[TOC]
开源算法库
| OpenSpiel | 框架 | DeepMind | |
| SpriteWorld & Bsuite | 框架 | DeepMind | |
| Acme | 分布式强化学习算法框架 | DeepMind | |
| PPO | facebook-OpenAI | ||
| gym | 框架工具包 | facebook-OpenAI | |
| Baselines | 框架,Demo | facebook-OpenAI |
游戏平台
RLCard
Atari
RL 算法
| Value-Base | Policy Gradient | AC | ||
|---|---|---|---|---|
| TD3 | ||||
| DQN | Y | |||
| AC | ||||
| A2C | Y | |||
| A3C | Y | |||
| REINFORCE | Y | |||
| DDPG | Y | Y | ||
| TRPG | Y | |||
| PPO | on-policy | Y | ||
| SAC | off-policy | |||
| IMPALA | Y |
带着问题去学习
Advance函数是什么?为什么这样设计?
PPO算法的改进点有几个?
分布式强化学习
- 分布式强化学习(Distributed Reinforcement Learning):分布式算法,如IMPALA(Importance Weighted Actor-Learner Architecture)和R2D2(Recurrent Replay Distributed DQN),是近年来的重要发展。这些算法允许大规模分布式训练和数据并行化,从而提高了学习效率和可扩展性。
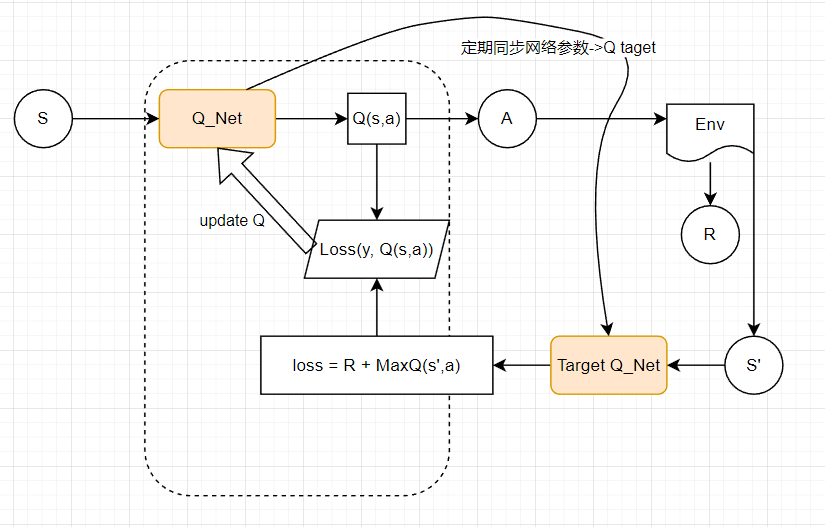
DQN
两个神经网络,一个延迟更新权重,一个实时训练中进行参数更新。
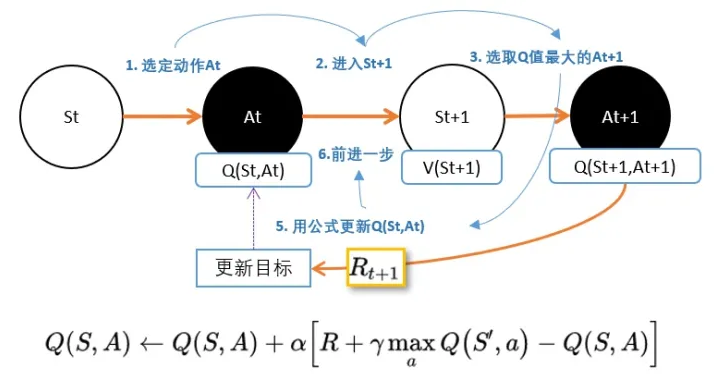
我们从公式中也能看出,DQN不能用于连续控制问题原因,是因为maxQ(s’,a’)函数只能处理离散型的。那怎么办?
我们知道DQN用magic函数,也就是神经网络解决了Qlearning不能解决的连续状态空间问题。那我们同样的DDPG就是用magic解决DQN不能解决的连续控制型问题就好了。
也就是说,用一个magic函数,直接替代maxQ(s’,a’)的功能。也就是说,我们期待我们输入状态s,magic函数返回我们动作action的取值,这个取值能够让q值最大。这个就是DDPG中的Actor的功能。
# DQN(Double/ Duel/ D3DQN)bilibili
深度 Q 网络(deep Q network,DQN)原理&实现 - 缙云山车神 - 博客园
Noisy DQN
1 | fc1 = relu(fc(X)) |
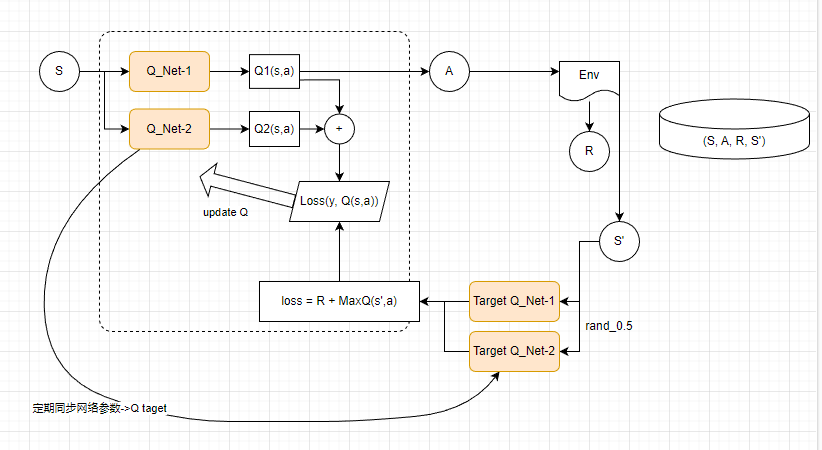
Double DQN
Q学习是基于贪心策略的,这会导致最大化偏差问题,和双Q学习思想一致。下面是双Q学习的伪代码,可以借鉴一下。
Dueling DQN
对偶网络(duel network)
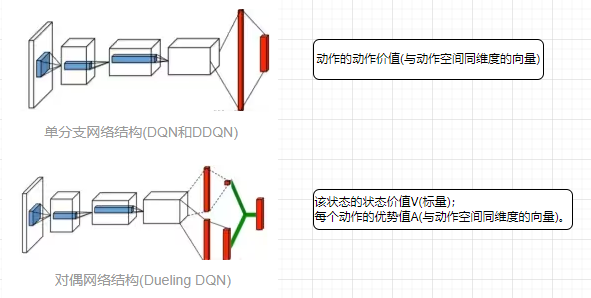
D3QN
D3QN(Dueling Double Deep Q Network)
/todo
Rainbow
- Double Q-learning
- Prioritized replay
- Dueling networks
- Multi-step learning
- Distributional RL
- Noisy Nets
集合了在此之前的六大卓有成效的DQN变体,将其训练技巧有机的组合到一起
Policy Gradient
有两个缺陷:方差大,离线学习
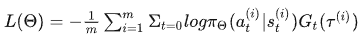
# 强化学习从零到RLHF(五)Actor-Critic,A2C,A3C zhihu
# 强化学习基础 Ⅷ: Vanilla Policy Gradient 策略梯度原理与实战 zhihu
# 如何理解策略梯度(Policy Gradient)算法?(附代码及代码解释)zhihu
Reinforce(MC-PG)

AC
(解决高方差问题)
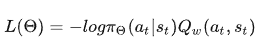 策略梯度的Gt(轨迹t时刻的实际后续累计回报,变成了t时刻采取动作a的期望后续累计回报)=等效于Qt(a,s) ; Q指动作值函数;
策略梯度的Gt(轨迹t时刻的实际后续累计回报,变成了t时刻采取动作a的期望后续累计回报)=等效于Qt(a,s) ; Q指动作值函数;
需要维护两套可训练参数 $\theta$ 、$w$ :
actor,$\theta$ 控制策略
Critic, w评估动作,输出Q value 用于策略梯度的计算。

# 理解Actor-Critic的关键是什么?(附代码及代码分析) 知乎
A2C (引入优势函数 Advantage Actor-Critic)
我们也可以使用优势函数作为Critic来进一步稳定学习,实际上A2C才是Actor-Critic 架构更多被使用的做法。
这个想法是,优势函数计算一个操作与某个状态下可能的其他操作相比的相对优势:与状态的平均值相比,在某个状态执行该操作如何更好。它从状态-动作对中减去状态的期望值。
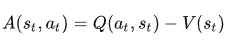
换句话说,此函数计算我们在该状态下执行此操作时获得的额外奖励,与在该状态获得的期望奖励相比。
额外的奖励是超出该状态的预期值。
我们的actor损失函数为 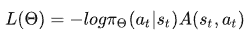
- 如果 A(s,a)> 0:我们的梯度被推向那个方向。
- 如果 A(s,a)< 0:我们的梯度被推向相反的方向。

A3C zhihu
A3C全称为Asynchronous advantage actor-critic。
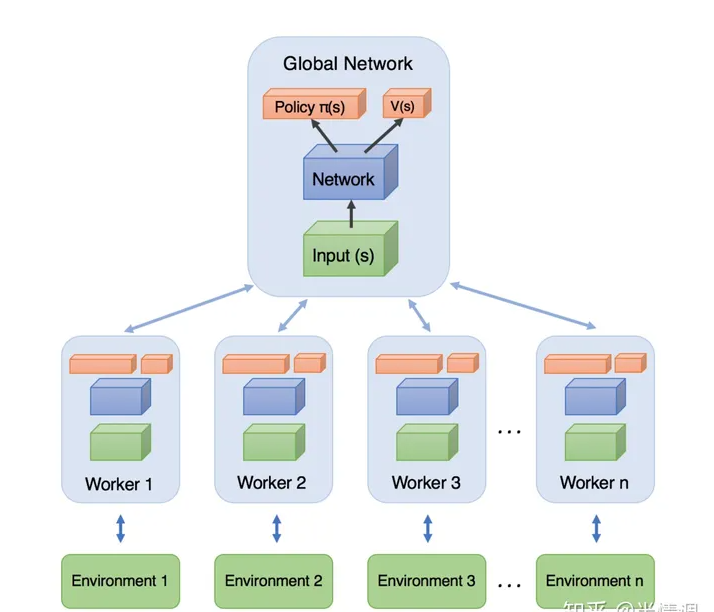
前文讲到,神经网络训练时,需要的数据是独立同分布的,为了打破数据之间的相关性,DQN等方法都采用了经验回放的技巧。然而经验回放需要大量的内存,打破数据的相关性,经验回放并非是唯一的方法。另外一种是异步的方法,所谓异步的方法是指数据并非同时产生,A3C的方法便是其中表现非常优异的异步强化学习算法。
A3C模型如下图所示,每个Worker直接从Global Network中拿参数,自己与环境互动输出行为。利用每个Worker的梯度,对Global Network的参数进行更新。每一个Worker都是一个A2C。
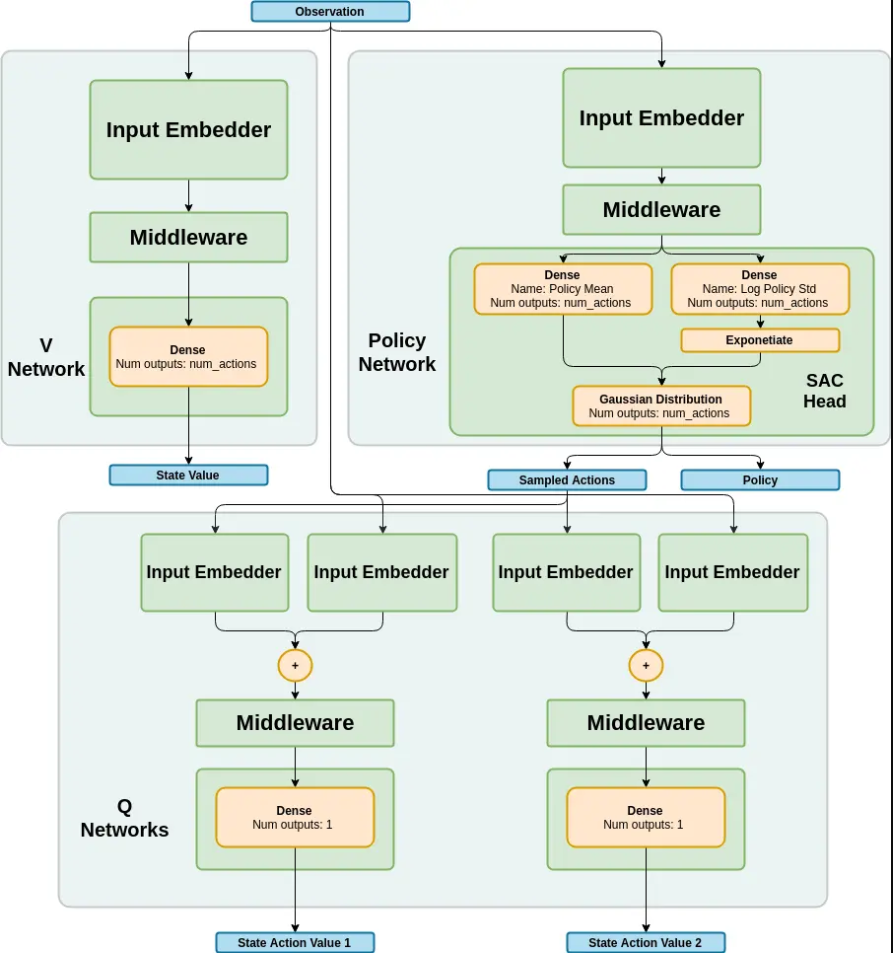
SAC (soft Actor-Critic)
SAC即Soft Actor-Critic(柔性致动/评价),它是一种基于off-policy和最大熵的深度强化学习算法,其由伯克利和谷歌大脑的研究人员提出。
SAC算法是强化学习中的一种off-policy算法,全称为Soft Actor-Critic,它属于最大熵强化学习范畴。
SAC算法的网络结构类似于TD3算法,都有一个Actor网络和两个Critic网络,但SAC算法的目标网络只有两个Critic网络,没有Actor网络。
SAC算法解决的问题是离散动作空间和连续动作空间的强化学习问题,它学习一个随机性策略,在不少标准环境中取得了领先的成绩,是一个非常高效的算法。
在SAC算法中,每次用Critic网络时会挑选一个值小的网络,从而缓解值过高估计的问题,进而提高算法的稳定性和收敛速度。
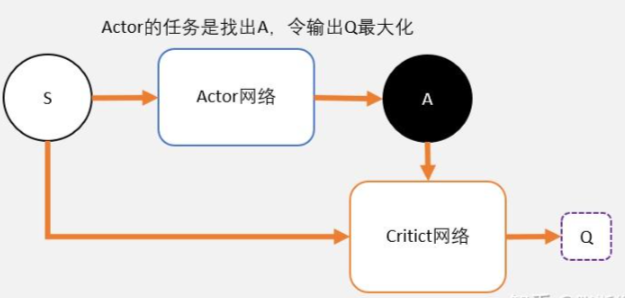
DDPG
deep deterministic policy gradient,深度确定性策略梯度算法。
- PPO输出的是一个策略,也就是一个概率分布,而DDPG输出的直接是一个动作。
Deep Deterministic Policy Gradient (DDPG) | 莫烦Python
Pytorch实现DDPG算法_ddpg pytorch-CSDN博客
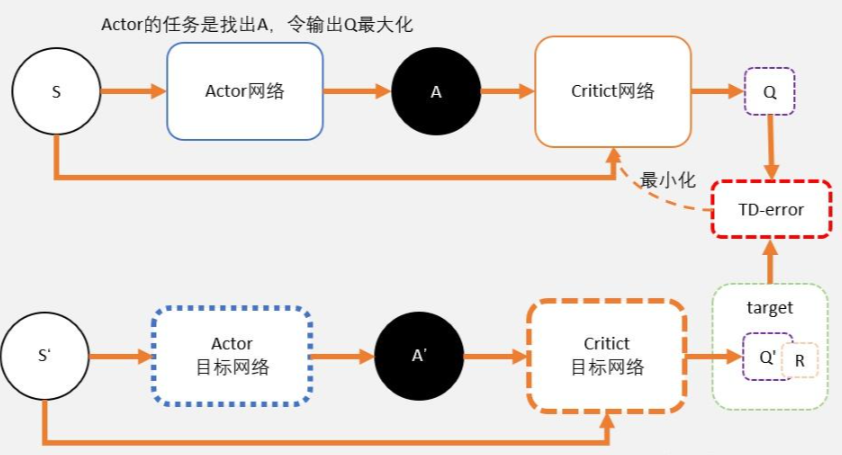
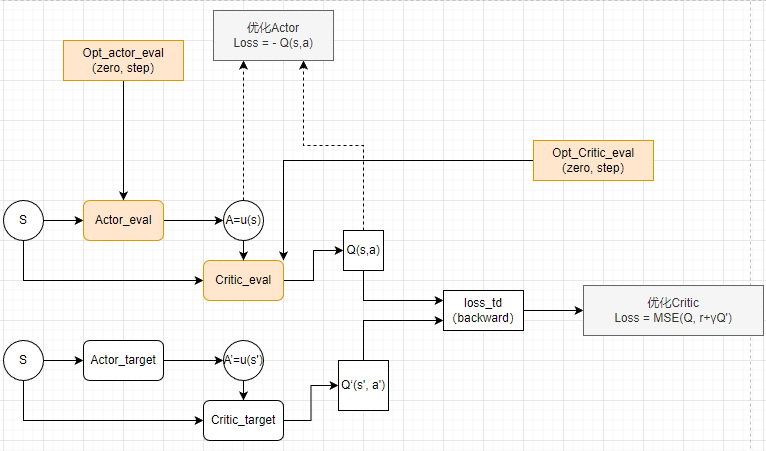
TD3
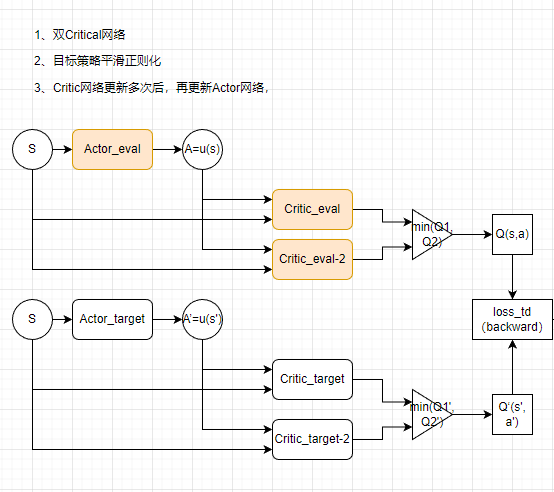
TD3算法主要解决了DDPG算法的高估问题。在DDPG算法的基础上,TD3算法提出了三个关键技术:
- 双重网络(Double network):采用两套Critic网络,计算目标值时取二者中的较小值,从而抑制网络过估计问题。
- 目标策略平滑正则化(Target policy smoothing regularization):计算目标值时,在下一个状态的动作上加入扰动,从而使得价值评估更准确。
- 延迟更新(Delayed update):Critic网络更新多次后,再更新Actor网络,从而保证Actor网络的训练更加稳定。
TD3算法在许多连续控制任务上都取得了不错的表现。
TD3算法(Twin Delayed Deep Deterministic policy gradient)-CSDN博客
TRPO 置信域策略优化算法
PPO(Proximal Policy Optimization)
TRPO优化效率上一个改进,其通过修改TRPO算法,使其可以使用SGD算法来做置信域更新,并且用clipping的方法方法来限制策略的过大更新,保证优化在置信域中进行。
PPO 算法利用新策略和旧策略的比例,从而限制了新策略的更新幅度。
PPO-Max
https://blog.csdn.net/jinzhuojun/article/details/80417179
PPO算法是一种用于强化学习的策略优化算法,全称为Proximal Policy Optimization。
PPO算法基于策略梯度方法,通过约束优化的方式来保证每次迭代的更新幅度不会过大,从而提高算法的稳定性和收敛速度。
PPO算法通过两个不同的目标函数来更新策略函数,分别是Clipped Surrogate Objective和Trust Region Policy Optimization。其中,PPO-Penalty类似于TRPO算法,将KL散度作为目标函数的一个惩罚项,并自动调整惩罚系数,使其适应数据的规模;而PPO-Clip则没有KL散度项,也没有约束条件,使用一种特殊的裁剪技术,在目标函数中消除了新策略远离旧策略的动机。
PPO算法还使用了Generalized Advantage Estimation(GAE)的技术来估计策略函数的价值函数,从而提高了算法的性能和收敛速度。
PPO算法的应用范围非常广泛,可以用于各种强化学习任务,如机器人控制、游戏玩法、自然语言处理等方面。在OpenAl的研究中,PPO算法被用于训练人工智能玩Atari游戏,以及AlphaGo Zero等强化学习任务中,取得了优秀的表现。
总的来说,PPO算法是一种稳定、高效的强化学习算法,具有广泛的应用价值。
PPO算法实现gym连续动作空间任务Pendulum(pytorch)
Python强化练习之PyTorch opp算法实现月球登陆器(得分观察)
影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现
【深度强化学习】(6) PPO 模型解析,附Pytorch完整代码[【运行过】
Coding PPO from Scratch with PyTorch (Part 1/4)[专业详细]
深度增强学习PPO(Proximal Policy Optimization)算法源码走读_ppo算法-CSDN博客
强化学习(9):TRPO、PPO以及DPPO算法-CSDN博客
DPPO(多进程PPO)
Rainbow
组成Rainbow的这六大变体如下:
- Double Q-learning
- Prioritized replay
- Dueling networks
- Multi-step learning
- Distributional RL
- Noisy Nets
Apex
soft actor-critic
反向强化学习(IRL)
模仿学习
在经典的强化学习中,智能体通过与环境交互和最大化reward期望来学习策略。
在模仿学习中没有显式的reward,因而只能从专家示例中学习。
GAIL
**GAIL的核心思想:**策略生成器G和判别器D的一代代博弈
策略生成器:策略网络,以state为输入,以action为输出
判别器:二分类网络,将策略网络生成的 (s, a) pair对为负样本,专家的(s,a)为正样本
learn 判别器D:
给定G,在与环境交互中通过G生成完整或不完整的episode(但过程中G要保持不变)作为负样本,专家样本作为正样本来训练D
learn 生成器G:
给定D,通过常规的强化学习算法(如PPO)来学习策略网络,其中reward通过D得出,即该样本与专家样本的相似程度
G和D的训练过程交替进行,这个对抗的过程使得G生成的策略在与环境的交互中得到的reward越来越大,D“打假”的能力也越来越强。
AIRL
Learning Robust Rewards with Adversarial Inverse Reinforcement learning
RL Apply
| info | ||
|---|---|---|
| DouZero | ||
| DanZero | Distribute Q-learning | |
| MuZero |
DeepMind
AlphaZero
启发式搜索(MCTS)+强化学习+自博弈的方法,
MuZero # model based专题三–MuZero系列
Muzero的贡献在AlphaZero强大的搜索和策略迭代算法的基础上加入了模型学习的过程,使其能够在不了解状态转移规则的情况下,达到了当时的SOTA效果。
Muzero的模型有三部分:
representation:表征编码,使用历史观测序列编码为隐空间的
dynamics:动态模型,这个就是MBRL经典的Dynamic Model
prediction:值模型。输入输出策略和价值函数
EfficientZero detail
接下来是NIPS2021的EfficientZero,这篇文章强调的是sample-efficiency,使用limited data,在仅有两小时实时游戏经验的情况下,在Atari 100K基准上实现了190.4%的平均人类性能和116%的中位数人类性能,并且在DMC Control 100K基准超过了state SAC(oracle),性能接近2亿帧的DQN,而消耗的数据少500倍。
EfficientZero基于MuZero,做了如下三点改进:
(1)使用自监督的方式来学习temporally consistent environment model
(2)端到端的学习value prefix,预测时间段内奖励值之和,降低预测reward不准导致的误差
(3)改变Multi-step reward的算法,使用一个自适应的展开长度来纠正off-policy target
SpriteWorld & Bsuite (DeepMind)
https://blog.csdn.net/weixin_31351409/article/details/101189820
https://github.com/deepmind/spriteworld
https://github.com/deepmind/bsuite
Acme
https://www.sohu.com/a/400058213_473283
https://github.com/deepmind/acme
https://arxiv.org/pdf/2006.00979v1.pdf
https://www.deepmind.com/research?tag=Reinforcement+learning
OpenSpiel
https://zhuanlan.zhihu.com/p/80526746
极小化极大(Alpha-beta剪枝)搜索、蒙特卡洛树搜索、序列形式线性规划、虚拟遗憾最小化(CFR)、Exploitability
外部抽样蒙特卡洛CFR、结果抽样蒙特卡洛CFR、Q-learning、价值迭代、优势动作评论算法(Advantage Actor Critic,A2C)、Deep Q-networks (DQN)
短期价值调整(EVA)、Deep CFR、Exploitability 下降(ED) 、(扩展形式)虚拟博弈(XFP)、神经虚拟自博弈(NFSP)、Neural Replicator Dynamics(NeuRD)
遗憾策略梯度(RPG, RMPG)、策略空间回应oracle(PSRO)、基于Q的所有行动策略梯度(QPG)、回归CFR (RCFR)、PSROrN、α-Rank、复制/演化动力学。
OpenAI
https://blog.csdn.net/kittyzc/article/details/83006403
Baselines
https://github.com/openai/baselines
- A2C
- ACER
- ACKTR
- DDPG
- DQN
- GAIL
- HER
- PPO1
- PPO2
- TRPO
Spinning Up
spinning up是一个深度强化学习的很好的资源
https://spinningup.openai.com/en/latest/
根据官方文档,spinning up实现的算法包括:
Vanilla Policy Gradient (VPG)
Trust Region Policy Optimization (TRPO)
Proximal Policy Optimization (PPO)
Deep Deterministic Policy Gradient (DDPG)
Twin Delayed DDPG (TD3)
Soft Actor-Critic (SAC)
学习路线
**张伟楠:**我在上海交通大学给致远学院ACM班和电院AI试点班的同学讲授强化学习,由于学生的专业和本课程内容很贴合,因此学生对强化学习的原理部分关注较多。在夏令营中获得学生的反馈更多来自如何在各种各样的领域用好强化学习技术,当然也有不少本专业的学生对强化学习本身的研究十分了解。对于来我们APEX实验室的强化学习初学者,我建议的学习路线是:
\1. 先学习UCL David Silver的强化学习课程:https://www.davidsilver.uk/teaching/
这是强化学习的基础知识,不太包含深度强化学习的部分,但对后续深入理解深度强化学习十分重要。
\2. 然后学习UC Berkeley的深度强化学习课程:http://rail.eecs.berkeley.edu/deeprlcourse/
\3. 最后可以可以挑着看OpenAI 的夏令营内容:https://sites.google.com/view/deep-rl-bootcamp/lectures
当然,如果希望学习中文的课程,我推荐的是:
\1. 我本人在上海交通大学的强化学习课程: https://www.boyuai.com/rl
\2. 周博磊老师的强化学习课程:https://www.bilibili.com/video/BV1LE411G7Xj
Ref
深度强化学习系列(15): TRPO算法原理及Tensorflow实现-CSDN博客
Pytorch实现强化学习DQN玩迷宫游戏(莫凡强化学习DQN章节pytorch版本)_莫烦迷宫 强化学习 pytorch实现-CSDN博客