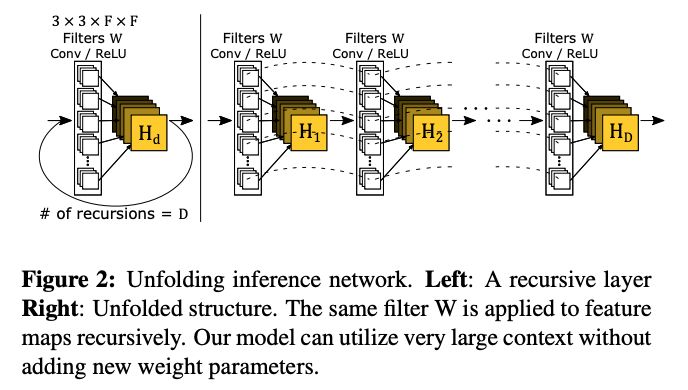
在递归次数比较多的时候,这种基本的递归形式的网络模型会有两个比较典型的问题,一是很容易出现梯度消失或者梯度爆炸的现象,导致基本上无法训练;二是类似于RNN,输出与输入之间有着较长的依赖关系,这种依赖关系导致模型很难获得输入图片中较好的细节。
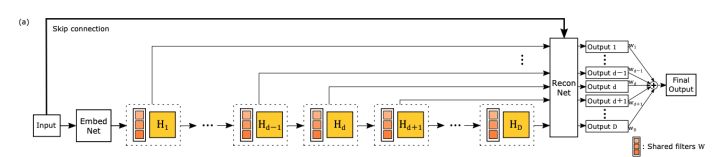 鉴于此,作者提出了递归监督的方法,来使得递归层中间的输出经过重建之后也可以加上监督的信息;然后采用残差学习的方法来解决输入与输出之间的这种长期依赖的关系,来使得输出获得较好的细节。
鉴于此,作者提出了递归监督的方法,来使得递归层中间的输出经过重建之后也可以加上监督的信息;然后采用残差学习的方法来解决输入与输出之间的这种长期依赖的关系,来使得输出获得较好的细节。
code: https://cv.snu.ac.kr/research/DRCN/
githug(tensorflow): https://github.com/jiny2001/deeply-recursive-cnn-tf
https://zhuanlan.zhihu.com/p/76868378
RED [NIPS2016]
对称的卷积层-反卷积层构成的网络结构
RED网络的结构是对称的,每个卷积层都有对应的反卷积层。卷积层用来获取图像的抽象内容,反卷积层用来放大特征尺寸并且恢复图像细节。
用到了与VDSR相同的Idea:网络中有一条线是将输入的图像连接到后面与最后的一层反卷积层的输出相加。
RED中间的卷积层和反卷积层学习的特征是目标图像和低质图像之间的残差。RED的网络深度为30层,损失函数用的均方误差。
VDSR [CVPR. (2016)]
DRRN [CVPR. (2017)]
LapSRN [CVPR. (2017)]
MSLapSRN (2017)
ENet-PAT [ICCV. (2017)]
MemNet [CVPRW 2017]
DRRN [CVPR2017]:
DRRN的作者应该是受到了(VDSR, DRCN,残差网络)启发,采用了更深的网络结构来获取性能的提升。作者也在文中用图片示例比较了DRRN与上述三个网络的区别,比较示例图如下所示。
ResNet是链模式的局部残差学习。VDSR是全局残差学习。DRCN是全局残差学习+单权重的递归学习+多目标优化。DRRN是多路径模式的局部残差学习+全局残差学习+多权重的递归学习。
选用的是1个递归块和25个残差单元,深度为52层的网络结构
github(caffe): https://github.com/tyshiwo/DRRN_CVPR17
LapSRN [CVPR2017]
改进前面大部分算法
论文中作者先总结了之前的方法存在有三点问题。
一是有的方法在输入图像进网络前,需要使用预先定义好的上采样操作(例如bicubic)来获得目标的空间尺寸,这样的操作增加了额外的计算开销,同时也会导致可见的重建伪影。而有的方法使用了亚像素卷积层或者反卷积层这样的操作来替换预先定义好的上采样操作,这些方法的网络结构又相对比较简单,性能较差,并不能学好低分辨率图像到高分辨率图像复杂的映射。
二是在训练网络时使用 l2 型损失函数时,不可避免地会产生模糊的预测,恢复出的高分辨率图片往往会太过于平滑。
三是在重建高分辨率图像时,如果只用一次上采样的操作,在获得大倍数**(8倍以上)的上采样因子**时就会比较困难。
LapSRN通过逐步上采样,一级一级预测残差的方式,在做高倍上采样时,也能得到中间低倍上采样结果的输出。由于尺寸是逐步放大,不是所有的操作都在大尺寸特征上进行,因此速度比较快。LapSRN设计了损失函数来训练网络,对每一级的结果都进行监督,因此取得了不错的结果。
github(matconvnet): https://github.com/phoenix104104/LapSRN
github(pytorch): https://github.com/twtygqyy/pytorch-LapSRN
github(tensorflow): https://github.com/zjuela/LapSRN-tensorflow
SRDenseNet [CVPR 2017]
SRDenseNet将稠密块结构应用到了超分辨率问题上,这样的结构给整个网络带来了减轻梯度消失问题、加强特征传播、支持特征复用、减少参数数量的优点
DenseNet: 结构给整个网络带来了减轻梯度消失问题、加强特征传播、支持特征复用、减少参数数量的优点。
SRGAN(SRResNet) [CVPR2017]
在这篇文章中,将生成对抗网络(Generative Adversarial Network, GAN)用在了解决超分辨率问题上
《Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network》
用均方误差优化SRResNet(SRGAN的生成网络部分),文章中的实验结果表明,用基于均方误差的损失函数训练的SRResNet,得到了结果具有很高的峰值信噪比,但是会丢失一些高频部分细节,图像比较平滑。而SRGAN得到的结果则有更好的视觉效果。
SRGAN利用感知损失(perceptual loss)和对抗损失(adversarial loss)来提升恢复出的图片的真实感。
其中,又对内容损失分别设置成基于均方误差、基于VGG模型(损失函数)低层特征和基于VGG模型高层特征三种情况作了比较,在基于均方误差的时候表现最差,基于VGG模型高层特征比基于VGG模型低层特征的内容损失能生成更好的纹理细节。
在生成网络部分(SRResNet)部分包含多个残差块,每个残差块中包含两个3×3的卷积层,卷积层后接批规范化层(batch normalization, BN)和PReLU作为激活函数,两个2×亚像素卷积层(sub-pixel convolution layers)被用来增大特征尺寸。在判别网络部分包含8个卷积层,随着网络层数加深,特征个数不断增加,特征尺寸不断减小,选取激活函数为LeakyReLU,最终通过两个全连接层和最终的sigmoid激活函数得到预测为自然图像的概率。SRGAN的损失函数为:
其中内容损失可以是基于均方误差的损失的损失函数:
也可以是基于训练好的以ReLU为激活函数的VGG模型的损失函数:
i和j表示VGG19网络中第i个最大池化层(maxpooling)后的第j个卷积层得到的特征。对抗损失为:
文章中的实验结果表明,用基于均方误差的损失函数训练的SRResNet,得到了结果具有很高的峰值信噪比,但是会丢失一些高频部分细节,图像比较平滑。而SRGAN得到的结果则有更好的视觉效果。其中,又对内容损失分别设置成基于均方误差、基于VGG模型低层特征和基于VGG模型高层特征三种情况作了比较,在基于均方误差的时候表现最差,基于VGG模型高层特征比基于VGG模型低层特征的内容损失能生成更好的纹理细节。
github(tensorflow): https://github.com/zsdonghao/SRGAN
github(tensorflow): https://github.com/buriburisuri/SRGAN
github(torch): https://github.com/junhocho/SRGAN
github(caffe): https://github.com/ShenghaiRong/caffe_srgan
github(tensorflow): https://github.com/brade31919/SRGAN-tensorflow
github(keras): https://github.com/titu1994/Super-Resolution-using-Generative-Adversarial-Networks
github(pytorch): https://github.com/ai-tor/PyTorch-SRGAN
EDSR+MDSR [NTIRE2017]
EDSR(单一尺度网络)
EDSR是NTIRE2017超分辨率挑战赛上获得冠军的方案。
如论文中所说,EDSR最有意义的模型性能提升是去除掉了SRResNet多余的模块,从而可以扩大模型的尺寸来提升结果质量。
EDSR的网络结构如下图所示。
EDSR在结构上与SRResNet相比,就是把批规范化处理(batch normalization, BN)操作给去掉了。文章中说**:原始的ResNet最一开始是被提出来解决高层的计算机视觉问题,比如分类和检测,直接把ResNet的结构应用到像超分辨率这样的低层计算机视觉问题,显然不是最优的。**由于批规范化层消耗了与它前面的卷积层相同大小的内存,在去掉这一步操作后,相同的计算资源下,EDSR就可以堆叠更多的网络层或者使每层提取更多的特征,从而得到更好的性能表现。EDSR用L1范数样式的损失函数来优化网络模型。在训练时先训练低倍数的上采样模型,接着用训练低倍数上采样模型得到的参数来初始化高倍数的上采样模型,这样能减少高倍数上采样模型的训练时间,同时训练结果也更好。
这篇文章还提出了一个能同时不同上采样倍数的网络结构MDSR。
MDSR 多尺度超分辨率架构
两种模型EDSR(单一尺度网络) 和 MDSR(多尺度超分辨率架构)。
MDSR的中间部分还是和EDSR一样,只是在网络前面添加了不同的预训练好的模型来减少不同倍数的输入图片的差异。在网络最后,不同倍数上采样的结构平行排列来获得不同倍数的输出结果。
从文章给出的结果可以看到,EDSR能够得到很好的结果。增大模型参数数量以后,结果又有了进一步的提升。因此如果能够解决训练困难的问题,网络越深,参数越多,对提升结果确实是有帮助吧。
github(torch): https://github.com/LimBee/NTIRE2017
github(tensorflow): https://github.com/jmiller656/EDSR-Tensorflow
github(pytorch): https://github.com/thstkdgus35/EDSR-PyTorch
SRMDNF
ESRGAN [ECCV2018]
《Enhanced Super-Resolution Generative Adversarial Networks》
相比于SRGAN它在三个方面进行了改进
- 改进了网络结构,对抗损失,感知损失
- 引入Residual-in-Residu Dense Block(RRDB)
- 使用激活前的VGG特征来改善感知损失
https://zhuanlan.zhihu.com/p/61009988
RCAN [ECCV 2018]
Image Super-Resolution Using Very Deep Residual Channel Attention Networks
PyTorch code for our ECCV 2018 paper “Image Super-Resolution Using Very Deep Residual Channel Attention Networks”
https://github.com/yulunzhang/RCAN
Code:
综述
ref: https://blog.csdn.net/Jemary_/article/details/92091545
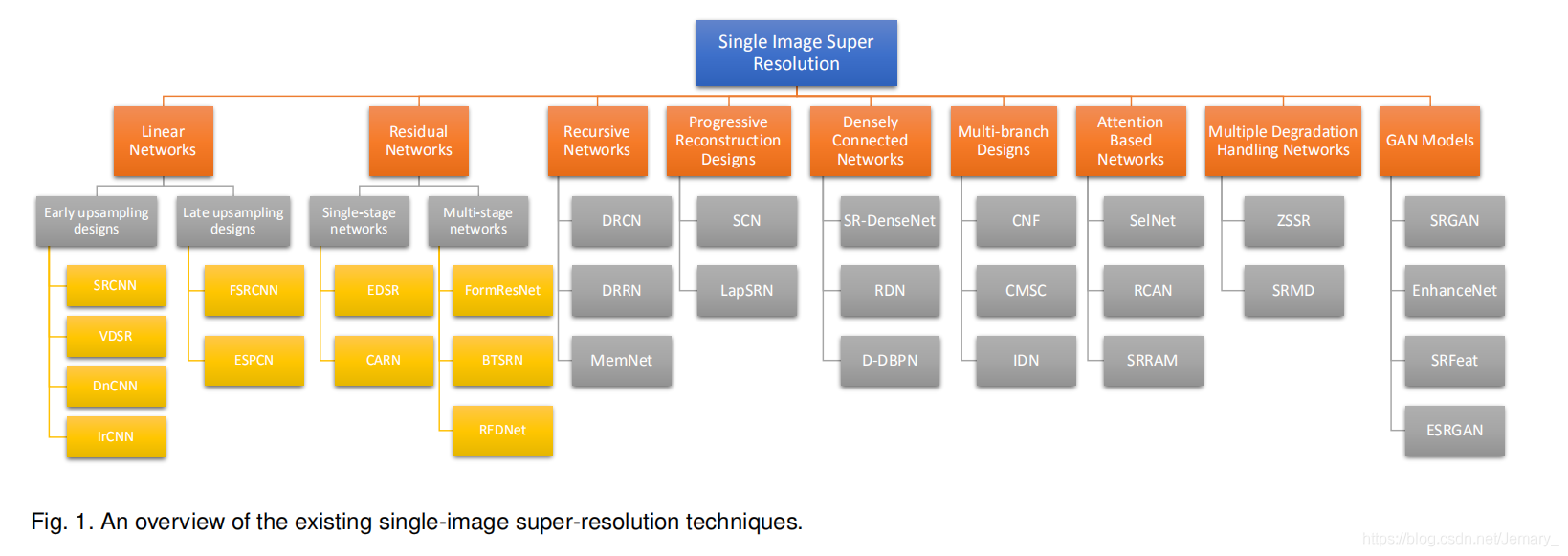
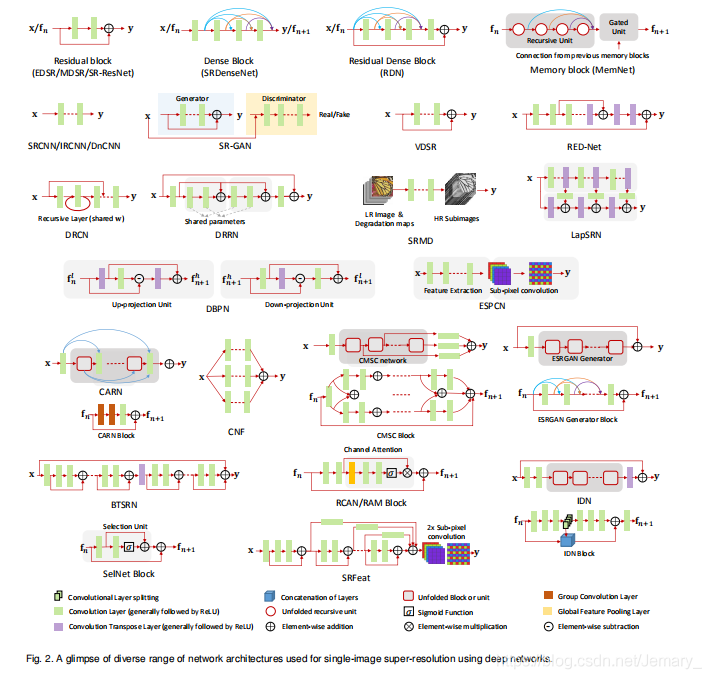
Refrences
论文综述 Super-Resolution via Deep Learning