[toc]
深度学习模型加速与压缩常用方法-总体介绍
深度学习模型加速方向大致分为两种:
一、轻量化网络结构设计
- 分组卷积(group convolution,典型的如ShuffleNet和MobileNet等)
- 分解卷积(inception结构等)
- Bottleneck结构(通过1x1卷积进行降维和升维等操作)
- 神经网络结构搜索(Neural Architecture Search,简称NAS)
- 硬件适配
二、模型压缩相关技术
- 网络剪枝
- 知识蒸馏
- 参数量化
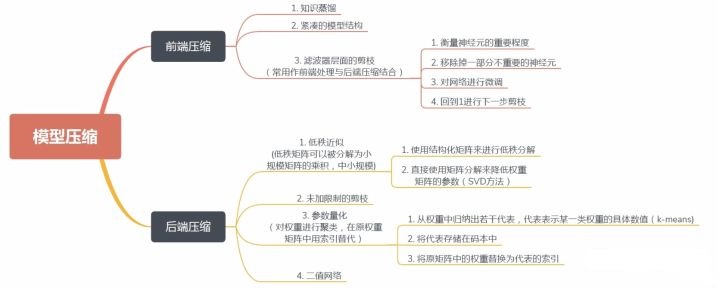
按照压缩过程对网络结构的破坏程度, 我们将模型压缩技术分为“前端压缩”与“后端缩”两部分。
所谓“前端压缩”,是指不改变原网络结构的压缩技术,主要包括知识蒸馏、紧凑的模型结构设计以及滤波器层面的剪枝等;而“后端压缩”则包括低秩近似、未加限制的剪枝、参数量化以及二值网络等,其目标在于尽可能地减少模型大小,因而会对原始网络结构造成极大程度的改造。
其中,由于“前端压缩”未改变原有的网络结构,仅仅只是在原模型的基础上减少了网络的层数或者滤波器的个数,其最终的模型可完美适配现有的深度学习库,如caffe等。相比之下,“后端压缩”为了追求极致的压缩比,不得不对原有的网络结构进行改造,如对参数进行量化表示等,而这样的改造往往是不可逆的。同时,为了获得理想的压缩效果,必须开发相配套的运行库,甚至是专门的硬件设备,其最终的结果往往是一种压缩技术对应于一套运行库,从而带来了巨大的维护成本。
ref: https://zhuanlan.zhihu.com/p/150212141
深度学习模型加速与压缩常用方法–剪枝
剪枝,模型量化,压缩,加速
网络剪枝
- unstructured pruning(非结构化剪枝)
- structured pruning(结构化剪枝)
unstructured pruning是指对于individual weights进行prune;structured pruning是指对于filter/channel/layer的prune。其中非结构化修剪方法(直接修剪权重)的一个缺点是所得到的权重矩阵是稀疏的,如果没有专用硬件/库,则不能达到压缩和加速的效果。相反,结构化修剪方法在通道或层的层次上进行修剪。由于原始卷积结构仍然保留,因此不需要专用的硬件/库来实现。在结构化修剪方法中,通道修剪是最受欢迎的,因为它在最细粒度的水平上运行,同时仍然适合传统的深度学习框架。
修建算法三阶段流程

训练:训练大型的过度参数化的模型,得到最佳网络性能,以此为基准;修剪:根据特定标准修剪训练的大模型,即重新调整网络结构中的通道或层数等,来得到一个精简的网络结构;微调:微调修剪的模型以重新获得丢失的性能,这里一般做法是将修剪后的大网络中的保留的(视为重要的)参数用来初始化修剪后的网络,即继承大网络学习到的重要参数,再在训练集上finetune几轮。
然而,在《Rethinking the value of network pruning》(ICLR 2019)这篇论文里,作者做出了几个与常见观点相矛盾的结论,通过测试目前六种最先进的剪枝算法得出以下结论:
- 训练过度参数化的模型不是获得有效的最终模型所必需的;
- 学习的大型模型的“重要”权重不一定有助于修剪后的小型模型;
- 修剪的本质是网络体系结构本身,而不是一组继承的“重要”权重,来主导最终模型的效率优势,这表明一些修剪算法可以被视为表征网络架构探索。
作者选择了三个数据集和三个标准的网络结构(数据集:CIFAR-10, CIFAR-100,ImageNet,网络结构:VGG, ResNet,DenseNet),并验证了6个网络裁剪方法,接下来分别介绍这几种当下流行的剪枝算法:
- L1-norm based Channel Pruning (Li et al., 2017)
- ThiNet (Luo et al., 2017)
- Regression based Feature Reconstruction (He et al., 2017b)
- Network Slimming (Liu et al., 2017)
- Sparse Structure Selection (Huang & Wang, 2018)
- Non-structured Weight Pruning (Han et al., 2015)
作者:Alex Tian
链接:https://zhuanlan.zhihu.com/p/157562088
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
(一)L1-norm based Channel Pruning
本方法出自论文《Pruning Filters For Efficient ConvNets》,论文提出了对卷积层(对Filters进行剪枝,以及Feature maps)进行剪枝操作,移除对于CNN精度影响很小的卷积核,然后进行retrain,不会造成稀疏连接(稀疏矩阵操作需要特殊的库等来处理)。

卷积核剪枝原则:(即应该去掉哪些卷积核)
- 对每个卷积核 $ Fi,j $ ,计算它的权重绝对值(L1正则)之和 $Sj=\sum_{l=1}^{ni}\sum_{}^{}{\left| Kl \right|}$ ;
- 根据 $$ Sj $$ 排序;
- 将m个权重绝对值之和最小的卷积核以及对应的feature maps剪掉。下一个卷积层中与剪掉的feature maps相关的核也要移除;
- 一个对于第i层和第i+1层的新的权重矩阵被创建,并且剩下的权重参数被复制到新模型中;
相比于基于其他的标准来衡量卷积核的重要性(比如基于激活值的feature map剪枝),l1-norm是一个很好的选择卷积核的方法,认为如果一个filter的绝对值和比较小,说明该filter并不重要。之后的步骤就是retrain,论文指出对剪枝后的网络结构从头训练要比对重新训练剪枝后的网络(利用了未剪枝之前的权重)的结果差。
(二)ThiNet
本方法出自论文《ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression》,主要贡献:1)基于贪心策略与最小化重建误差,设计了ThiNet剪枝方法,并且是规整的通道剪枝方法;2)将网络剪枝视作优化问题,并利用下一层的输入输出关系获取统计信息,以决定当前层的剪枝;3)在ImageNet数据集上,获得了良好的剪枝效果(主要是Resnet50与VGG-16),并在其他任务上取得了良好的迁移效果。
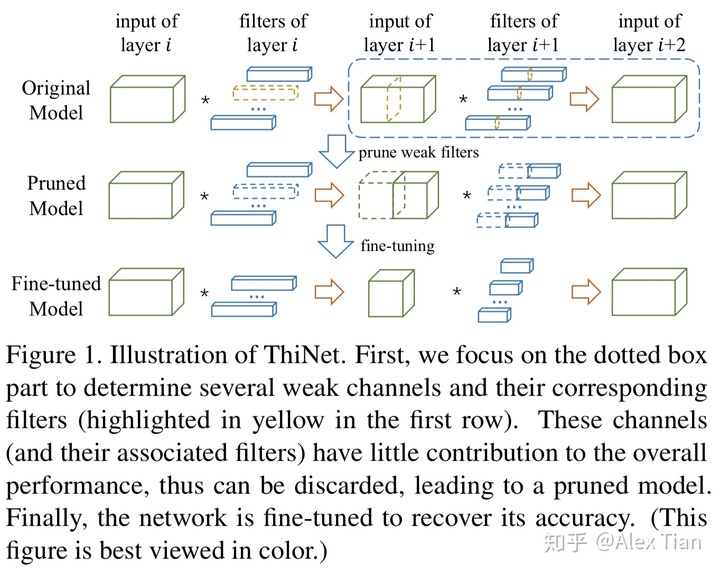
ThiNet的剪枝步骤如上图所示,对于给定的预训练模型以及固定的剪枝率,逐层裁剪冗余的滤波器(3D filters或2D kernels),总体包括通道选择、通道剪枝与fine-tuning三个阶段:
- Channel Selection:利用第i+1 层的统计信息指导第i 层的剪枝,即从第i+1 层的输入特征中提取最优子集,用于估计第i+1的输出特征,而其余输入特征以及相对应的3D filters均可被删除;
- Pruning:根据第一步通道选择的结果,剪除第i 层对应的3D filters以及第i+1 层的2D kernels,从而获得结构紧凑、纤瘦的模型(Thin-Net);
- Fine-tuning:完成第i 层的剪枝之后,在训练集上微调1~2个epochs,以恢复因剪枝丢失的精度。在完成整个模型的剪枝之后,通常需要微调更多的epochs;
- 回到第一步,完成第i+1 层的剪枝;
通道选择原则:
寻找通道最优子集用于估计输出特征的Channel Selection,可表示为如下优化问题:
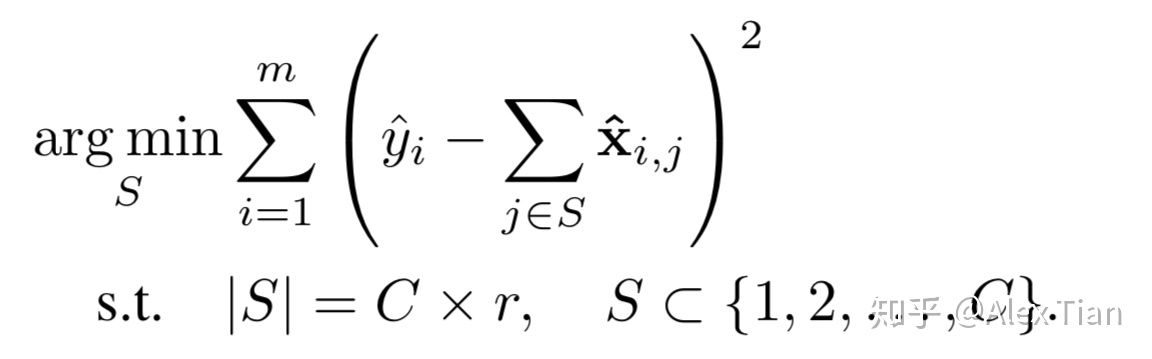
等价而言,定义T 为需要移除的通道子集,其满足 ![[公式]](/2021/12/03/AI/DL/Infrence/%7D.svg+xml) and
and ![[公式]](/2021/12/03/AI/DL/Infrence/oslash.svg+xml) ,则最优化问题可重新写成:
,则最优化问题可重新写成:
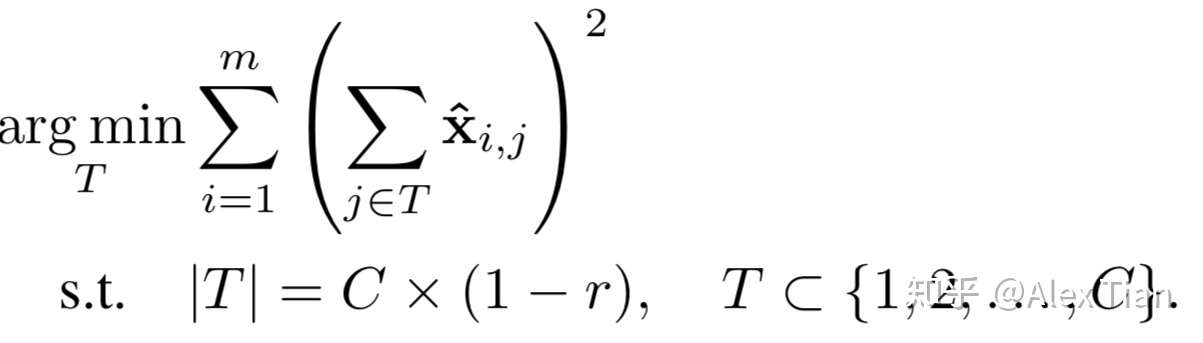
上式亦可理解为,所构建的集合T , 其所包含元素的L2 norm最小。由于集合T 通常比集合S 小,因此求解上述等价问题,具有更高的实现效率。下图是采用贪心策略(Greedy Method)求解集合T 的描述,每次迭代往T 中所添加的元素,需要确保目标函数最小。从而确保完成样本集遍历、并达成目标剪枝率之后,能够删除最不重要的输入特征,最终完成Channel Selection。

以上为应用贪心策略选取需要删除的通道集合。
(三)Regression based Feature Reconstruction
本方法出自论文《Channel Pruning for Accelerating Very Deep Neural Networks》,本文采用了通道剪枝方法,同上一种方法思路一致,考虑减少输入feature maps中的若干channels信息,然后通过调整weights使整体output feature map的信息不会丢失太多。
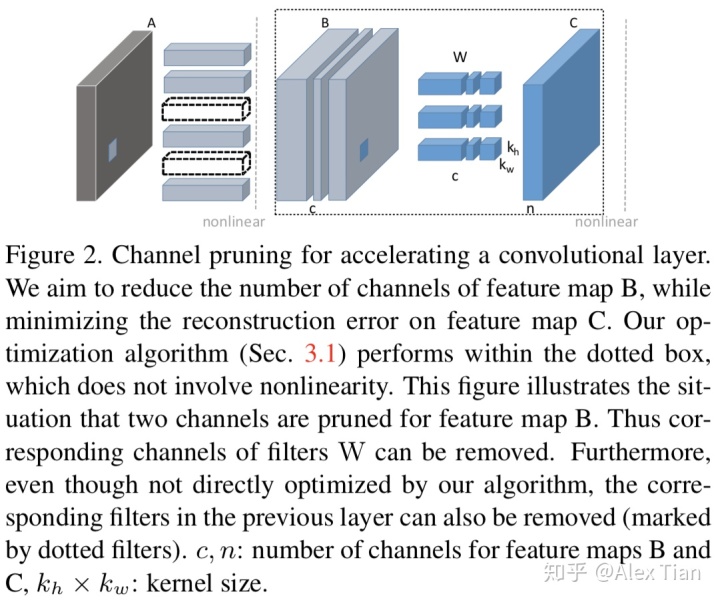
如图所示,目标就是减少B 的feature map, 那么B中的channel被剪掉,会同时使得上游对应的卷积核个数减少,以及下游对应卷积核的通道数减少。关键在于通道选择,如何选择通道而不影响信息的传递很重要。为了进行channel selection ,作者引入了β作为mask ,目标变为 :
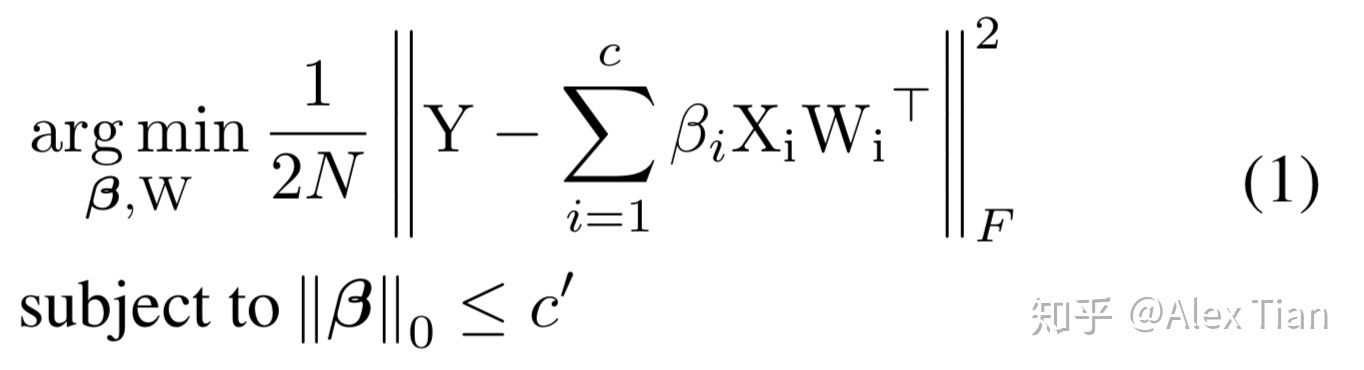
β是一个列向量,如果βi=0 则代表对应的通道被剪除,c ‘代表经过选择后的通道个数 c’<=c,因此作者分两步来优化,首先固定W,优化β ;然后固定β,优化W。而且为了增加β的稀疏度,将β的L1正则项加入优化函数;另外则增加了W的范数为1的强约束以让我们得到的W解不过于简单,原优化函数变为:
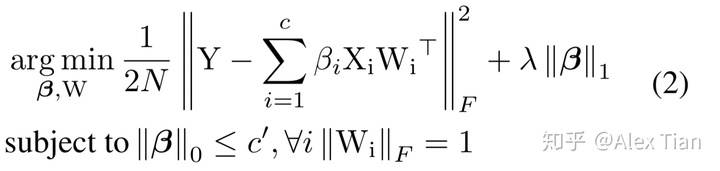
进而我们再将它变为两个分步骤的子优化问题:
(1).求参数β的子优化问题
首先,我们可固定W不变,寻求参数β的组合,即决定输入feature map的哪些input channels可以舍弃。这显然是个NP-hard的组合优化问题,作者使用了经典的启发式LASSO方式来迭代寻找最优的β值,如下公式所示:
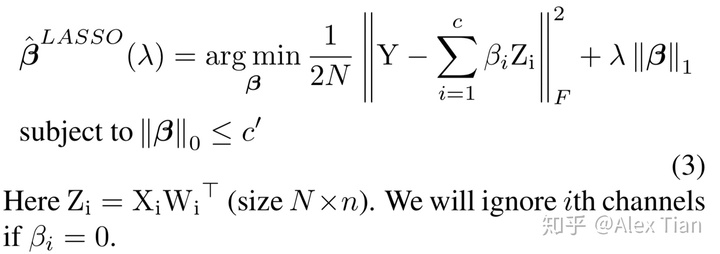
(2).求参数W的子优化问题
然后我们再固定上面得到的β不变,再求解最优的W参数值,本质上就是求解如下的MSE问题:
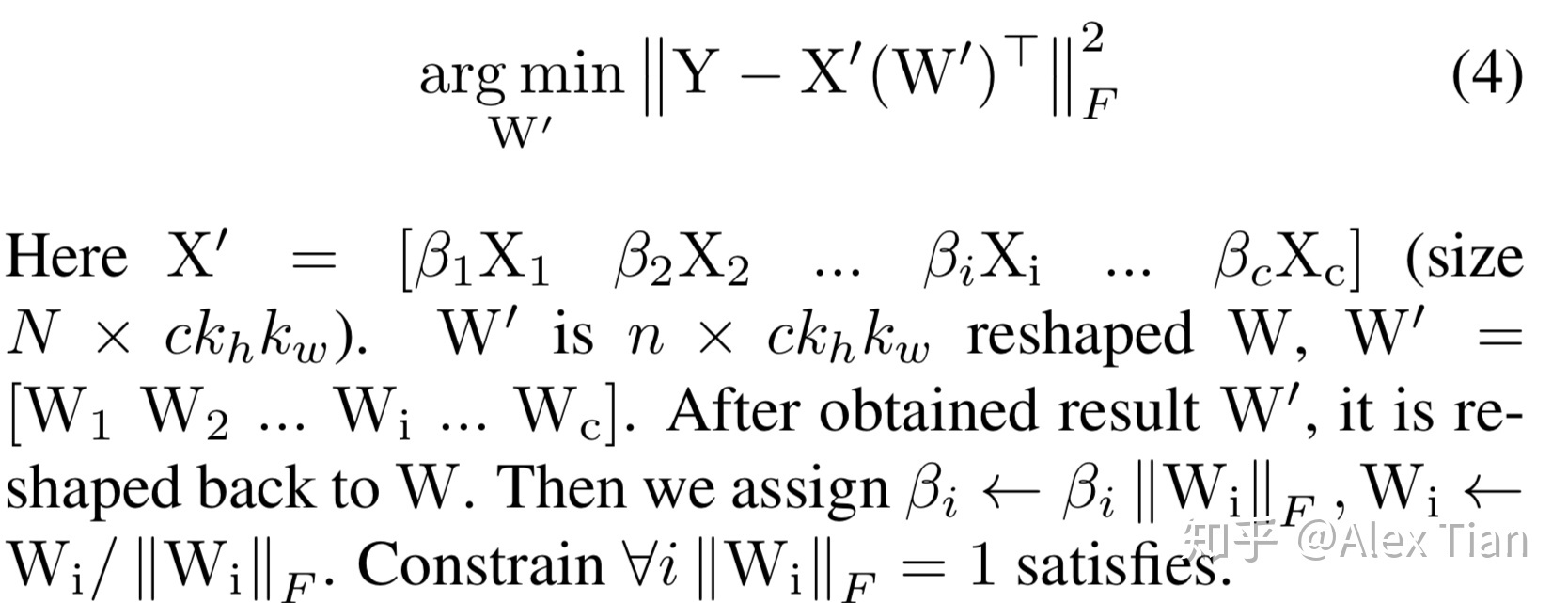
以上所介绍的方法为单个conv层pruning所使用的方法。而在将此方法应用于整个CNN model时,方法也类似,只需要sequentially将此它应用于每个层即可(当然某些特殊的多分支层需要稍稍特殊对待)。
知识蒸馏
量化(float->int)
1、量化映射方法,也就是将float-32映射到Int数据类型,每个间隔是相等的还是不相等的,这里就是均匀量化(uniform quantization)和非均匀量化(non-uniform quantization),也可以叫作线性量化和非线性量化
2、关于映射到整数是数值范围是有正负数,还是都是正数,这里就是对称量化(有正负数)和非对称量化(全是正数),非对称量化就有zero-point,zero-point的主要作用是用于做padding。
3、原精度即浮float-32,量化到什么样的数据类型,这里就有float和int;到底要选择量化后的是多少个bit,这里就有1-bit(二值网络)、2-bit(三值网络)、3-bit、4-bit、5-bit、6-bit、7-bit、8-bit,这几种量化后的数值类型是整型。
4、是固定所有网络都是相同的bit-width,还是不同的,这里就有混合精度量化(Mixed precision)
5、是从一个已经训练好的模型再进行量化,还是有fine tune的过程或者直接是从头开始训练一个量化的模型,这里就有Post-training quantization(后量化,即将已经训练完的模型参数进行量化)、quantization-aware training(量化感知训练,即在从头开始训练中加入量化)和quantization-aware fine tune(在fine tune训练中加入量化)。