[TOC]
c++ STL
容器
序列容器
vector
array
queue
deque
list
forward_list
关联容器
map
set
unordered_map
multimap
unordered_multimap
multiset
unordered_multiset
1. vector 初始化
1 2 3 4 5 6 7 8 9 10 vector<int > vec1; vector<float > vec2 (3 ) ; vector<char > vec3 (3 ,'a' ) ; vector<char > vec4 (vec3) ; vector<vector<int >> vecNN (5 );
push_back() insert()
size()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <vector> using namespace std;vector<int > vect1,vect2; vect1. push_back (1 ); vect1. push_back (2 ); vect2. push_back (8 ); vect2. push_back (9 ); vect2. insert (vect2. end (),vect1. begin (),vect1. end ()); vect2. size (); for (int i = 0 ; i < vect2. size (); i++){ cout<<vect2[i]<<endl; }
Delete ~ ~Erase()
erase返回一个迭代器,指向被删除元素之后的位置。如果尝试删除超出向量范围的索引,erase将抛出std::out_of_range异常。
在删除元素后,所有后续元素的索引都会减少。例如,如果你删除了索引为2的元素,索引为3的元素会变成索引为2的元素。
erase会释放被删除元素占用的内存。使用erase后,向量的长度会减少。
1 2 3 4 5 6 7 8 9 10 11 12 std::vector<int > vec = {1 , 2 , 3 , 4 , 5 }; vec.erase (vec.begin () + 2 ); for (int num : vec) { std::cout << num << " " ; } std::cout << std::endl; vect.erase (std::remove (vect.begin (), vect.end (), id), vect.end ());
find 1 2 3 4 5 6 auto iter = find (vec2. begin (), vec2. end (), 9 );if (iter != vec2. end ()){ cout << "Find IT!" ; }
replace
1 2 std::vector<int > vec = {1 , 2 , 3 , 4 , 5 }; vec[2 ] = 10 ;
find + delete (删除找到的第一个元素)
1 2 3 vector<int > vec = {3 , 4 , 5 , 6 , 7 , 4 }; auto iter = find (vec.begin (), vec.end (), 4 );vec.erase (iter);
find + replace
1 2 3 4 5 6 std::vector<int > vec = {1 , 2 , 3 , 4 , 5 }; for (auto & num : vec) { if (num == 3 ) { num = 10 ; } }
max 1 2 3 4 vector <int > a = { 2 ,4 ,6 ,7 ,1 ,0 ,8 ,9 ,6 ,3 ,2 };auto maxPosition = max_element(a.begin(), a.end());cout << *maxPosition << " at the postion of " << maxPosition - a.begin() <<endl ;
vector TO 数组 1:memcpy 1 2 3 4 5 6 7 8 9 10 vector <char > vec (10 , 'c' ) ; char charray[10 ];memcpy (charray, &vec[0 ], vec.size()*sizeof (vec[0 ])); vector <char > v (arr, arr+sizeof (arr)) memcpy (&vec[0 ], arr, sizeof (arr)) ;
ref baidu wenku
2: std::copy vector to arr 1 2 3 4 vector <int > input ({1 ,2 ,3 ,4 ,5 }) ;int arr[input.size()];std ::copy(input.begin(), input.end(), arr);
ref:: https://www.techiedelight.com/convert-vector-to-array-cpp/
max 1 2 3 vector <int > a = { 2 ,4 ,6 ,7 ,1 ,0 ,8 ,9 ,6 ,3 ,2 };auto maxPosition = max_element(a.begin(), a.end());cout << *maxPosition << " at the postion of " << maxPosition - a.begin() <<endl ;### map
vector 切片 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 std ::vector <int > vector {1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 };std ::vector <int >::const_iterator first1 = vector .begin();std ::vector <int >::const_iterator last1 = vector .begin() + 4 ;std ::vector <int > cut1_vector (first1, last1) ;std ::vector <int >::const_iterator first2 = vector .end() - 4 ;std ::vector <int >::const_iterator last2 = vector .end();std ::vector <int > cut2_vector (first2, last2) ;vector <int > Arrs {1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 }; vector <int >::const_iterator Fist = Arrs.begin() + 1 ; vector <int >::const_iterator Second = Arrs.begin() + 2 ; vector <int > Arr2;Arr2.assign(First,Second);
去重 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 vector <int > vec = {1 , 2 , 3 , 1 , 1 };set <int > s (vec.begin(), vec.end()) ;vec.assign(s.begin(), s.end()); vector <int > vec = {1 , 2 , 3 , 1 , 1 };sort(vec.begin(), vec.end()); vec.erase(unique(vec.begin(), vec.end()), vec.end()); auto ret = std ::remove(vec.begin(), vec.end(), 7 );vec.erase(ret, vec.end());
2. Map 存放的元素都是K-V键值对,并且Key是不能重复的。
构造函数 1 map <int , string > mapStudent;
插入数据 1 2 3 4 mapStudent.insert (pair <int , string>(1 , "student_one" )); mapStudent.insert (map<int , string>::value_type (1 , "student_one" )); mapStudent.insert (make_pair (1 , "student_one" )); mapStudent[1 ] = "student_one" ;
查找 1 2 3 4 5 iter = mapStudent.find (1 ); if (iter != mapStudent.end ()) cout << "Find " << iter->second ; else cout << "Dont not find" ;
遍历 1 2 3 4 5 6 7 8 9 10 11 12 13 map<int , CString> maps; for (int i =0 ; i < maps.size (); i++){ CString s=maps[ i ]; } map<CString, 结构体名> maps; map<CString, 结构体名>::iterator iter; for ( iter=maps.begin (); iter!=maps.end (); iter++){ CString a = iter - > first; 结构体名 p = iter - > second; }
删除与清空元素 1 2 3 4 5 6 7 8 9 iter = mapStudent.find ("123" ); mapStudent.erase (iter); int n = mapStudent.erase ("123" );mapStudent.erase (mapStudent.begin (), mapStudent.end ())
大小 1 int mSize = mapStudent.size ();
原文链接:https://blog.csdn.net/bandaoyu/article/details/87775533
3. unordered_map 存放的元素都是K-V键值对,并且Key是不能重复的。
1 2 3 4 5 #include <unordered_map> #include <tr1/unordered_map> using namespace std::tr1;
建立Hashmap 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 unordered_map<int ,int > Hashmap; unordered_map<int ,int >::iterator it; Hashmap.insert (make_pair <int ,int >(1 ,3 )); Hashmap.insert (make_pair (1 ,3 )); Hashmap[3 ]=1 ; it = Hashmap.begin () it = Hashmap.end () Hashmap.size () Hashmap.empty () Hashmap.clear () it = Hashmap.find (2 ) if (Hashmap.find (2 )!=Hashmap.end ()) Hashmap.count (1 ) Hashmap1. swap (Hashmap2); swap (Hashmap1,Hashmap2);
遍历Map 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 unordered_map<int , int > Hashmap; for (auto p : Hashmap) { int front = p.first; int end = p.second; } unordered_map<int , int > Hashmap; for (auto it=Hashmap.begin ();it!=Hashmap.end ();it++){ int front = it->first; int end = it->second; } unordered_map<int ,int > hash; unordered_map<int ,int >::iterator it; it = hash.begin (); while (it != hash.end ()){ int front= it->first; int end = it->second; it++; }
辨析.map VS unordered_map 内部实现机理不同map : map内部实现了⼀个红⿊树(红⿊树是⾮严格平衡⼆叉搜索树,⽽AVL是严格平衡⼆叉搜索树),红⿊树具有⾃动排序的功能,因此map内部的所有元素都是有序的,红⿊树的每⼀个节点都代表着map的⼀个元素。因此,对于map进⾏的查找,删除,添加等⼀系列的操作都相当于是对红⿊树进⾏的操作。map中的元素是按照⼆叉搜索树(⼜名⼆叉查找树、⼆叉排序树,特点就是左⼦树上所有节点的键值都⼩于根节点的键值,右⼦树所有节点的键值都⼤于根节点的键值)存储的,使⽤中序遍历可将键值按照从⼩到⼤遍历出来。
unordered_map : 内部实现了⼀个哈希表(也叫散列表,通过把关键码值映射到Hash表中⼀个位置来访问记录,查找的时间复杂度可达到O(1),其在海量数据处理中有着⼴泛应⽤)。因此,其元素的排列顺序是⽆序的。
map
特点
map
有序性,这是map结构最⼤的优点,其元素的有序性在很多应⽤中都会简化很多的操作
unorder_map
优点: 因为内部实现了哈希表,因此其查找速度⾮常的快
总结: 内存占有率的问题 就转化成红⿊树 VS hash表 , 还是unorder_map占⽤的内存要⾼。
但是unordered_map执⾏效率要⽐map⾼很多
对于unordered_map或unordered_set容器,其遍历顺序与创建该容器时输⼊的顺序不⼀定相同,因为遍历是按照哈希表从前往后依次遍历的
map和unordered_map的使⽤
unordered_map的⽤法和map是⼀样的,提供了 insert,size,count等操作,并且⾥⾯的元素也是以pair类型来存贮的。
其底层实现是完全不同的,上⽅已经解释了,但是就外部使⽤来说却是⼀致的。
4. set 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 std ::set <int > myset{1 , 2 , 3 , 4 , 5 };int arr[] = {1 , 2 , 3 , 4 , 5 };std ::set <int > myset (arr, arr+5 ) ;std ::set <int > myset;myset.insert(1 ); myset.insert(2 ); auto cnt = myset.erase(2 ); myset.clear(); for (std ::set <int >::iterator it = myset.begin(); it != myset.end(); it++) { std ::cout << *it << " " ; } for (auto it = myset.rbegin(); it != myset.rend(); it++) { std ::cout << *it << " " ; } std ::set <int > myset;myset.insert(2 ); myset.insert(4 ); myset.insert(6 ); std ::cout << myset.count(4 ) << "\n" ; std ::cout << myset.count(8 ) << "\n" ; std ::set <int > myset = {2 , 4 , 6 };auto search = myset.find(2 );if (search != myset.end()) { std ::cout << "Found " << *search << "\n" ; } else { std ::cout << "Not found\n" ; } if (myset.empty()) cout << "empty set " << endl ;
https://shengyu7697.github.io/std-set/
排列组合 算法-递归法实现排列组合C++
通用 排列/组合 函数(c++实现)
全排列(stl) 从n个不同元素中任取m(m≤n)个元素,按照一定的顺序排列起来,叫做从n个不同元素中取出m个元素的一个排列。当m=n时所有的排列情况叫全排列 。如果这组数有n个,那么全排列数为n!个。
比如a,b,c的全排列一共有3!= 6 种 分别是{a, b, c}、{a, c, b}、{b, a, c}、{b, c, a}、{c, a, b}、{c, b, a}。
api:
prev_permutation
next_permutation
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <iostream> #include <algorithm> using namespace std;int main () int arr[] = {3 ,2 ,1 }; cout<<"用prev_permutation对3 2 1的全排列" <<endl; do { cout << arr[0 ] << ' ' << arr[1 ] << ' ' << arr[2 ]<<'\n' ; } while (prev_permutation (arr,arr+3 ) ); int arr1[] = {1 ,2 ,3 }; cout<<"用next_permutation对1 2 3的全排列" <<endl; do { cout << arr1[0 ] << ' ' << arr1[1 ] << ' ' << arr1[2 ] <<'\n' ; } while (next_permutation (arr1,arr1+3 ) ); return 0 ; }
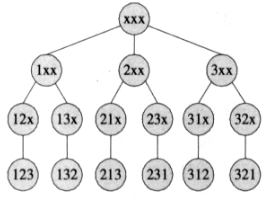
全排列递归思路 我们可以将这个排列问题画成图形表示,即排列枚举树,比如下图为{1,2,3}的排列枚举树,此树和我们这里介绍的算法完全一致;
算法思路:
(1)n个元素的全排列=(n-1个元素的全排列)+(另一个元素作为前缀);
(2)出口:如果只有一个元素的全排列,则说明已经排完,则输出数组;
(3)不断将每个元素放作第一个元素,然后将这个元素作为前缀,并将其余元素继续全排列,等到出口,出口出去后还需要还原数组;
排列(递归) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 #include <iostream> #include <vector> using namespace std ; class Permutation { private: int resultCount_ = 0 ; public: void breakPassword (vector <string > result, vector <string > candidate) { int len = candidate.size(); if (0 == len) { outputResult(result); resultCount_++; return ; } for (int i = 0 ; i < len; i++) { vector <string > resultNew; vector <string > candidateLeft; resultNew = result; resultNew.push_back(candidate[i]); candidateLeft = candidate; vector <string >::iterator it = candidateLeft.begin(); candidateLeft.erase(it + i); breakPassword(resultNew, candidateLeft); } } void outputResult (vector <string > result) { for (unsigned int i = 0 ; i < result.size(); i++) { cout << result[i]; } cout << endl ; } int getResultCount () { return resultCount_; } }; int main (void ) { vector <string > fourAlphabetString = {"a" , "b" , "c" , "d" , "e" }; vector <string > res; Permutation test; test.breakPassword(res, fourAlphabetString); cout << "可能的密码形式:" ; cout << test.getResultCount() << "种" << endl ; }
组合(数组) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <iostream> #include <string> #include <vector> using namespace std ; vector <string > &combination (vector <string > &res, const size_t &choose, string &working, const size_t &pos) { if (choose > working.size() - pos) return res; for (size_t i = pos; i != working.size(); ++i) { working[i] = '0' ; } if (choose == 0 || pos == working.size()) { res.push_back(working); return res; } working[pos] = '1' ; combination(res, choose - 1 , working, pos + 1 ); working[pos] = '0' ; combination(res, choose, working, pos + 1 ); return res; } int main () { vector <string > res; const size_t choose = 3 ; string working (5 , '0' ) ; combination(res, choose, working, 0 ); for (size_t i = 0 ; i != res.size(); ++i) { cout << res[i] << '\t' ; for (size_t j = 0 ; j != working.size(); ++j) { if (res[i][j] == '1' ) { cout << j + 1 << ' ' ; } } cout << endl ; } return 0 ; }
组合(stl, vector) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 #include <iostream> #include <vector> #include <algorithm> #include <boost/assign.hpp> #include <boost/function.hpp> using namespace std ; using namespace boost; using namespace boost::assign; inline void print_ (int t) {cout <<t<<" " ;}inline void print (vector <int >& vec) { for_each(vec.begin(),vec.end(),print_); cout <<endl ; } void test1 () { vector <int > vec; vec += 1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ; sort(vec.begin(),vec.end()); int i = 0 ; do { print(vec); i++; } while (next_permutation(vec.begin(),vec.end())); std ::cout <<i<<std ::endl ; } size_t test2 (int n,int m,boost::function<void (std ::vector <int >& vec)> fn) { vector <int > p,set ; p.insert(p.end(),m,1 ); p.insert(p.end(),n-m,0 ); for (int i = 0 ;i != p.size();++i) set .push_back(i+1 ); vector <int > vec; size_t cnt = 0 ; do { for (int i = 0 ;i != p.size();++i) if (p[i]) vec.push_back(set [i]); fn(vec); cnt ++; vec.clear(); }while (prev_permutation(p.begin(), p.end())); return cnt; } int main () { std ::cout <<test2(20 ,3 ,print)<<std ::endl ; return 0 ; }
组合(class,递归) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <cmath> #include <iostream> #include <vector> using namespace std ; template<typename T> class Combination { private: const int firstPrize; const int secondPrize; const int thirdPrize; public: Combination(int x, int y, int z) : firstPrize(x), secondPrize(y), thirdPrize(z) { } void rewardMethods (vector <T> result, vector <T> candidate) { unsigned int len = thirdPrize + secondPrize + firstPrize; if (result.size() == len) { resultOutput(result); return ; } else { for (unsigned int i = 0 ; i < candidate.size(); i++) { vector <int > resultNew = result; resultNew.push_back(candidate[i]); vector <int > candidateNew; copyElem(candidate, candidateNew, i + 1 ); rewardMethods(resultNew, candidateNew); } } } void copyElem (vector <T>& input, vector <T>& output, int i) { vector <int >::iterator it = input.begin() + i; for (; it < input.end(); it++) { output.push_back(*it); } } void resultOutput (vector <T> res) { for (unsigned int i = 0 ; i < res.size(); i++) { if (i == thirdPrize) cout << '*' ; if (i == thirdPrize + secondPrize) cout << '*' ; cout << res[i] << ' ' ; } cout << endl ; } }; int main (void ) { Combination <int > test(1 , 2 , 3 ); vector <int > res; vector <int > candidate; for (unsigned int i = 0 ; i < 10 ; i++) { candidate.push_back(i + 1 ); } test.rewardMethods(res, candidate); }
可重复组合(运行Pass)
如果用f(n, k)表示P(n, k)中的组合数,那么有:
此外,有公式f(n, k) = C(n + k -1, k)(表示n+k-1选k的组合数,没有重复元素),这可以用归纳法证明,这里就不啰嗦了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 template <typename ElemType> void CalcRepeatableCombination (const ElemType elements[], int num, int k, vector <ElemType> &pre, vector <vector <ElemType>> &result) { if (k == 1 ) { for (int i = 0 ; i < num; i++) { vector <ElemType> tmp (pre.begin(), pre.end()) ; tmp.push_back(elements[i]); result.push_back(tmp); } return ; } if (num == 1 ) { vector <ElemType> tmp (pre.begin(), pre.end()) ; for (int i = 0 ; i < k; i++) { tmp.push_back(elements[0 ]); } result.push_back(tmp); return ; } pre.push_back(elements[0 ]); CalcRepeatableCombination(elements, num, k - 1 , pre, result); pre.pop_back(); CalcRepeatableCombination(elements + 1 , num - 1 , k, pre, result); } template <typename ElemType> void CalcRepeatableCombination (const ElemType elements[], int num, int k, vector <vector <ElemType>> &result) { cout << " num=" << num << " k=" << k << endl ; assert(k >= 1 ); vector <ElemType> one; CalcRepeatableCombination(elements, num, k, one, result); } int main () { char elements[] = {'a' , 'b' , 'c' , 'd' }; vector <char > com_r; CalcRepeatableCombination(elements, 4 , 3 , com_r); }