目标
1.理解针孔相机的模型、内参与径向畸变参数。
2.理解一个空间点如何投影到相机成像平面。
3.掌握 OpenCV 的图像存储与表达方式。
4.学会基本的摄像头标定方法。
在以相机为主的视觉SLAM中,观测主要是指相机成像的过程。
三维世界中的一个物体反射或发出的光线,穿过相机光心后,投影在相机的成像平面上。相机的感光器件接收到光线后,产生测量值,就得到了像素,形成了我们见到的照片。
1、相机模型
相机将三维世界中的坐标点(单位为米)映射到二维图像平面(单位为像素)的过程能够用一个几何模型进行描述,称为针孔模型,它描述了一束光线通过针孔之后,在针孔背面投影成像的关系。同时,由于相机镜头上的透镜的存在,使得光线投影到成像平面的过程中会产生畸变。因此,我们使用针孔和畸变两个模型来描述整个投影过程。这两个模型能够把外部的三维点投影到相机内部成像平面,构成相机的内参数(Intrinsics)。
1.1 针孔相机模型
初中物理的蜡烛投影实验:在一个暗箱的前方放着一支点燃的蜡烛,蜡烛的光透过暗箱上的一个小孔投影在暗箱的后方平面上,并在这个平面上形成一个倒立的蜡烛图像。小孔模型能够把三维世界中的蜡烛投影到一个二维成像平面。同理,可以用这个简单的模型来解释相机的成像过程。对这个简单的针孔模型进行几何建模。设 O − x − y − z 为相机坐标系,z 轴指向相机前方,x 向右,y 向下。O为摄像机的光心,也是针孔模型中的针孔。现实世界的空间点P,经过小孔O投影之后,落在物理成像平面 O′ − x′ − y′ 上,成像点为 P′。设 P 的坐标为 [X,Y,Z]T,P′ 为 [X′,Y′,Z′]T,设物理成像平面到小孔的距离为f(焦距)。那么,根据三角形相似关系,有:
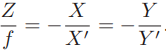
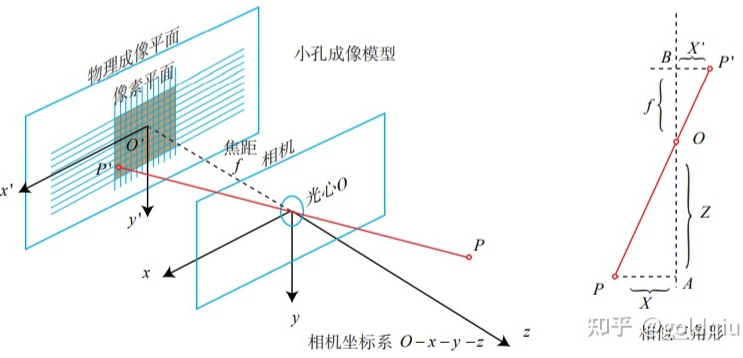
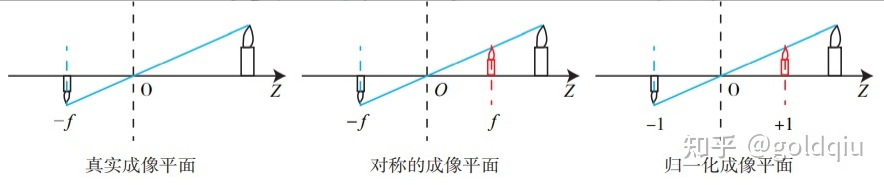
其中负号表示成的像是倒立的。不过,实际相机得到的图像并不是倒像,可以等价地把成像平面对称地放到相机前方,和三维空间点一起放在摄像机坐标系的同一侧,如图所示。
把公式中的负号去掉,X′,Y′ 放到等式左侧,整理得:
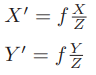
这描述了点 P和它的像之间的空间关系。不过,在相机中最终获得的是一个个的像素,这还需要在成像平面上对像进行采样和量化。为了描述传感器将感受到的光线转换成图像像素的过程,设在物理成像平面上固定着一个像素平面 o − u − v,在像素平面有P′的像素坐标:[u,v]T。
像素坐标系通常的定义方式是:原点o′位于图像的左上角,u 轴向右与 x 轴平行,v 轴向下与 y 轴平行。像素坐标系与成像平面之间,相差了一个缩放和一个原点的平移。设像素坐标在 u 轴上缩放了 α 倍,在 v 上缩放了 β 倍。同时,原点平移了 [cx,cy]T。那么,P′ 的坐标与像素坐标[u,v]T 的关系为:
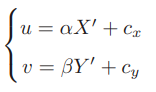
代入式
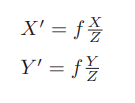
把 αf 合并成 fx,把 βf 合并成 fy,得:
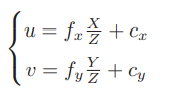
其中,f 的单位为米,α,β 的单位为像素/米,所以 fx,fy 和 cx,cy 的单位为像素。写成矩阵形式:
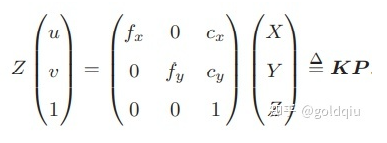
K矩阵称为相机的内参数矩阵(Camera Intrinsics)。通常相机的内参在出厂之后是固定的,不会在使用过程中发生变化。但有时需要自己确定相机的内参,也就是所谓的标定。
(单目棋盘格张正友标定法[25]Z. Zhang, “Flexible camera calibration by viewing a plane from unknown orientations,” in Computer Vision, 1999. The Proceedings of the Seventh IEEE International Conference on, vol. 1, pp. 666–673, Ieee, 1999.)
前面内参公式中的P是在相机坐标系下的坐标。由于相机在运动,所以P是相机的世界坐标(记为Pw)根据相机的当前位姿变换到相机坐标系下的结果。相机的位姿由它的旋转矩阵R和平移向量t来描述。那么有:
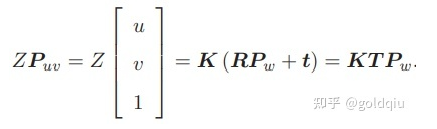
后一个式子隐含了一次齐次坐标到非齐次坐标的转换。它描述了P的世界坐标到像素坐标的投影关系。相机的位姿R,t称为相机的外参数(Camera Extrinsics) 。 相比于不变的内参,外参会随着相机运动发生改变,同时也是 SLAM 中待估计的目标,代表着机器人的轨迹。 式子表明,可以把一个世界坐标点先转换到相机坐标系,再除掉它最后一维(Z)的数值(即该点距离相机成像平面的深度),这相当于把最后一维进行归一化处理,得到点 P 在相机归一化平面上的投影:
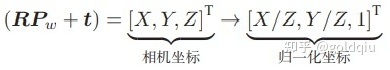
归一化坐标可看成相机前方z=1处的平面上的一个点,这个 z = 1 平面也称为归一化平面。归一化坐标再左乘内参就得到了像素坐标,所以可以把像素坐标 [u,v]T 看成对归一化平面上的点进行量化测量的结果。从这个模型中可以看出,对相机坐标同时乘以任意非零常数,归一化坐标都是一样的,这说明点的深度在投影过程中被丢失了,所以单目视觉中没法得到像素点的深度值。
**注:**1. 相机输出的图像并不是倒像,但相机自身会翻转这张图像,所以实际得到的是正像,也就是对称的成像平面上的像。尽管从物理原理来说,小孔成像应该是倒像。
2.在机器人或自动驾驶车辆中,外参也可以解释成相机坐标系到机器人本体坐标系之间的变换。
1.2 畸变
为了获得好的成像效果,在相机的前方加了透镜。透镜的加入对成像过程中光线的传播会产生新的影响:一是透镜自身的形状对光线传播的影响,引起的畸变(Distortion,也叫失真)称为径向畸变。在针孔模型中,一条直线投影到像素平面上还是一条直线。可是,在实际拍摄的照片中,摄像机的透镜往往使得真实环境中的一条直线在图片中变成了曲线 。越靠近图像的边缘,这种现象越明显。由于实际加工制作的透镜往往是中心对称的,这使得不规则的畸变通常径向对称。它们主要分为两大类:桶形畸变和枕形畸变。
桶形畸变是由于图像放大率随着与光轴之间的距离增加而减小,而枕形畸变则恰好相反。在这两种畸变中,穿过图像中心和光轴有交点的直线还能保持形状不变。
二是在机械组装过程中,透镜和成像平面不可能完全平行,这也会使得光线穿过透镜投影到成像面时的位置发生变化,这引入切向畸变。
用数学形式对两者进行描述。省略具体过程,
对于相机坐标系中的一点P,能够通过 5 个畸变系数找到这个点在像素平面上的正确位置:
- 将三维空间点投影到归一化图像平面。设它的归一化坐标为 [x,y]T。
- 对归一化平面上的点计算径向畸变和切向畸变。
- 将畸变后的点通过内参数矩阵投影到像素平面,得到该点在图像上的正确位置。
在实际应用中,可以灵活选择纠正模型,比如只选择 k1,p1,p2 这 3 项等。
实际的图像系统中,学者们提出了很多其他的模型,比如相机的仿射模型和透视模型等,同时也存在很多其他类型的畸变。视觉 SLAM 中一般都使用普通的摄像头,针孔模型及径向畸变和切向畸变模型已经足够。 当一个图像去畸变之后,我们就可以直接用针孔模型建立投影关系,不用考虑畸变了。
小结单目相机的成像过程:
- 首先,世界坐标系下有一个固定的点 P,世界坐标为Pw。
- 由于相机在运动,它的运动由 R,t 或变换矩阵T∈SE(3) 描述。P 的相机坐标为 P˜c =RPw + t。
- 这时的 P˜c 的分量为 X,Y,Z,把它们投影到归一化平面 Z = 1 上,得到 P 的归一化坐标:Pc = [X/Z,Y /Z,1]T 。
- 有畸变时,根据畸变参数计算Pc 发生畸变后的坐标。
- 最后,P 的归一化坐标经过内参后,对应到它的像素坐标:Puv = KPc。 一共有四种坐标:世界坐标、相机坐标、归一化坐标和像素坐标。
1.3 双目相机模型
对于单目相机而言,仅根据一个像素,我们无法确定这个空间点的具体位置。这是因为,从相机光心到归一化平面连线上的所有点,都可以投影至该像素上(相当于没有了Z轴维度)。只有当P的深度确定时(比如通过双目或 RGB-D 相机),我们才能确切地知道它的空间位置。如图所示。
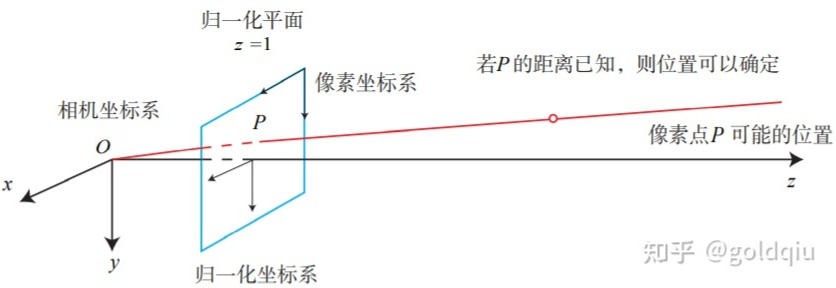
测量像素距离(或深度)的方式有很多种,比如人眼可以根据左右眼看到的景物差异(视差)来判断物体离我们的距离。双目相机的原理一样:通过同步采集左右相机的图像,计算图像间视差,来估计每一个像素的深度。
双目相机一般由左眼相机和右眼相机两个水平放置的相机组成。在左右双目相机中,我们可以把两个相机都看作针孔相机。它们是水平放置的,意味着两个相机的光圈中心都位于 x 轴上。两者之间的距离称为双目相机的基线(Baseline,记作 b),是双目相机的重要参数。
考虑一个空间点 P,它在左眼相机和右眼相机各成一像,记作 PL,PR。由于相机基线的存在,这两个成像位置是不同的。理想情况下,由于左右相机只在 x 轴上有位移,因此 P 的像也只在 x 轴(对应图像的u轴)上有差异。记它的左侧坐标为 uL,右侧坐标为 uR,几何关系如图所示。
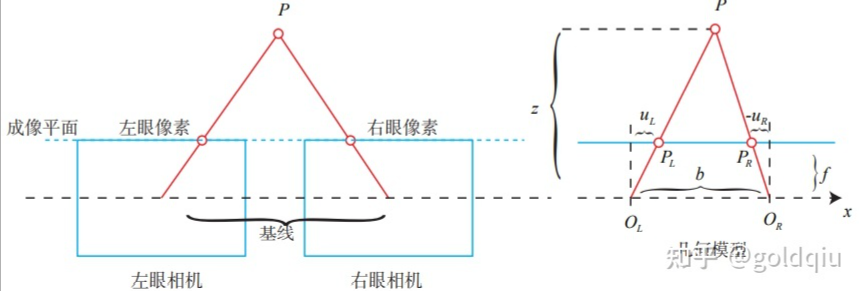
根据 △PPLPR 和 △POLOR 的相似关系,整理得:
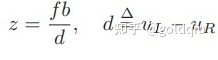
双目相机的成像模型:OL,OR 为左右光圈中心,方框为成像平面,f 为焦距。uL 和 uR 为成像平面的坐标。注意,按照图中坐标定义,uR 应该是负数,所以图中标出的距离为 −uR。
其中 d 定义为左右图的横坐标之差,称为视差(Disparity)。根据视差,我们可以估计一个像素与相机之间的距离。视差与距离成反比:视差越大,距离越近。同时,由于视差最小为一个像素,于是双目的深度存在一个理论上的最大值,由 fb 确定。可以看到,当基线越长时,双目能测到的最大距离就会越远。类似人眼在看非常远的物体时(如很远的飞机),通常不能准确判断它的距离。
视差 d 的计算比较困难,需要确切地知道左眼图像某个像素出现在右眼图像的哪一个位置(即对应关系)。当想计算每个像素的深度时,其计算量与精度都将成为问题,而且只有在图像纹理变化丰富的地方才能计算视差。由于计算量的原因,双目深度估计仍需要使用 GPU 或FPGA 来实时计算。
1.4 RGB-D相机模型
RGB-D 相机是主动测量每个像素的深度。目前的 RGB-D 相机按原理可分为两大类:
- 红外结构光(Structured Light): Kinect 1 代、Project Tango 1 代、Intel RealSense 等。
- 通过飞行时间法(Time-of-flight,ToF):Kinect 2 代和一些现有的 ToF 传感器等。
无论是哪种类型,RGB-D 相机都需要向探测目标发射一束光线(通常是红外光)。在结构光原理中,相机根据返回的结构光图案,计算物体与自身之间的距离。而在 ToF 原理中,相机向目标发射脉冲光,然后根据发送到返回之间的光束飞行时间,确定物体与自身之间的距离。ToF原理的相机和激光雷达十分相似,只不过激光雷达是通过逐点扫描来获取这个物体的距离,而ToF相机则可以获得整个图像的像素深度。
在测量深度之后,RGB-D 相机通常按照生产时的相机摆放位置,自己完成深度与彩色图像素之间的配对,输出一一对应的彩色图和深度图。可以在同一个图像位置,读取到色彩信息和距离信息,计算像素的 3D 相机坐标,生成点云(Point Cloud)。对 RGB-D 数据,既可以在图像层面进行处理,也可在点云层面处理。
RGB-D 相机能够实时地测量每个像素点的距离。但用红外光进行深度值测量的 RGB-D 相机,容易受到日光或其他传感器发射的红外光干扰,因此不能在室外使用。在没有调制的情况下,同时使用多个 RGB-D 相机时也会相互干扰。对于透射材质的物体,因为接收不到反射光,所以无法测量这些点的位置。
2、图像
1 | st=>start: 现实世界 |
相机把三维世界中的信息转换成了一张由像素组成的照片,存储在计算机中,作为后续处理的数据来源。在数学中,图像可以用一个矩阵来描述;而在计算机中,它们占据一段连续的磁盘或内存空间,可以用二维数组来表示。
最简单的图像——灰度图:每个像素位置 (x,y) 对应一个灰度值 I,一张宽度为 w、高度为 h 的图像,数学上可以记为一个函数:
$$
I(x,y) : R^2 \to R
$$
其中 (x,y) 是像素的坐标。然而,计算机并不能表达实数空间,所以需要对下标和图像读数在某个范围内进行量化(类似于模拟到数字的概念)。在常见的灰度图中,用 0~255 的整数(一个 unsigned char或1 个字节)来表达图像的灰度读数。那么,一张宽度为 640 像素、高度为 480 像素分辨率的灰度图就可以表示为:
1 | unsigned char image[480][640] //二维数组表达图像 |
在程序中,图像以二维数组形式存储。它的第一个下标是指数组的行,而第二个下标则是列。在图像中,数组的行数对应图像的高度,而列数对应图像的宽度。
当访问某一个像素时,需要指明它所处的坐标。像素坐标系原点位于图像的左上角,X 轴向右,Y 轴向下(也就是u,v* 坐标)。如果还有第三个轴—Z 轴,根据右手法则,Z 轴向前。这种定义方式是与相机坐标系一致的。图像的宽度或列数,对应着 X 轴;而图像的行数或高度,则对应着它的 Y 轴。
根据这种定义方式,访问一个位于 x,y 处的像素,那么在程序中应该是:
1 | unsigned char pixel = image[y][x]; //访问图像像素 |
它对应着灰度值 I(x,y) 的读数。
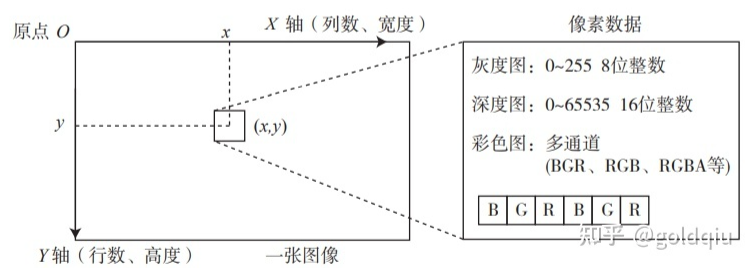
在 RGB-D 相机的深度图中,记录了各个像素与相机之间的距离。这个距离通常是以毫米为单位,而 RGB-D 相机的量程通常在十几米左右,超过了 255。这时会采用 16 位整数(unsigned short)来记录深度图的信息,也就是位于 0~65535 的值。换算成米的话,最大可以表示 65 米,足够 RGB-D 相机使用。
彩色图像的表示则需要通道(channel)的概念。在计算机中,用红色、绿色和蓝色这三种颜色的组合来表达任意一种色彩。于是对于每一个像素,就要记录其 R、G、B 三个数值,每一个数值就称为一个通道。最常见的彩色图像有三个通道,每个通道都由 8 位整数表示。在这种规定下,一个像素占据 24 位空间。通道的数量、顺序都是可以自由定义的。在 OpenCV 的彩色图像中,通道的默认顺序是 B、G、R。也就是说,当得到一个 24 位的像素时,前 8 位表示蓝色数值,中间 8 位为绿色,最后 8 位为红色。如果还想表达图像的透明度,就使用 R、G、B、A 四个通道。
3 实践:计算机中的图像(OpenCV)
3.1 OpenCV 的基础使用方法
OpenCV提供了大量的开源图像算法,是计算机视觉中使用极广的图像处理算法库。
在Ubuntu下,有两种安装方式:
- 从源代码安装,指从OpenCV网站下载所有的OpenCV源代码,并在机器上编译安装,以便使用。好处是可以选择的版本比较丰富,而且能看到源代码,不过需要编译。还可以调整一些编译选项,匹配编程环境(例如,需不需要GPU加速等),还可以使用一些额外的功能。 源代码安装OpenCV 目前维护了两个主要版本,分为 OpenCV2.4系列和 OpenCV3系列。
- 只安装库文件,指通过Ubuntu来安装由Ubuntu社区人员已经编译好的库文件,这样无须编译。
源代码安装,安装依赖项:
1 | sudo apt−get install build−essential libgtk2.0−dev libvtk5−dev libjpeg−dev libtiff4−dev libjasper−dev libopenexr−dev libtbb−dev |
OpenCV 的依赖项很多,缺少某些编译项会影响它的部分功能,但可能不会用上。OpenCV 会在 cmake 阶段检查依赖项是否会安装,并调整自己的功能。如果电脑上有GPU并且安装了相关依赖项,OpenCV也会把GPU加速打开。
安装:
1 | cmake .. |
安装后,OpenCV 默认存储在/usr/local 目录下
操作 OpenCV 图像
slambook/ch5/imageBasics/imageBasics.cpp
在该例程中操作有:图像读取、显示、像素遍历、复制、赋值等。编译该程序时,需要在CMakeLists.txt中添加 OpenCV的头文件,然后把程序链接到库文件上,还使用了C++11标准(如 nullptr 和 chrono)。
编译运行:
报错:
1 | CMakeFiles/joinMap.dir/joinMap.cpp.o:在函数‘fmt::v7::detail::compile_parse_context<char, fmt::v7::detail::error_handler>::char_type const* fmt::v7::detail::parse_format_specs<Eigen::Transpose<Eigen::Matrix<double, 4, 1, 0, 4, 1> >, fmt::v7::detail::compile_parse_context<char, fmt::v7::detail::error_handler> >(fmt::v7::detail::compile_parse_context<char, fmt::v7::detail::error_handler>&)’中: |
需要将之前安装的fmt库链接joinMap.cpp,rgbd文件夹中的cmakelists如下:
1 | find_package(Sophus REQUIRED) |
在图像中,鼠标点击图像中的每个点都能在左下角得到UV坐标值和RGB三通道值。
函数解析如下:
- cv::imread:函数读取图像,并把图像和基本信息显示出来。
- OpenCV 提供了迭代器,可以通过迭代器遍历图像的像素。cv::Mat::data 提供了指向图像数据开头的指针,可以直接通过该指针自行计算偏移量,然后得到像素的实际内存位置。
- 复制图像中直接赋值是浅拷贝,并不会拷贝数据,而clone方法是深拷贝,会拷贝数据,这在图像存取中会经常用到。
- 在编程过程中碰到图像的旋转、插值等操作,自行查阅函数对应的文档,以了解它们的原理与使用方式。
注:1. cv::Mat 亦是矩阵类,除了表示图像之外,我们也可以用它来存储位姿等矩阵数据,但一般还是使用eigen,更快一些。
- cmake默认编译的是debug模式,如果使用release模式会快很多。
3.2 图像去畸变
OpenCV 提供了去畸变函数 cv::Undistort(),这个例程从公式出发计算了畸变前后的图像坐标(代码中有内参数据)。
slambook/ch5/imageBasics/undistortImage.cpp

可以看到去畸变前后图像差别还是蛮大的。
4 实践:3D 视觉
4.1 双目视觉(slam2)
在stereo文件夹中,有左右目的图像和对应代码。其中代码计算图像对应的视差图,然后再计算各像素在相机坐标系下的坐标,它们共同构成点云。
slambook/ch5/stereoVision/stereoVision.cpp
运行如下:(下面的第二个图片是视差图)


例程中调用了OpenCV实现的SGBM算法(Semi-global Batch Matching)[26] H. Hirschmuller, “Stereo processing by semiglobal matching and mutual information,” IEEE Transactions on pattern analysis and machine intelligence, vol. 30, no. 2, pp. 328–341, 2008.
计算左右图像的视差,然后通过双目相机的几何模型把它变换到相机的3D空间中。SGBM 使用了来自网络的经典参数配置,主要调整了最大和最小视差。视差数据结合相机的内参、基线,即能确定各点在三维空间中的位置。感兴趣可以阅读相关的参考文献[27, 28]。
[27] D. Scharstein and R. Szeliski, “A taxonomy and evaluation of dense two-frame stereo correspondence algorithms,” International journal of computer vision, vol. 47, no. 1-3, pp. 7–42, 2002.
[28] S. M. Seitz, B. Curless, J. Diebel, D. Scharstein, and R. Szeliski, “A comparison and evaluation of multi-view stereo reconstruction algorithms,” in null, pp. 519–528, IEEE, 2006.
4.2 RGB-D 视觉
RGB-D相机能通过物理方法获得像素深度信息。如果已知相机的内外参,可以计算任何一个像素在世界坐标系下的位置,从而建立一张点云地图。
位于 slambook/ch5/rgbd 文件夹中有5对图像。在 color/下有 1.png 到 5.png 共 5 张 RGB 图,而在 depth/下有 5 张对应的深度图。同时,pose.txt 文件给出了5张图像的相机外参位姿。位姿记录的形式为平移向量加旋转四元数: [x, y, z, qx, qy, qz, qw], 其中 qw 是四元数的实部。
这一段程序,完成了两件事:(1). 根据内参计算一对 RGB-D图像对应的点云;(2). 根据各张图的相机位姿(也就是外参),把点云加起来,组成地图。
slambook/ch5/rgbd/jointMap.cpp
运行程序如下:

习题
寻找一部相机,标定它的内参。可能会用到标定板, 或者棋盘格。
相机内参的物理意义。如果一部相机的分辨率变为原来的两倍而其他地方不变,它的内参如何变化?
搜索特殊相机(鱼眼或全景相机)的标定方法。它们与普通的针孔模型有何不同?
调研全局快门相机(global shutter)和卷帘快门相机(rolling shutter)的异同。它们在SLAM中有何优缺点?
RGB-D 相机是如何标定的?以 Kinect 为例,需要标定哪些参数?(参照https://github.com/code-iai/iai_kinect2)
除了示例程序演示的遍历图像的方式,还能举出哪些遍历图像的方法?
阅读 OpenCV 官方教程,学习它的基本用法。
习题有代码学习和工程应用的知识,后面实际开发中会很有帮助。