无人驾驶中的动态环境检测-2D检测
[TOC]
2D检测

IDea:
- 位置:先找到所有的ROI
- Sliding Window / Slective Search / … | CNN(RPN …)
- 类别:对每个ROI进行分类提取类别信息
- HOG/DPM/SIFT/LBP/… | CNN(conv pooling)
- SVM / Adaboost / … | CNN (softmax ….)
- 位置修正:Bounding Box Regression
- Linear Regresion / … | CNN(regression …)
How to Generate ROI

How To Classify ROI

4.1 two-step (基于图片的检测方法)
- RCNN, SPPnet, Fast-RCNN, Faster-RCNN
Befor CNN
位置:sliding window / region proposal(候选框)
- 手工特征 + 分类器
- 位置修正

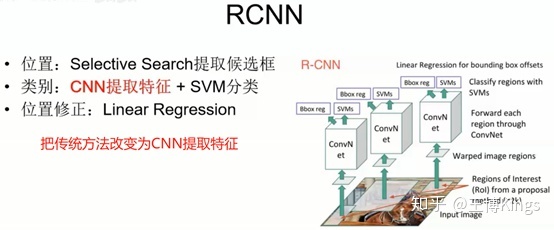
RCNN
- 位置:Selective Search 提取候选框
- 类别:CNN提取特征 + SVM分类
- 每个候选区域都要做一遍卷积,太多重复计算
- 位置修正:Linear Regression
SPPnet
- 位置:Selective Search 提取候选框
- 类别:CNN提取特征 + SVM分类
- 共享卷积,大大降低计算量
- SPP层,不同尺度的特征–>固定特尺度特征(后接全连接层)
- 把原始图片中的box区域mapping映射到CNN提取后的feature的一个box
- 通过金字塔池化,把原本不同大小的box,提取成固定大小的特征
- 输入到FC层
- 位置修正:Linear Regression

Fast-RCNN
- 位置:Selective Search 提取候选框
- 类别:CNN特征提取 + CNN分类
- 分类和回归都使用CNN实现,两种损失可以反传以实现联动调参(半end-to-end)
- SPP层—换成—>ROI pooling: (可能损失精读)加速计算
- 位置修正:CNN回归

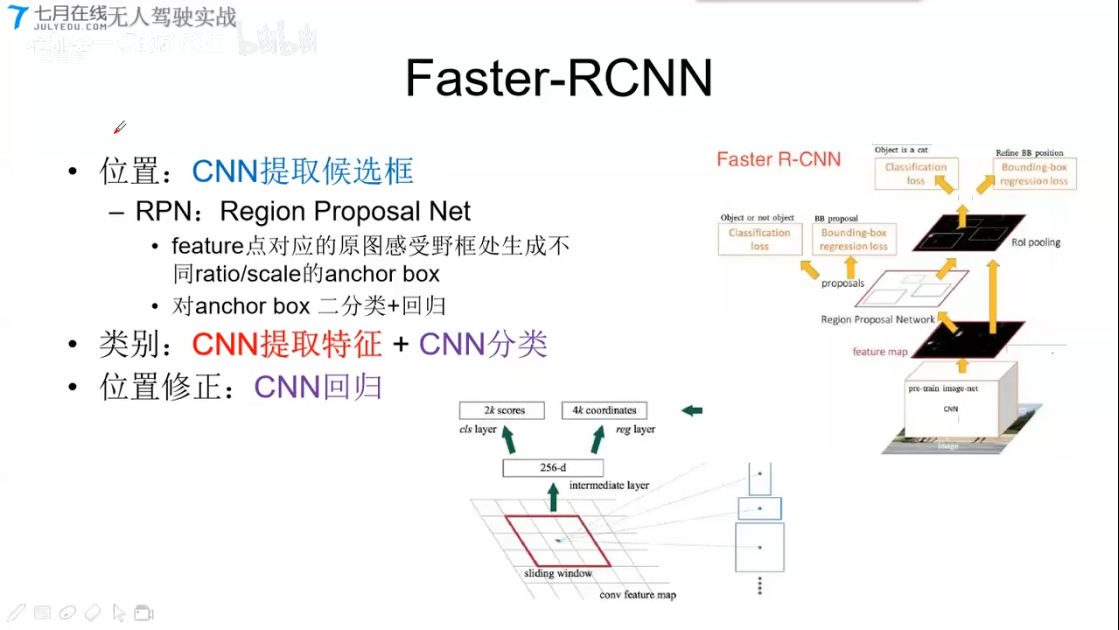
Faster-RCNN
- 位置:CNN提取候选框
- RPN:Region Proposal Net
- feature 点对应的原图感受野框处生成不同ration/scale的anchor box
- 对anchor box (锚点框) 二分类 + 回归
- 2k socre 是否有物体
- 4k coork 回归量,修正位置($\delta{A}$)
- RPN:Region Proposal Net
- 类别:CNN特征提取 + CNN分类
- 位置修正:CNN回归
4.2 one-step
- YOLO,
- SSD
- YOLOv2
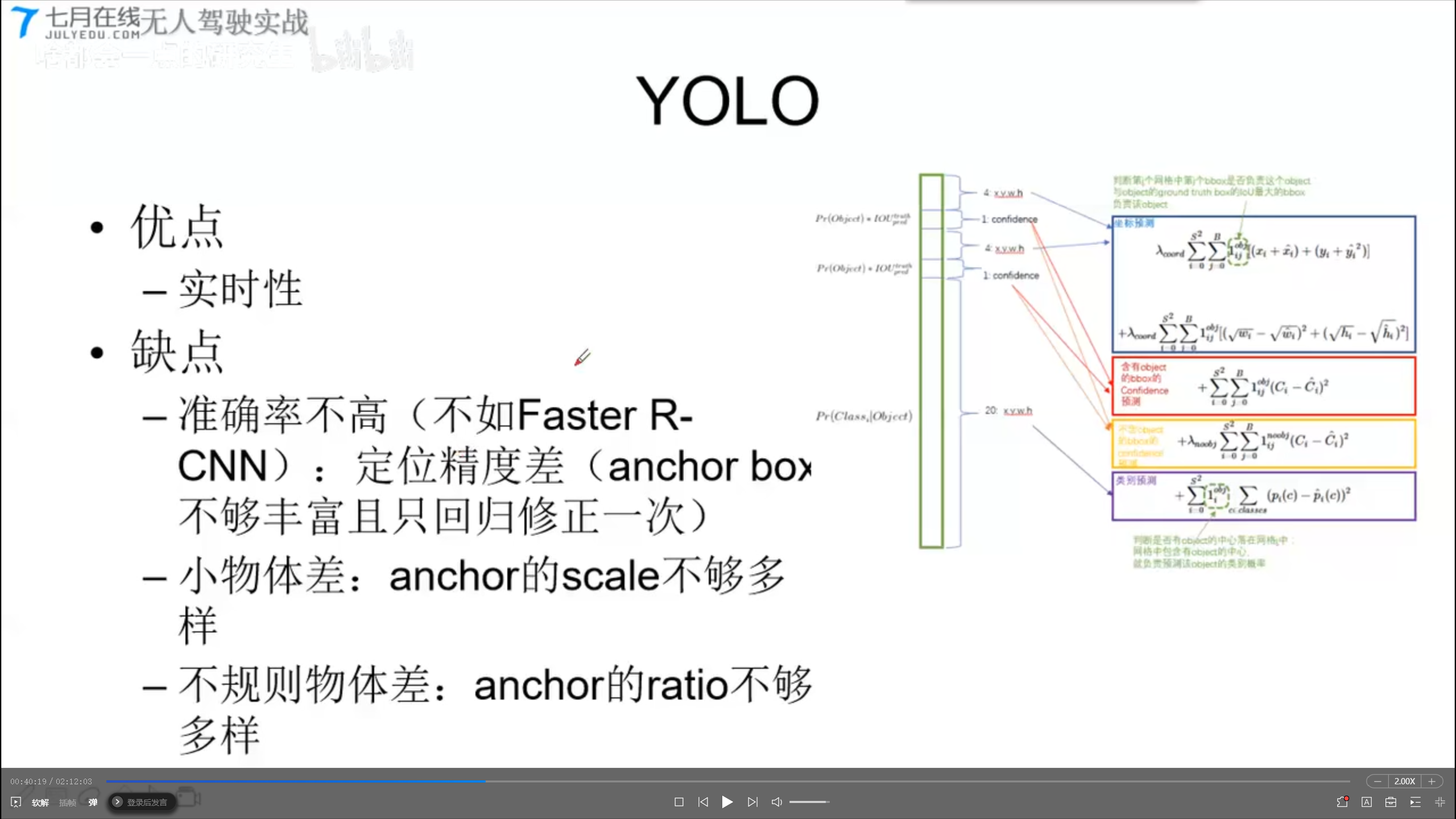
YOLO
- 位置:
- Faster-RCNN
- YOLO
- 全图划分成7x7的网格,每个网格对应2个default box
- 没有候选框,直接对default box做全分类+回归(box中心坐标的x,y相对于对应的网格归一化到0-1之间,w,h用图像的width和height归一化到0-1之间)
- FC1—->FC2{1470x1}–reshape->{7x7x30} ————{1x1x30}
- 类别:CNN提取特征 + CNN分类
- 优点:实时性
- 缺点:
- 准确率不高(不如faster-rcnn);定位精度差(anchor box不够丰富且只能回归修正一次)
- 小物体差:anchor和scale不够多样。
- 不规则物体差:anchor的ratio不够多样。

1x1x30的含义:
两个默认框的预测值
4 xywh (坐标预测), 1, 4 xywh(坐标预测), 1, 20(20个分类预测)
SSD
- 位置:
- 借鉴RPN的anchor Box机制: feature点对应的原图感受野框处生成不同ratio/scale的default box
- 没有候选框!直接对default box做全分类+回归
- 类别:CNN提取特征 + CNN分类
- 多感受野特征词输出:前面层感受野小适合小物件,后面层感受野大适合大物体。

YOLOv2
- 更丰富的default box
- 从数据集统计出default box(k-means);随着k的增大,IOU也增大(高召回率)但是复杂度也在增加,最终选择k=5
- 更灵活的类别预测
- 把预测类别的机制从空间位置(cell)中解耦,由default box同时预测类别和坐标,有效解决物体重叠。

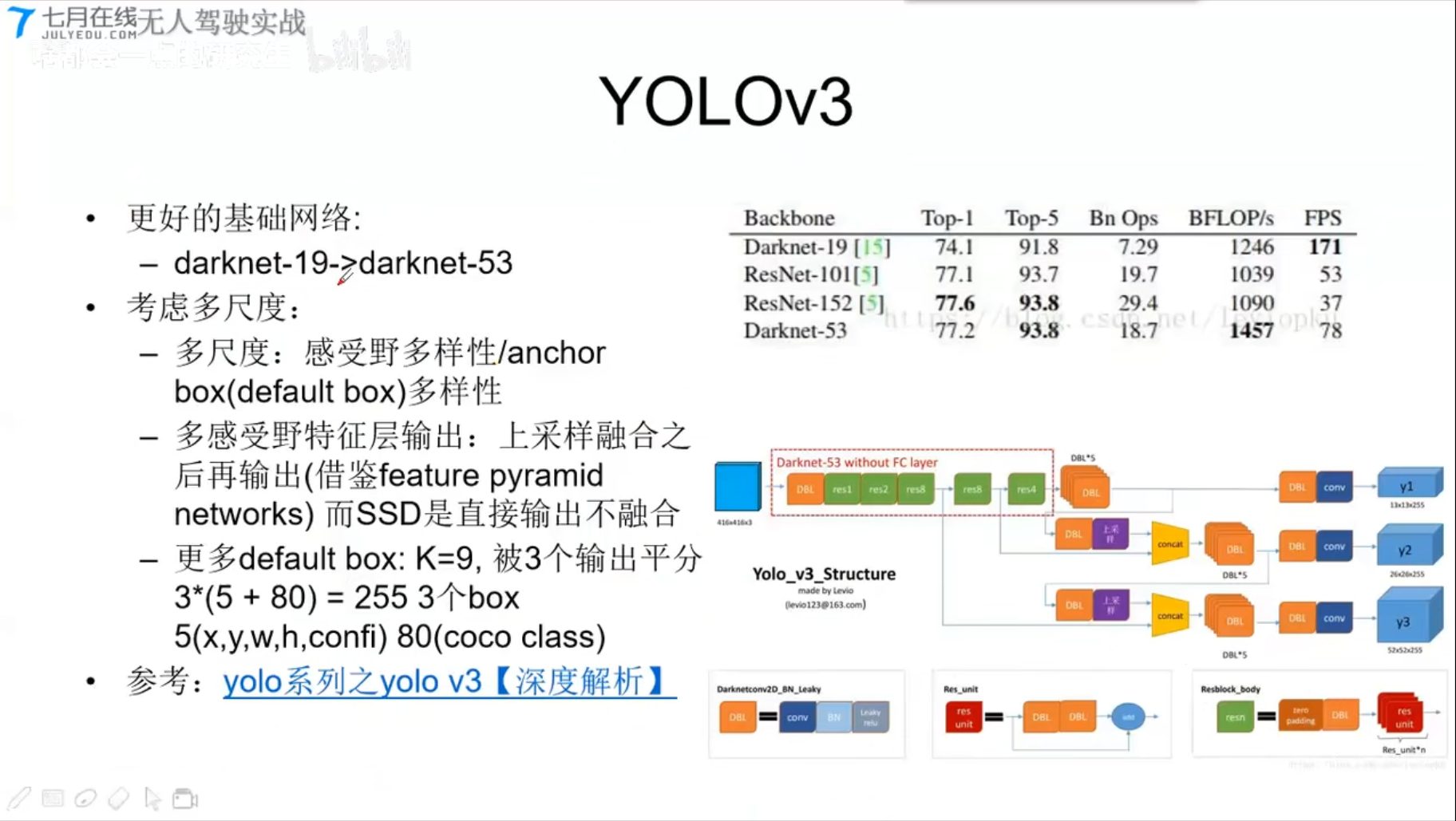
YOLOv3
- 更好的基础网络
- darknet-19 换成darknet-53
- 考虑多尺寸
- 多尺度
- 多感受野特征层输出
- 更多default box:K=9,被3个输出平分3*(5+80)=255;
- 3个box 5(x,y,w,h,confi), 80(coco class)