目标:
理解图像特征点的意义,掌握在单张图像中提取出特征点,掌握多副图像匹配特征点的方法
理解对极几何的原理,利用对极几何的约束,恢复图像之间摄像机的三维运动
理解PNP(3D-2D)问题,利用已知三维结构与图像对应关系,求解摄像机的三维运动
理解ICP问题(3D-3D),利用点云匹配关系,求解摄像机的三维运动
理解如何通过三角化,获得二维图像上对应点的三维结构。
| 视觉里程计(VO)算法 | 现状 | |
|---|---|---|
| 特征点法 | 目前的主流算法 | |
| 直接法 | 追赶者的角色 | |
特征点提取算法
| 方法 | ||
|---|---|---|
| 角点 | Harris 角点、FAST 角点 、GFTT 角点 | |
| 局部图像特征 | SIFT 、SURF 、ORB | 速度: ORB < SIFI |
| 关键点 | 描述子 | |
| ORB特征 | Oriented FAST and Rotated BRIEF | BRIEF |
匹配算法
- 暴力匹配
- 汉明距离
- 快速近似最近邻
1 | st=>start: Start |
1、特征点法
一个 SLAM 系统分为前端和后端,其中是视觉SLAM前端也称为视觉里程计(VO)。VO根据相邻图像的信息估计出粗略的相机运动,给后端提供较好的初始值。VO的算法主要分为两个大类:特征点法和直接法。基于特征点法的前端,被认为是视觉里程计的主流方法。它具有稳定,对光照、动态物体不敏感的优势,是目前比较成熟的解决方案。如何提取、匹配图像特征点,然后估计两帧之间的相机运动和场景结构,从而实现一个两帧间视觉里程计。这类算法也称为两视图几何(Two-view geometry)。
1.1 特征点
VO的核心问题是如何根据图像来估计相机运动。然而,图像本身是一个由亮度和色彩组成的矩阵,如果直接从矩阵层面考虑运动估计,将会非常困难。所以,比较方便的做法是:首先,从图像中选取比较有代表性的点。这些点在相机视角发生少量变化后会保持不变,于是能在各个图像中找到相同的点。然后,在这些点的基础上,讨论相机位姿估计问题,以及这些点的定位问题。在经典SLAM模型中称这些点为路标(Landmark)。而在视觉 SLAM 中,路标则是指图像特征(Feature)。其定义为:一组与计算任务相关的信息,计算任务取决于具体的应用。简而言之,特征是图像信息的另一种数字表达形式。一组好的特征对于在指定任务上的最终表现至关重要。数字图像在计算机中以灰度值矩阵的方式存储,所以最简单的单个图像像素也是一种“特征”。但是,在视觉里程计中希望特征点在相机运动之后保持稳定,而灰度值受光照、形变、物体材质的影响严重,在不同图像间变化非常大,不够稳定。理想的情况是,当场景和相机视角发生少量改变时,算法还能从图像中判断哪些地方是同一个点。所以,仅凭灰度值是不够的,需要对图像提取特征点。 特征点是图像里一些特别的地方,可以把图像中的角点、边缘和区块都当成图像中有代表性的地方。不过更容易精确地指出,某两幅图像中出现了同一个角点;同一 个边缘则稍微困难一些,因为沿着该边缘前进,图像局部是相似的;同一个区块则是最困难的。可以发现,图像中的角点、边缘相比于像素区块而言更加“特别”,在不同图像之间的辨识度更强。所以,一种直观的提取特征的方式就是在不同图像间辨认角点,确定它们的对应关系。在这种做法中,角点就是所谓的特征。角点的提取算法有很多,例如Harris 角点、FAST 角点 、GFTT 角点等等。然而,在大多数应用中,单纯的角点依然不能满足很多需求。例如,从远处看上去是角点的地方,当相机走近之后,可能就不显示为角点了。或者,当旋转相机时,角点的外观会发生变化,也就不容易辨认出那是同一个角点。为此,就提出了许多更加稳定的局部图像特征,如著名的SIFT 、SURF 、ORB ,等等。相比于普通角点,这些人工设计的特征点能够拥有如下的性质:
- 可重复性(Repeatability):相同的特征可以在不同的图像中找到。
- 可区别性(Distinctiveness):不同的特征有不同的表达。
- 高效率(Efficiency):同一图像中,特征点的数量应远小于像素的数量。
- 本地性(Locality):特征仅与一小片图像区域相关。
特征点由关键点(Key-point)和描述子(Descriptor)两部分组成。关键点是指该特征点在图像里的位置,有些特征点还具有朝向、大小等信息。描述子通常是一个向量,按照某种人为设计的方式,描述了该关键点周围像素的信息。描述子是按照“外观相似的特征应该有相似的描述子”的原则设计的。因此,只要两个特征点的描述子在向量空间上的距离相近,就可以认为它们是同样的特征点。SIFT(尺度不变特征变换,Scale-Invariant FeatureTransform):充分考虑了在图像变换过程中出现的光照、尺度、旋转等变化,但随之而来的是极大的计算量。 FAST关键点则考虑适当降低精度和鲁棒性,以提升计算的速度,属于计算特别快的一种特征点(没有描述子);而ORB(Oriented FASTand Rotated BRIEF)特征则是改进了 FAST 检测子不具有方向性的问题,并采用速度极快的二进制描述子BRIEF,使整个图像特征提取的环节大大加速。根据作者在论文中所述测试,在同一幅图像中同时提取约 1000 个特征点的情况下,ORB 约要花费 15.3ms,SIFT 约花费 5228.7ms。由此可以看出,ORB在保持了特征子具有旋转、尺度不变性的同时,速度方面提升明显,对于实时性要求很高的SLAM来说是一个很好的选择。大部分特征提取都具有较好的并行性,可以通过 GPU 等设备来加速计算。经过GPU加速后的SIFT,就可以满足实时计算要求。但是,引入GPU将带来整个SLAM成本的提升。在目前的 SLAM方案中,ORB 是质量与性能之间较好的折中。
1.2 ORB特征
ORB特征也由关键点和描述子两部分组成。它的关键点称为“Oriented FAST”,是一种改进的FAST角点。它的描述子称为BRIEF(Binary Robust Independent Elementary Feature)。提取 ORB 特征分为如下两个步骤:
- FAST 角点提取:找出图像中的“角点”。相较于原版的 FAST,ORB中计算了特征点的主方向,为后续的BRIEF描述子增加了旋转不变特性。
- BRIEF 描述子:对前一步提取出特征点的周围图像区域进行描述。ORB 对BRIEF进行了一些改进,主要是指在 BRIEF中使用了先前计算的方向信息。
FAST 关键点
FAST 是一种角点,主要检测局部像素灰度变化明显的地方,以速度快著称。它的思想是:如果一个像素与邻域的像素差别较大(过亮或过暗),那么它更可能是角点。相比于其他角点检测算法,FAST 只需比较像素亮度的大小,十分快捷。它的检测过程如下:

- 在图像中选取像素p,假设它的亮度为Ip。
- 设置一个阈值T (比如,Ip 的20%)。
- 以像素p为中心,选取半径为3的圆上的16个像素点。
- 假如选取的圆上有连续的N个点的亮度大于 Ip + T 或小于 Ip − T,那么像素p可以被认为是特征点(N通常取12,即为 FAST-12。其他常用的 N 取值为 9 和 11,它们分别被称为FAST-9 和 FAST-11)。
- 循环以上四步,对每一个像素执行相同的操作。
在 FAST-12 算法中,为了更高效,可以添加一项预测试操作,以快速地排除绝大多数不是角点的像素。具体操作为,对于每个像素,直接检测邻域圆上的第 1, 5, 9, 13 个像素的亮度。只有当这 4个像素中有 3 个同时大于 Ip + T 或小于 Ip − T 时,当前像素才有可能是一个角点,否则应该直接排除。这样的预测试操作大大加速了角点检测。此外,原始的 FAST角点经常出现“扎堆”的现象。所以在第一遍检测之后,还需要用非极大值抑制(Non-maximal suppression),在一定区域内仅保留响应极大值的角点,避免角点集中的问题。
FAST特征点的计算仅仅是比较像素间亮度的差异,所以速度非常快,但它也有重复性不强,分布不均匀的缺点。此外,FAST角点不具有方向信息。同时,由于它固定取半径为3的圆,存在尺度问题:远处看着像是角点的地方,接近后看可能就不是角点了。针对FAST角点不具有方向性和尺度的弱点,ORB添加了尺度和旋转的描述。尺度不变性由构建图像金字塔,并在金字塔的每一层上检测角点来实现。而特征的旋转是由灰度质心法(Intensity Centroid)实现的。 金字塔是计算图视觉中常用的一种处理方法,如下图。
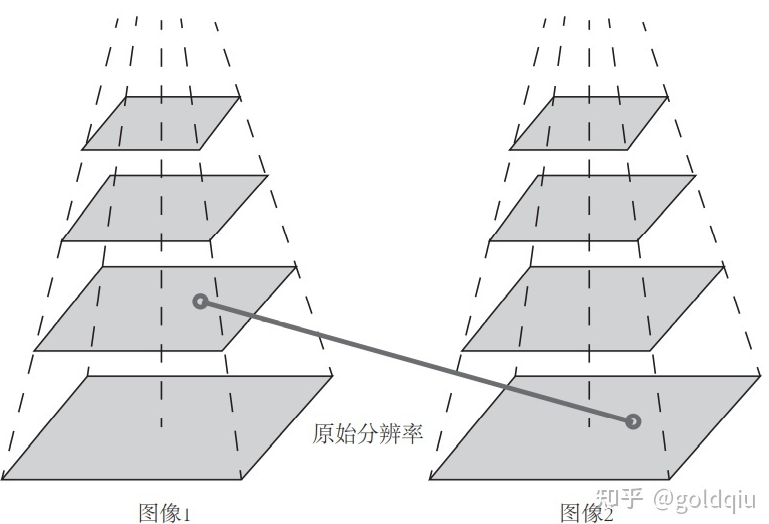
金字塔底层是原始图像。每往上一层,就对图像进行一个固定倍率的缩放,这样就有了不同分辨率的图像。较小的图像可以看成是远处看过来的场景。在特征匹配算法中可以匹配不同层上的图像,从而实现尺度不变性。 例如,如果相机在后退,那么应该能够在上一个图像金字塔的上层和下一个图像的下层中找到匹配。 在旋转方面,计算特征点附近的图像灰度质心。所谓质心是指以图像块灰度值作为权重的中心。其具体操作步骤如下:
- 在一个小的图像块B中,定义图像块的矩为
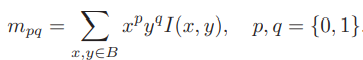
- 通过矩可以找到图像块的质心:
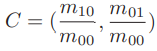
- 连接图像块的几何中心O与质心 C,得到一个方向向量 OC,于是特征点的方向可以定义为
$$
\theta = \arctan(m_{01}/m_{10})
$$
通过以上方法,FAST角点便具有了尺度与旋转的描述,从而大大提升了其在不同图像之间表述的鲁棒性。ORB 中,把这种改进后的FAST称为 Oriented FAST。
注:金字塔是指对图像进行不同层次的降采样,以获得不同分辨率的图像。
BRIEF 描述子
在提取 Oriented FAST 关键点后,对每个点计算其描述子。ORB使用改进的BRIEF特征描述。
BRIEF 是一种二进制描述子,其描述向量由许多个0和1组成,这里的0和1编码了关键点附近两个随机像素(比如 p 和 q)的大小关系:如果 p 比 q 大,则取 1,反之就取 0。如果取了 128 个这样的 p, q,最后就得到128维由 0、1 组成的向量。BRIEF 使用了随机选点的比较,速度非常快,而且由于使用了二进制表达,存储起来也十分方便,适用于实时的图像匹配。原始的 BRIEF描述子不具有旋转不变性,因此在图像发生旋转时容易丢失。而 ORB 在 FAST 特征点提取阶段计算了关键点的方向,所以可以利用方向信息,计算了旋转之后的“Steer BRIEF”特征使ORB 的描述子具有较好的旋转不变性。 由于考虑到了旋转和缩放,使得 ORB 在平移、旋转和缩放的变换下仍有良好的表现。同时,FAST和BREIF的组合也非常高效,使得ORB特征在实时SLAM中非常受欢迎。
1.3 特征匹配
特征匹配是视觉 SLAM 中极为关键的一步,解决了SLAM中的数据关联问题(data association),即确定当前看到的路标与之前看到的路标之间的对应关系。通过对图像与图像或者图像与地图之间的描述子进行准确匹配,可以为后续的姿态估计、优化等操作减轻大量负担。然而,由于图像特征的局部特性,误匹配的情况广泛存在,成为视觉SLAM中制约性能提升的一大瓶颈。部分原因是场景中经常存在大量的重复纹理,使得特征描述非常相似。在这种情况下,仅利用局部特征解决误匹配是非常困难的。
考虑两个时刻的图像。如果在图像It中提取到特征点
$$
x_t^m,m = 1,2…,M
$$
在图像 It+1 中也提取到特征点xnt+1。如何寻找这两个集合元素的对应关系?最简单的特征匹配方法就是暴力匹配(Brute-Force Matcher)。即对每一个特征点 xm t 与所有的 xn t+1 测量描述子的距离,然后排序,取最近的一 个作为匹配点。描述子距离表示了两个特征之间的相似程度,不过在实际运用中还可以取不同的距离度量范数。对于浮点类型的描述子,使用欧氏距离进行度量即可。而对于二进制的描述子(比如BRIEF),往往使用汉明距离(Hamming distance)作为度量——两个二进制串之间的汉明距离,指的是其不同位数的个数。 然而,当特征点数量很大时,暴力匹配法的运算量将变得很大,特别是当想要匹配某个帧和一张地图的时候。这不符合在SLAM中的实时性需求。此时快速近似最近邻(FLANN)算法更加适合于匹配点数量极多的情况。这些匹配算法理论已经成熟,实现上集成到OpenCV了。
[47] M. Muja and D. G. Lowe, “Fast approximate nearest neighbors with automatic algorithm configuration.,” in VISAPP (1), pp. 331–340, 2009.
2、实践:特征提取和匹配
OpenCV集成了多数主流的图像特征,可以很方便地进行调用。
2.1 OpenCV 的 ORB 特征
调用OpenCV来提取和匹配ORB。图像位于slambook2/ch7/下的1.png 和 2.png,可以看到相机发生了微小的运动。程序演示如何提取ORB特征并进行匹配:
slambook/ch7/orb_cv.cpp
首先要安装g2o,github下载20200410版本的:https://github.com/RainerKuemmerle/g2o.git
对ch7文件夹中的cmake工程进行编译,报错:
1 | undefined reference to `vtable for fmt::v7::format_error‘ |
链接上fmt 库:
1 | target_link_libraries("可执行文件" ${Sophus_LIBRARIES} fmt) |
运行结果:

未筛选的匹配中带有大量的误匹配。经过一次筛选之后,匹配数量减少了许多,大多数匹配都是正确的。这里筛选的依据是汉明距离小于最小距离的两倍,这是一种工程上的经验方法。尽管在示例图像中能够筛选出正确的匹配,但仍然不能保证在所有其他图像中得到的匹配都是正确的。因此,在后面的运动估计中,还需要使用去除误匹配的算法。
2.2 手写 ORB 特征
代码:slambook/ch7/orb_self.cpp
运行结果:

在计算中用256位的二进制描述,即对应到8个32位的unsigned int数据,用 typedef 将它表示成 DescType。然后计算 FAST 特征点的角度,再使用该角度计算描述子。此代码中通过三角函数的原理回避了复杂的 arctan 以及 sin、cos 计算,从而达到加速的效果。在 BfMatch 函数中还使用了 SSE 指令集中的_mm_popcnt_u32 函数来计算一个 unsigned int 变量中1的个数,从而达到计算汉明距离的效果。
这个程序中,通过一些简单的算法修改,对ORB的提取加速了数倍。如果对提取特征部分进一步并行化处理,算法还可以有加速的空间。
2.3 计算相机运动
有了匹配好的点对后要根据点对来估计相机的运动。
- 当相机为单目时,只知道2D的像素坐标,因而问题是根据两组2D点估计运动。该问题用对极几何来解决。
- 当相机为双目、RGB-D 时,或者通过某种方法得到了距离信息,那么问题就是根据两组3D点估计运动。该问题通常用 ICP 来解决。
- 如果一组为 3D,一组为 2D,即得到了一些 3D 点和它们在相机的投影位置,也能估计相机的运动。该问题通过 PnP 求解。
3、2D−2D: 对极几何(Epipolar Geometry)
描述的是两幅视图之间的内在射影关系,与外部场景无关,只依赖于摄像机内参数和这两幅试图之间的的相对姿态。
对极几何(Epipolar Geometry)是Structure from Motion问题中,在两个相机位置产生的两幅图像的之间存在的一种特殊几何关系,是sfm问题中2D-2D求解两帧间相机姿态的基本模型。
3.1对极约束
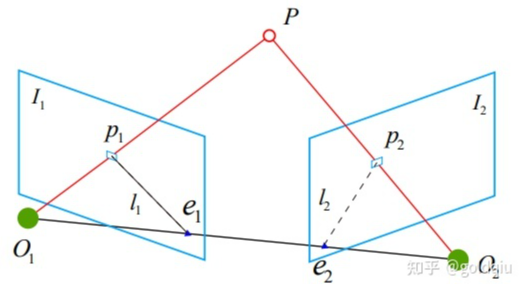
如果有若干对这样的匹配点,就可以通过这些二维图像点的对应关系,恢复出在两帧之间摄像机的运动。求取两帧图像I1, I2之间的运动,设第一帧到第二帧的运动为R,t。两个相机中心分别为O1,O2。如果I1中有一个特征点p1 ,它在I2中对应着特征点p2,两者是通过特征匹配得到的。如果匹配正确,说明它们是同一个空间点在两个成像平面上的投影。首先,连线O1p1和连线O2p2在三维空间中会相交于点P。这时候点O1, O2 ,P三个点可以确定一个平面,称为极平面(Epipolar plane) 。O1O2连线与像平面I1, I2 的交点分别为 e1, e2 。e1, e2 称为极点(Epipoles) ,O1O2被称为基线(Baseline) 。称极平面与两个像平面 I1, I2之间的相交线 L1, L2极线(Epipolar line) 。
直观讲,从第一帧的角度看,射线O1p1是某个像素可能出现的空间位置——因为该射线上的所有点都会投影到同一个像素点。同时,如果不知道P的位置,那么当在第二幅图像上看时,连线e2p2(也就是第二幅图像中的极线)就是P可能出现的投影的位置,也就是射线O1p1在第二个相机中的投影。由于通过特征点匹配确定了p2的像素位置,所以能够推断P的空间位置,以及相机的运动。如果没有特征匹配,就没法确定p2到底在极线的哪个位置了。
从代数角度来看一下这里的几何关系。在第一帧的坐标系下,设P的空间位置为P = [X, Y, Z]T.根据针孔相机模型知道两个像素点 p1, p2的像素位置为:
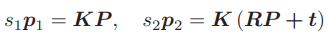
这里K为相机内参矩阵,R, t 为两个坐标系的相机运动。具体来说,这里计算的是 R21和 t21 ,因为是把第一个坐标系下的坐标转换到第二个坐标系下。在使用齐次坐标时,一个向量等于它自身乘上任意的非零常数。这通常用于表达一个投影关系。例如 s1p1 和 p1 成投影关系,它们在齐次坐标的意义下是相等的。称这种相等关系为尺度意义下相等(equal up to a scale),记作:sp ≃ p.那么,上述两个投影关系可写为:p1 ≃ KP ,p2 ≃ K(RP + t) .现在取:
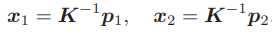
这里的x1,x2是两个像素点的归一化平面上的坐标。代入上式,得:x2 ≃ Rx1 + t.
两边同时左乘 t∧ 。根据∧的定义,这相当于两侧同时与t做外积:
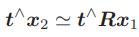
然后,两侧同时左乘
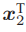
得:
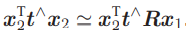
观察等式左侧
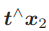
是一个与 t 和x2都垂直的向量。把它再和x2做内积时,将得到0。由于等式左侧严格为零,那么乘以任意非零常数之后也为零,于是可以把 ≃ 写成通常的等号。因此,就得到了:
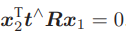
重新代入 p1, p2 ,有:
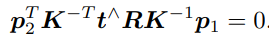
这两个式子都称为对极约束。它的几何意义是O1, P, O2三者共面。对极约束中同时包含了平移和旋转。把中间部分记作两个矩阵:基础矩阵(Fundamental Matrix)F和本质矩阵(Essential Matrix)E,于是可以进一步简化对极约束:
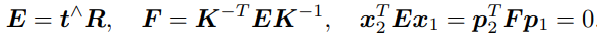
对极约束简洁地给出了两个匹配点的空间位置关系。于是,相机位姿估计问题变为以下两步:
- 根据配对点的像素位置求出 E 或者 F 。
- 根据E或者F求出 R, t。由于 E 和 F 只相差了相机内参,而内参在SLAM中通常是已知的,所以实践当中往往使用形式更简单的E。
3.2本质矩阵E
根据定义,本质矩阵 E = t∧R。它是一个3 × 3的矩阵,内有 9 个未知数。从E的构造方式上看,有以下值得注意的地方:
• 本质矩阵是由对极约束定义的。由于对极约束是等式为零的约束,所以对E乘以任意非零常数后,对极约束依然满足。这称为E在不同尺度下是等价的。
• 根据 E = t∧R,可以证明,本质矩阵E的奇异值必定是 [σ, σ, 0]T的形式。这称为本质矩阵的内在性质。
• 另一方面,由于平移和旋转各有 3 个自由度,故 t∧R 共有 6 个自由度。但由于尺度等价性,故 E 实际上有 5 个自由度。表明最少可以用5对点来求解E。但是,E的内在性质是一种非线性性质,在估计时会带来麻烦,因此,也可以只考虑它的尺度等价性,使用8对点来估计E——这就是经典的八点法(Eight-point-algorithm) 。八点法只利用了E的线性性质,因此可以在线性代数框架下求解。
考虑一对匹配点,它们的归一化坐标为 x1= [u1 , v1 , 1] T , x2 = [u2 , v2 , 1] T 。根据对极约束,有:

把矩阵 E 展开,写成向量的形式:e = [e1 , e2 , e3 , e4 , e5 , e6 , e7 , e8 , e9 ] T ,那么对极约束可以写成与e有关的线性形式:[u1u2 , u1v2 , u1, v1u2, v1v2, v1, u2, v2, 1] ·e = 0.同理,对于其他点对也有相同的表示。把所有点都放到一个方程中,变成线性方程组(ui , vi 表示第 i 个特征点,以此类推):

这八个方程构成了一个线性方程组。它的系数矩阵由特征点位置构成,大小为 8 × 9。 e 位于该矩阵的零空间中。如果系数矩阵是满秩的(即秩为 8),那么它的零空间维数为 1, 也就是 e 构成一条线。这与 e 的尺度等价性是一致的。如果八对匹配点组成的矩阵满足秩为 8 的条件,那么E的各元素就可由上述方程解得。
接下来的问题是如何根据已经估得的本质矩阵E,恢复出相机的运动 R, t。这个过程是由奇异值分解(SVD)得到的。设 E 的 SVD 分解为:
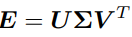
其中 U,V 为正交阵,Σ 为奇异值矩阵。根据 E 的内在性质,可以知道 Σ = diag(σ, σ, 0)。 在 SVD 分解中,对于任意一个 E,存在两个可能的 t, R 与它对应:
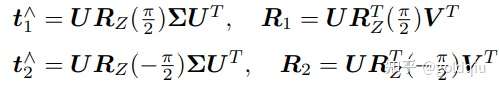
其中
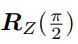
表示沿 Z 轴旋转 90 度得到的旋转矩阵。同时,由于 −E 和 E 等价,所以对任意一个 t 取负号,也会得到同样的结果。因此,从 E 分解到 t, R 时,一共存在四个可能的解。只有第一种解中,P 在两个相机中都具有正的深度。因此,只要把任意一点代入四种解中,检测该点在两个相机下的深度,就可以确定哪个解是正确的了。
如果利用 E 的内在性质,那么它只有五个自由度。所以最小可以通过五对点来求解相机运动。然而这种做法形式复杂,从工程实现角度考虑,由于平时通常会有几十对乃至上百对的匹配点,从八对减至五对意义并不明显。剩下的问题还有一个:根据线性方程解出的 E,可能不满足 E 的内在性质——它的奇异值不一定为 σ, σ, 0 的形式。这时,在做 SVD 时会刻意地把 Σ 矩阵调整成上面的样子。通常的做法是,对八点法求得的 E 进行 SVD 分解后,会得到奇异值矩阵 Σ = diag(σ1, σ2, σ3),不妨设 σ1 ≥ σ2 ≥ σ3。取:
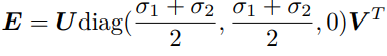
这相当于是把求出来的矩阵投影到了 E 所在的流形上。更简单的做法是将奇异值矩阵取成 diag(1, 1, 0),因为 E 具有尺度等价性,这样做也是合理的。
3.3单应矩阵
单应矩阵(Homography)H ,描述了两个平面之间的映射关系。若场景中的特征点都落在同一平面上(比如墙,地面等),则可以通过单应性来进行运动估计。这种情况在无人机携带的俯视相机,或扫地机携带的顶视相机中比较常见。单应矩阵通常描述处于共同平面上的一些点,在两张图像之间的变换关系。考虑在图像I1和I2有一对匹配好的特征点p1和p2。这些特征点落在某平面上。设这个平面满足方程:
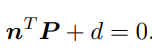
然后代入
得:
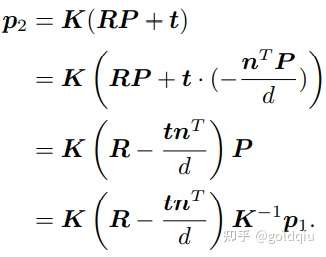
把直接描述图像坐标 p1 和 p2 之间的变换的中间这部分记为 H,于是 p2 = Hp1。它的定义与旋转、平移以及平面的参数有关。单应矩阵H是一个 3 × 3 的矩阵,求解时的思路可以先根据匹配点计算H,然后将它分解以计算旋转和平移。把上式展开,得:
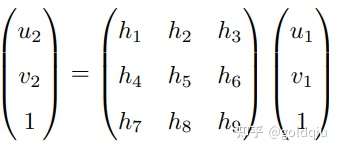
注意这里的等号是在非零因子下成立的。在实际处理中,通常乘以一个非零因子使得 h9 = 1(在它取非零值时)。然后根据第三行,去掉这个非零因子,于是有:

这样一组匹配点对就可以构造出两项约束(事实上有三个等式,但是因为线性相关,只取前两个),于是自由度为 8 的单应矩阵可以通过 4 对匹配特征点算出(注意:这些特征点不能有三点共线的情况),即求解以下的线性方程组(当 h9 = 0 时,右侧为零):
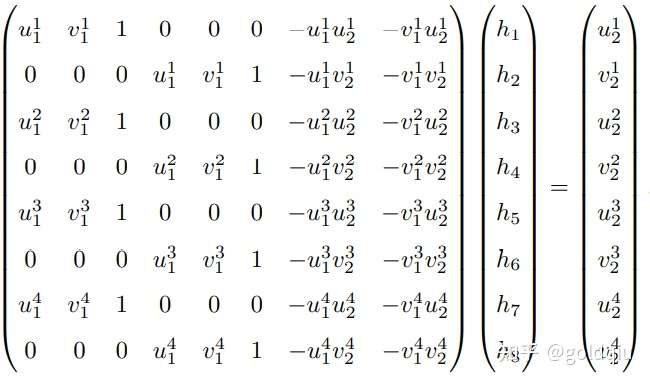
这种做法把H矩阵看成了向量,通过解该向量的线性方程来恢复H,又称直接线性变换法(Direct Linear Transform)。求出单应矩阵以后需要对其进行分解,才可以得到相应的旋转矩阵 R 和平移向量 t。分解的方法包括数值法与解析法 。单应矩阵的分解会返回四组旋转矩阵与平移向量,并且同时可以计算出它们分别对应的场景点所在平面的法向量。如果已知成像的地图点的深度全为正值(即在相机前方),则又可以排除两组解。最后仅剩两组解,这时需要通过更多的先验信息进行判断。通常可以通过假设已知场景平面的法向量来解决,如场景平面 与相机平面平行,那么法向量n的理论值为1。
单应性在 SLAM 中具有重要意义。当特征点共面,或者相机发生纯旋转的时候,基础矩阵的自由度下降,这就出现了所谓的退化(degenerate)。现实中的数据总包含一些噪声, 这时候如果继续使用八点法求解基础矩阵,基础矩阵多余出来的自由度将会主要由噪 声决定。为了能够避免退化现象造成的影响,通常会同时估计基础矩阵 F 和单应矩阵 H,选择重投影误差比较小的那个作为最终的运动估计矩阵。
总结
2D-2D的情况下,只知道图像坐标之间的对应关系
特征点在平面上的时候,使用H恢复R,t
否则,使用E(相机内参已知,更方便,也更常用)或者F恢复R,t
求得R,t之后
- 利用三角化计算特征点的3D位置(深度)
4、实践:对极约束求解相机运动(pose_esti_2d2d)
如何通过 Essential 矩阵求解相机运动?
使用匹配好的特征点来计算 E,F 和 H,进而分解 E 得 到 R, t。整个程序使用 OpenCV 提供的算法进行求解。
代码:slambook/ch7/pose_estimation_2d2d.cpp
pose_estimation_2d2d函数提供了从特征点求解相机运动的部分,在函数中输出了 E,F 和 H 的数值,然后验证对极约束是否成立,以及 t ∧R 和 E 在非零数乘下等价的事实。调用此程序的输出结果:
1 | build/pose_estimation_2d2d 1.png 2.png |
可以看出,对极约束的满足精度约在 10−3 量级。OpenCV 使用三角化检测角点的深度是否为正,从而选出正确的解。 对极约束是从 x2 = Rx1 + t 得到的。这里的 R, t 组成的变换矩阵,是第一个图到第二个图的坐标变换矩阵: x2 = T21x1.
4.1 讨论
从演示程序中可以看到,输出的 E 和 F 相差了相机内参矩阵。从 E,F 和 H 都可以分解出运动,不过 H 需要假设特征点位于平面上。 由于 E 本身具有尺度等价性,它分解得到的 t, R 也有一个尺度等价性。而 R ∈ SO(3) 自身具有约束,所以认为 t 具有一个尺度。换言之,在分解过程中,对 t 乘以任意非零常数,分解都是成立的。因此通常把 t 进行归一化,让它的长度等于 1。
尺度不确定性
对 t 长度的归一化,直接导致了单目视觉的尺度不确定性(Scale Ambiguity)。例如,程序中输出的 t 第一维约 0.822。这个 0.822 究竟是指 0.822 米呢,还是 0.822 厘米 呢,是没法确定的。因为对 t 乘以任意比例常数后,对极约束依然是成立的。换言之, 在单目 SLAM 中,对轨迹和地图同时缩放任意倍数,得到的图像依然是一样的。 在单目视觉中,对两张图像的 t 归一化,相当于固定了尺度。虽然不知道它的实际长度为多少,但以这时的 t 为单位 1,计算相机运动和特征点的 3D 位置。这被称为单目 SLAM 的初始化。在初始化之后,就可以用 3D-2D 来计算相机运动了。初始化之后的轨迹和地图的单位,就是初始化时固定的尺度。因此,单目 SLAM 有一步不可避免的初始化。初始化的两张图像必须有一定程度的平移,而后的轨迹和地图都将以此步的平移为单位。 除了对 t 进行归一化之外,另一种方法是令初始化时所有的特征点平均深度为 1,也 可以固定一个尺度。相比于令 t 长度为 1 的做法,把特征点深度归一化可以控制场景的规模大小,使计算在数值上更稳定些。
初始化的纯旋转问题
从 E 分解到 R, t 的过程中,如果相机发生的是纯旋转,导致 t 为零,那么,得到的 E 也将为零,这将导致无从求解 R。不过,此时可以依靠 H 求取旋转,但仅有旋转时,无法用三角测量估计特征点的空间位置,于是,另一个结论是,单目初始化不能只有纯旋转,必须要有一定程度的平移。如果没有平移,单目将无法初始化。在实践当中,如果初始化时平移太小,会使得位姿求解与三角化结果不稳定, 从而导致失败。相对的,如果把相机左右移动而不是原地旋转,就容易让单目 SLAM 初始化。
多于八对点的情况
当给定的点数多于八对时,可以计算一个最小二乘解。对于线性化后的对极约束,我们把左侧的系数矩阵记为 A: Ae = 0
对于八点法,A 的大小为 8 × 9。如果给定的匹配点多于 8,该方程构成一个超定方程,即不一定存在 e 使得上式成立。因此,可以通过最小化一个二次型来求:
于是就求出了在最小二乘意义下的 E 矩阵。不过,当可能存在误匹配的情况时,会更倾向于使用随机采样一致性(Random Sample Concensus, RANSAC)来求,而不是最小二乘。RANSAC 是一种通用的做法,适用于很多带错误数据的情况,可以处理带有错误匹配的数据。
5、三角测量(三角化)
使用对极几何约束估计了相机运动之后,下一步需要用相机的运动估计特征点的空间位置。在单目SLAM中,仅通过单张图像无法获得像素的深度信息,需要通过三角测量(Triangulation)(或三角化)的方法来估计地图点的深度。
三角测量是指,通过在两处观察同一个点的夹角,确定该点的距离。三角测量最早由高斯提出并应用于测量学中,它在天文学、地理学的测量中都有应用。例如可以通过不同季节观察到星星的角度,估计它离我们的距离。在SLAM中主要用三角化来估计像素点的距离。
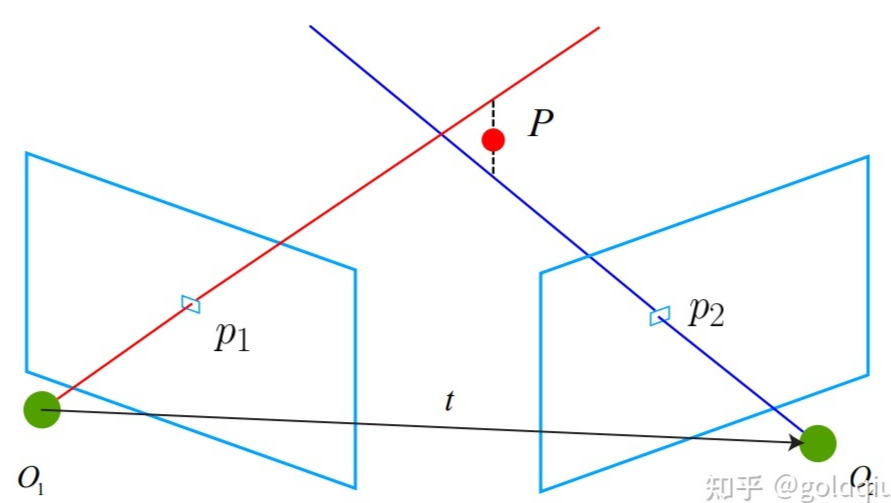
考虑图像 I1 和 I2,以左图为参考,右图的变换矩阵为 T。相机光心 为 O1 和 O2。在 I1 中有特征点 p1,对应 I2 中有特征点 p2。理论上直线 O1p1 与 O2p2 在场景中会相交于一点 P,该点即是两个特征点所对应的地图点在三维场景中的位置。然而由于噪声的影响,这两条直线往往无法相交。因此可以通过最二小乘去求解。 按照对极几何中的定义,设 x1, x2 为两个特征点的归一化坐标,那么它们满足: s1x1 = s2Rx2 + t.
已知 R, t,想要求解的是两个特征点的深度 s1, s2。这两个深度是可以分开求的,先算s2,那么先对上式两侧左乘一个 $ \hat{x_1} $得:
$$
s_1 \hat{x_1} x_1 = 0 = s_2 \hat{x_1} R x_2 + \hat{x_1} t
$$
该式左侧为零,右侧可看成 s2 的一个方程,可以根据它直接求得 s2。有了 s2,s1也可以求出。于是就得到了两个帧下的点的深度,确定了它们的空间坐标。由于噪声的存在,估得的 R, t不一定精确使方程为0,所以更常见的做法求最小二乘解而不是零解。
6、实践:三角测量
6.1 三角测量代码
代码演示了对之前根据对极几何求解的相机位姿通过三角化求出特征点的空间位置。调用 OpenCV 提供的 triangulation 函数进行三角化。
代码为:slambook/ch7/triangulation.cpp
同时在 main 函数中增加三角测量部分,并验证重投影关系。
代码输出某特征点的信息:
1 | point in the first camera frame: [0.0844072, -0.0734976] |
打印了每个空间点在两个相机坐标系下的投影坐标与像素坐标。这里对于这个特征点来说,通过两个图像下的一对像素坐标的三角化,能得到这个特征点的空间坐标,d为深度,利用这个空间坐标重投影能得到一个投影坐标,跟原始的像素坐标相比有一定的误差。由于误差的存在,它们会有一些微小的差异。误差的量级大约在小数点后第三位。可以看到,三角化特征点的距离大约为 15。但由于尺度不确定性,并不知道这里的 15 究竟是多少米。
6.2 讨论
三角测量是由平移得到的,有平移才会有对极几何中的三角形,才谈的上三角测量。因此,纯旋转是无法使用三角测量的,因为对极约束将永远满足。在平移存在的情况下,还要关心三角测量的不确定性,这会引出一个三角测量的矛盾。
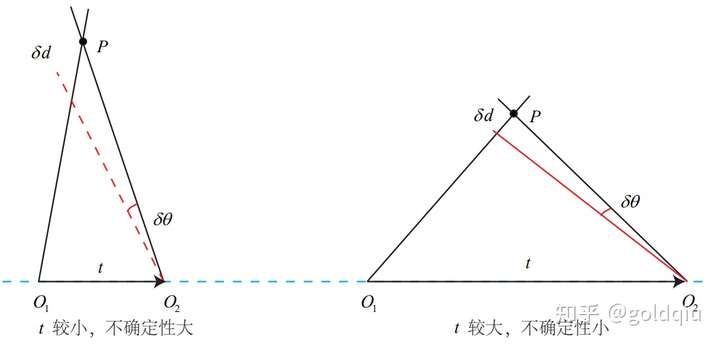
如图所示。当平移很小时,像素上的不确定性将导致较大的深度不确定性。也就是说,如果特征点运动一个像素 δx,使得视线角变化了一个角度 δθ,那么测量到深度值将有 δd 的变化。从几何关系可以看到,当 t 较大时,δd 将明显变小,这说明平移较大时, 在同样的相机分辨率下,三角化测量将更精确。对该过程的定量分析可以使用正弦定理得到,但这里先考虑定性分析。 因此,要增加三角化的精度,其一是提高特征点的提取精度,也就是提高图像分辨率 ——但这会导致图像变大,提高计算成本。另一方式是使平移量增大。但是,平移量增大会导致图像的外观发生明显的变化,比如箱子原先被挡住的侧面显示出来了,比如反射光发生变化了,等等。外观变化会使得特征提取与匹配变得困难。总而言之,增大平移,会导致匹配失效;而平移太小,则三角化精度不够——这就是三角化的矛盾。
拓展:定量地计算每个特征点的位置及不确定性。假设特征点服从高斯分布,并且对它不断地进行观测,在信息正确的情况下,就能够期望它的方差会不断减小乃至收敛。这就得到了一个滤波器,称为深度滤波器(Depth Filter)。
7、3D-2D: PnP
PnP(Perspective-n-Point)是求解 3D 到 2D 点对运动的方法。它描述了当知道 n 个 3D 空间点以及它们的投影位置时,如何估计相机所在的位姿。前面的2D-2D 的对极几何方法需要八个或八个以上的点对(以八点法为例),且存在着初始化、纯旋转和尺度的问题。然而,如果两张图像中,其中一张特征点的 3D 位置已知,那么最少只需三个点对(需要至少一个额外点验证结果)就可以估计相机运动。特征点的 3D 位置可以由三角化,或者由RGB-D 相机的深度图确定。因此,在双目或 RGB-D 的视觉里程计中, 可以直接使用 PnP 估计相机运动。而在单目视觉里程计中,必须先进行初始化,然后才能使用 PnP。3D-2D 方法不需要使用对极约束,又可以在很少的匹配点中获得较好的运动估计,是最重要的一种姿态估计方法。 PnP 问题有很多种求解方法,例如用三对点估计位姿的P3P,直接线性变换(DLT), EPnP(Efficient PnP),UPnP等等。此外,还能用非线性优化的方式,构建最小二乘问题并迭代求解,也就是万金油式的 Bundle Adjustment。
7.1 直接线性变换
考虑某个空间点 P,它的齐次坐标为 P = (X, Y, Z, 1)T。在图像 I1 中,投影到特征点 x1 = (u1, v1, 1)T(以归一化平面齐次坐标表示)。此时相机的位姿 R, t 是未知的。与单应矩阵的求解类似,定义增广矩阵 [R|t] 为一个 3 × 4 的矩阵,包含了旋转与平移信息。展开形式列写如下:
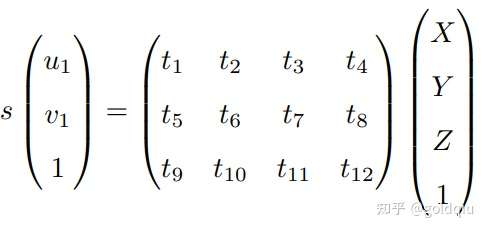
用最后一行把 s 消去,得到两个约束:
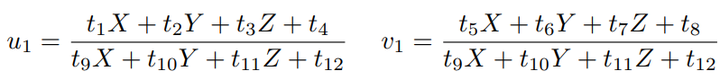
定义 T 的行向量: t1 = (t1, t2, t3, t4) T , t2 = (t5, t6, t7, t8) T , t3 = (t9, t10, t11, t12) T , 于是有:
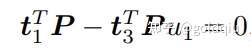
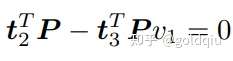
t 是待求的变量,可以看到每个特征点提供了两个关于 t 的线性约束。假设一共有 N 个特征点,可以列出线性方程组:
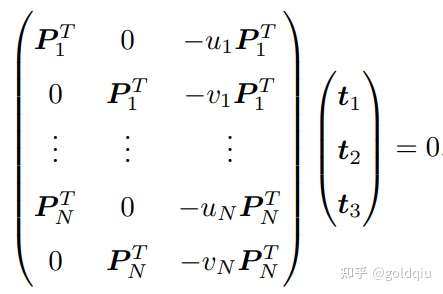
由于 t 一共有 12 维,因此最少通过六对匹配点,即可实现矩阵 T 的线性求解,这种方法称为直接线性变换(Direct Linear Transform,DLT)。当匹配点大于六对时,可以使用 SVD 等方法对超定方程求最小二乘解。 在 DLT 求解中,直接将 T 矩阵看成了 12 个未知数,忽略了它们之间的联系。因为旋转矩阵 R ∈ SO(3),用 DLT 求出的解不一定满足该约束,它是一个一般矩阵。平移向量属于向量空间,对于旋转矩阵 R,必须针对 DLT 估计的 T 的左边寻找一个最好的旋转矩阵对它进行近似。这可以由 QR 分解完成, 相当于把结果从矩阵空间重新投影到 SE(3) 流形上,转换成旋转和平移两部分。 这里的 x1 使用了归一化平面坐标,去掉了内参矩阵 K 的影响 ——这是因为内参 K 在 SLAM 中通常假设为已知。如果内参未知,也能用 PnP 去估计 K, R, t 三个量。然而由于未知量的增多,效果会差一些。
7.7.2 P3P
P3P仅使用三对匹配点,对数据要求较少,需要利用给定的三个点的几何关系。它的输入数据为三对 3D-2D 匹配点。记 3D 点为 A, B, C,2D 点为 a, b, c,其中小写字母代表的点为大写字母在相机成像平面上的投影,如图所示。
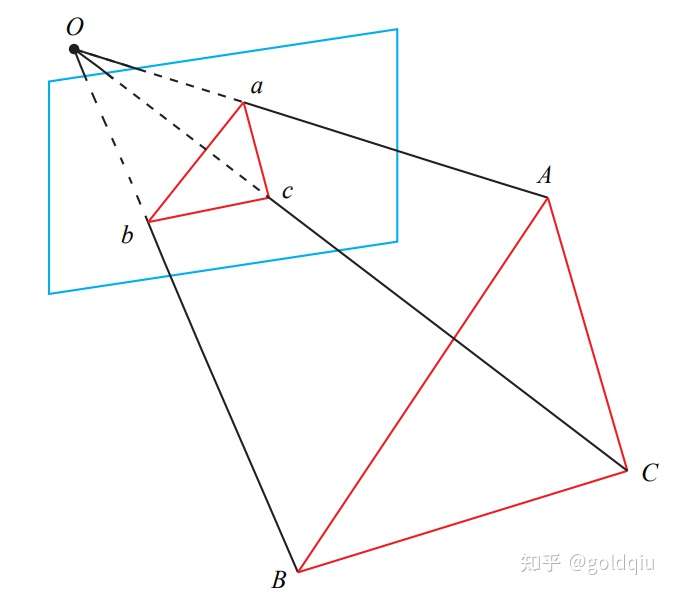
此外,P3P 还需要使用一对验证点,以从可能的解出选出正确的那一个(类似于对极几何情形)。记验证点对为 D − d,相机光心为 O。注意,预知的是 A, B, C 在世界坐标系中的坐标,而不是在相机坐标系中的坐标。一旦3D 点在相机坐标系下的坐标能够算出,就得到了 3D-3D 的对应点,把 PnP 问题转换为了 ICP 问题。三角形之间存在对应关系:
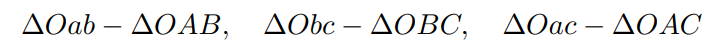
利用余弦定理,有:

对上面三式全体除以

并且记 x = OA/OC, y = OB/OC,得:
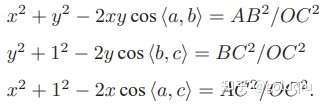
记
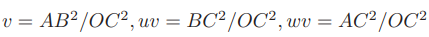
有:
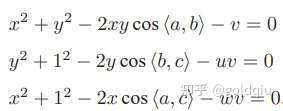
化为:
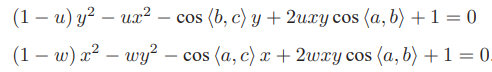
由于知道 2D 点的图像位置,三个余弦角 cos⟨a, b⟩, cos⟨b, c⟩, cos⟨a, c⟩ 是已知的。同时,
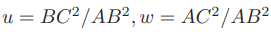
可以通过 A, B, C 在世界坐标系下的坐标算出,变换到相机坐标系下之后,并不改变这个比值。该式中的 x, y 是未知的,随着相机移动会发生变化。因此,该方程组是关于 x, y 的一个二元二次方程(多项式方程)。解析地求解该方程组是一个复杂的过程,需要用吴消元法。类似于分解 E 的情况,该方程最多可能得到四个解,但可以用验证点来计算最可能的解,得到 A, B, C 在相机坐标系下的 3D 坐标。然后,根据 3D-3D 的点对,计算相机的运动 R, t。
从 P3P 的原理上可以看出,为了求解 PnP,利用了三角形相似性质,求解投影点 a, b, c 在相机坐标系下的 3D 坐标,最后把问题转换成一个 3D 到 3D 的位姿估计问题。
P3P 也存在着一些问题:
P3P 只利用三个点的信息。当给定的配对点多于 3 组时,难以利用更多的信息。
如果 3D 点或 2D 点受噪声影响,或者存在误匹配,则算法失效。 所以后续人们还提出了许多别的方法,如 EPnP、UPnP 等。它们利用更多的信息,而且用迭代的方式对相机位姿进行优化,以尽可能地消除噪声的影响。在 SLAM 当中,通常的做法是先使用 P3P/EPnP 等方法估计相机位姿,然后构建最小二乘优化问题对估计值进行调整(Bundle Adjustment)。
7.3 Bundle Adjustment
除了使用线性方法之外,可以把 PnP 问题构建成一个定义于李代数上的非线性最小二乘问题。前面说的线性方法,往往是先求相机位姿,再求空间点位置,而非线性优化则是把它们都看成优化变量,放在一起优化。这是一种非常通用的求解方式,可以用它对 PnP 或 ICP 给出的结果进行优化。在 PnP 中, 这个 Bundle Adjustment 问题,是一个最小化重投影误差(Reprojection error)的问题。
考虑 n 个三维空间点 P 和它们的投影 p,希望计算相机的位姿 R, t,它的李代数表示为 ξ。假设某空间点坐标为 Pi = [Xi , Yi , Zi ]T,其投影的像素坐标为 ui = [ui , vi ]T。 像素位置与空间点位置的关系如下:
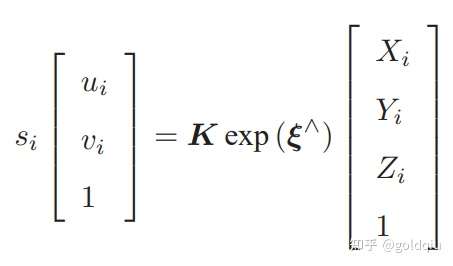
写成矩阵形式是:
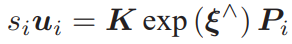
中间隐含着齐次坐标到非齐次的转换,否则按矩阵的乘法来说,维度是不对的。因为exp (ξ∧) Pi 结果是 4 × 1 的,而它左侧的 K 是 3 × 3 的,所以必须把 exp (ξ ∧) Pi 的前三维取出来,变成三维的非齐次坐标。 现在,由于相机位姿未知以及观测点的噪声,该等式存在一个误差。因此把误差求和,构建最小二乘问题,然后寻找最好的相机位姿,使它最小化:
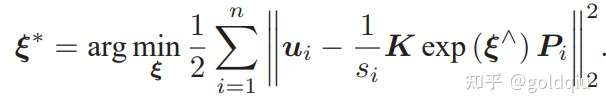
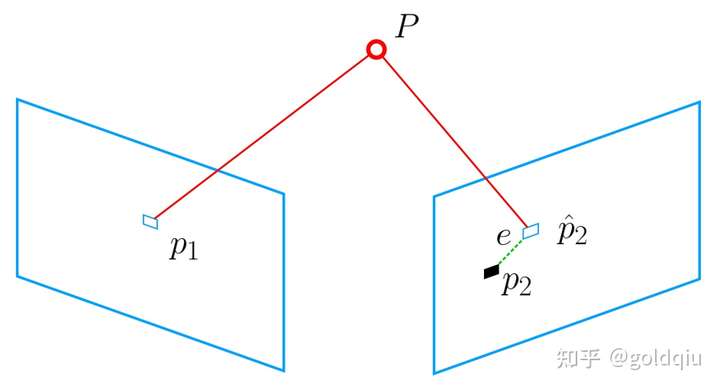
该问题的误差项,是将像素坐标(观测到的投影位置)与 3D 点按照当前估计的位姿进行投影得到的位置相比较得到的误差,所以称之为重投影误差。使用齐次坐标时,这个误差有 3 维。不过,由于u最后一维为 1,该维度的误差一直为零,因而更多时候使用非齐次坐标,于是误差就只有 2 维了。
如图所示,通过特征匹配,知道了 p1 和 p2 是同一个空间点 P 的投影,但是不知道相机的位姿。在初始值中,P 的投影 pˆ2 与实际的 p2 之间有一定的距离。于是调整相机的位姿,使得这个距离变小。不过,由于这个调整需要考虑很多个点,所以最后每个点的误差通常都不会精确为零。
使用李代数,可以构建无约束的优化问题, 很方便地通过 G-N, L-M 等优化算法进行求解。不过,在使用 G-N 和 L-M 之前,需要知道每个误差项关于优化变量的导数,也就是线性化: e(x + ∆x) ≈ e(x) + J∆x.
这里的 J 的形式是关键所在。固然可以使用数值导数,但如果能够推导解析形式时,会优先考虑解析导数。现在,当 e 为像素坐标误差 (2 维),x 为相机位姿(6 维)时,J 将是一个 2 × 6 的矩阵。
使用扰动模型来求李代数的导数:
首先,记变换到相机坐标系下的空间点坐标为 P′,并且将其前三维取出来: P′ = (exp (ξ∧)P)1:3 = [X′,Y′,Z′]T
相机投影模型相对于P′则为: su = KP′
展开:
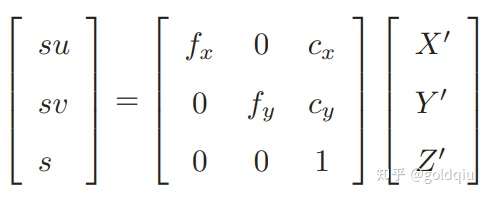
利用第 3 行消去 s(实际上就是 P′ 的距离),得:
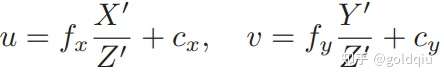
这与相机模型是一致的。当求误差时,可以把这里的 u, v 与实际的测量值比较,求差。定义了中间变量后对 ξ∧左乘扰动量δξ,然后考虑 e 的变化关于扰动量的导数。利用链式法则,可以列写如下:
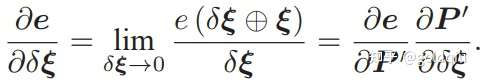
这里的⊕指李代数上的左乘扰动。第一项是误差关于投影点的导数,得:
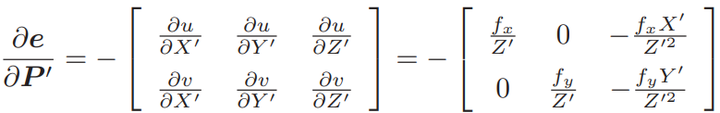
第二项为变换后的点关于李代数的导数,得:
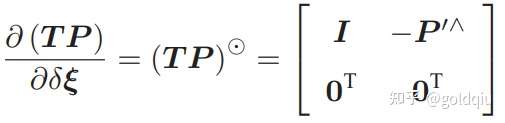
而在 P′ 的定义中,取出了前三维,于是得:
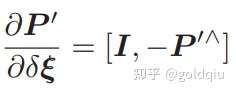
将这两项相乘,就得到了 2 × 6 的雅可比矩阵:
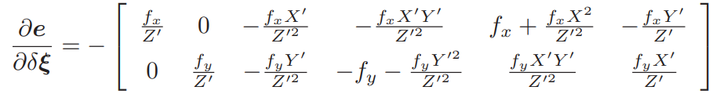
这个雅可比矩阵描述了重投影误差关于相机位姿李代数的一阶变化关系。保留了前面的负号,因为这是由于误差是由观测值减预测值定义的。它当然也可反过来,定义成 “预测减观测”的形式。在这种情况下,只要去掉前面的负号即可。此外,如果 se(3) 的定义方式是旋转在前,平移在后时,只要把这个矩阵的前三列与后三列对调即可。
另一方面,除了优化位姿,还希望优化特征点的空间位置。因此,需要讨论 e 关于空间点 P 的导数。仍利用链式法则,有:
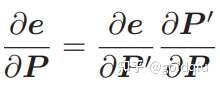
第二项,按照定义 P′ = exp(ξ∧)P = RP + t.
发现 P′ 对 P 求导后只剩下 R。于是:
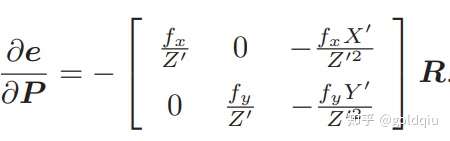
以上是观测相机方程关于相机位姿与特征点的两个导数矩阵。它们能够在优化过程中提供重要的梯度方向,指导优化的迭代。
8、实践:求解 PnP
8.1 使用 EPnP 求解位姿
首先用 OpenCV 提供的 EPnP 求 解 PnP 问题,然后通过 g2o 对结果进行优化。由于 PnP 需要使用 3D 点,为了避免初始化带来的麻烦,使用了 RGB-D 相机中的深度图(1_depth.png),作为特征点的 3D 位置。
代码为: slambook/ch7/pose_estimation_3d2d.cpp
在例程中,得到配对特征点后,在第一个图的深度图中寻找它们的深度,并求出空间位置。以此空间位置为 3D 点,再以第二个图像的像素位置为 2D 点,调用 EPnP 求解 PnP 问题。程序输出后可以看到,在有3D信息时,估计的 R 几乎是相同的,而 t 相差的较多。这是由于引入了新的深度信息所致。 不过,由于 Kinect 采集的深度图本身会有一些误差,所以这里的 3D 点也不是准确的。后面会希望把位姿 ξ 和所有三维特征点 P 同时优化。
8.2 使用 BA 优化
使用前一步的估计值作为初始值,把问题建模成一个最小二乘的图优化问题,如图所示。
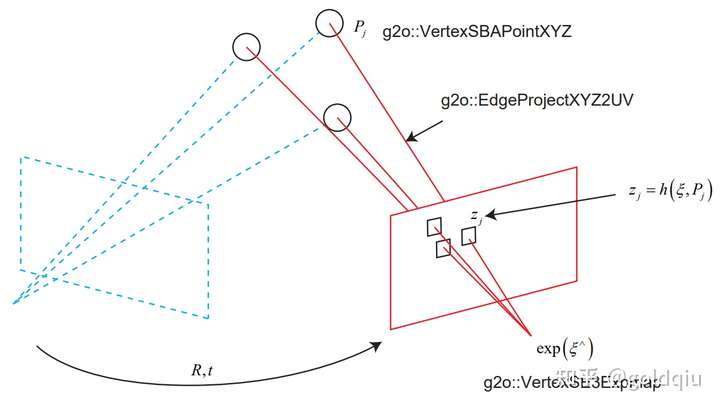
在这个图优化中,节点和边的选择为:
- 节点:第二个相机的位姿节点 ξ ∈ se(3),以及所有特征点的空间位置 P ∈ R3。
- 边:每个 3D 点在第二个相机中的投影,以观测方程来描述: zj = h(ξ, Pj ).
由于第一个相机位姿固定为零,没有把它写到优化变量里。现在根据一组 3D 点和第二个图像中的 2D 投影,估计第二个相机的位姿。所以把第一个相机画成虚线,表明不希望考虑它。 g2o 提供了许多关于 BA 的节点和边,不必自己从头实现所有的计算。在 g2o/types/sba/types_six_dof_expmap.h 中提供了李代数表达的节点和边。文件中有VertexSE3Expmap(李代数位姿)、VertexSBAPointXYZ(空间点位置) 和 EdgeProjectXYZ2UV(投影方程边)这三个类。
VertexSE3Expmap的类定义:
1 | class G2O_TYPES_SBA_API VertexSE3Expmap : public BaseVertex<6, SE3Quat>{ |
模板参数:
- 第一个参数 6 表示它内部存储的优化变量维度,可以看到这是一个 6 维的李代数。
- 第二参数是优化变量的类型,这里使用了 g2o 定义的相机位姿:SE3Quat。 这个类内部使用了四元数加位移向量来存储位姿,但同时也支持李代数上的运算,例如对数映射(log 函数)和李代数上增量(update 函数)等操作。
- 空间点位置类的维度为 3,类型是 Eigen 的 Vector3D。另一方面,边 EdgeProjectXYZ2UV 连接了两个前面说的两个顶点,它的观测值为 2 维,由 Vector2D 表示,实际上就是空间点的像素坐标。它的误差计算函数表达了投影方程的误差计算方法,也就是前面提到的 z − h(ξ, P ) 的方式。
EdgeProjectXYZ2UV 的 linearizeOplus 函数的实现用到了前面推导的雅可比矩阵:
1 | void EdgeProjectXYZ2UV::linearizeOplus() { |
它与公式是一致的。成员变量“*- jacobianOplusXi”是误差到空间点的导数,“*jacobianOplusXj”是误差到相机位姿的导数,以李代数的左乘扰动表达。稍有差别的是,g2o 的相机里用 f 统一描述 fx, fy,并且 李代数定义顺序不同(g2o 是旋转在前,平移在后),所以矩阵前三列和后三列与上面的定义是颠倒的。
们在上一个 PnP 例程的基础上,加上 g2o 提供的 Bundle Adjustment:
首先声明了 g2o 图优化,配置优化求解器和梯度下降方法,然后根据估计到的特征点,将位姿和空间点放到图中。最后调用优化函数进 行求解。
优化结果:迭代 11 轮后,LM 发现优化目标函数接近不变,于是停止了优化。输出了最后得到位姿变换矩阵 T,对比之前直接做 PnP 的结果,大约在小数点后第三位发生了一些变化。这主要是由于同时优化了特征点和相机位姿导致的。
Bundle Adjustment 是一种通用的做法。它可以不限于两个图像。可以放入多个图像匹配到的位姿和空间点进行迭代优化,甚至可以把整个 SLAM 过程放进来。那种做法规模较大,主要在后端使用。在前端,我们通常 考虑局部相机位姿和特征点的小型 Bundle Adjustment 问题,希望实时对它进行求解和优化。
9、3D-3D: ICP
3D-3D的位姿估计问题。假设有一组配对好的3D点,
$$
P = { p_1, …, p_n} \quad P^{‘} = { p_1^{‘}, …, p_n^{‘}}
$$
我们想要找到一个欧式变换R,t使得:
$$
\forall_i, p_i = Rp_i^{‘} + t.
$$
这个问题可以用迭代最近点(Iterative Closest Point, ICP)求解。3D-3D位姿问题中,没有相机模型,也就是说,仅考虑两组3D点之间的变换时,跟相机并没有关系。在RGB-D SLAM中,可以用这种方式估计相机位姿。
两种求解方式:1、线性代数的求解(SVD)2、非线性优化方式(类Bundle Adjustment)
9.1 SVD方法
定义误差项:
$$
e_i = p_i - (Rp_i^{‘} + t ).
$$
构建最小二乘问题,求误差平方和达到最小的R,t;
$$
\min_{R,t}J = \frac{1}{2} \sum_{i=1}^n || p_i - (Rp_i^{‘} + t)||_2^{2}
$$
下面推导求解方法,定义两组质心:
$$
p = \frac{1}{n} \sum_{i=1}^{n} (p_i) ,
\qquad
p^{‘} = \frac{1}{n} \sum_{i=1}^{n} (p^{‘}_i)
$$
注意,质心没有下标的。随后带入误差函数,如下处理:
$$
\frac{1}{2} \sum_{i=1}^{n} || p_i - (Rp_i^{‘} + t )||^2 =
\frac{1}{2} \sum_{i=1}^{n} || p_i - Rp_i^{‘} -t -p +Rp^{‘} +p -Rp^{‘})||^2
\
\qquad \qquad \qquad \qquad \qquad
= \frac{1}{2} \sum_{i=1}^{n} || p_i -p - R(p_i^{‘} - p^{‘}) + (p - Rp^{‘} + t)||^2
\
\qquad \qquad \qquad \qquad \qquad \qquad
= \frac{1}{2} \sum_{i=1}^{n} || p_i -p - R(p_i^{‘} - p^{‘}) ||^2
- ||(p - Rp^{‘} + t)||^2 +
\ \qquad \qquad \qquad \qquad \qquad
2(p_i^{‘} - p^{‘} - R(p_i^{‘} - p^{‘}))^T (p-Rp^{‘}-t)
$$
注意到交叉项部分中, $(p_i^{‘} - p^{‘} - R(p_i^{‘} - p^{‘}))$ 在求和之后为零的,因此优化目标函数可以简化为:
$$
\min_{R,t} J = \frac{1}{2} \sum_{i=1}^{n} || p_i -p - R(p_i^{‘} - p^{‘}) ||^2
- ||(p - Rp^{‘} + t)||^2
$$
仔细观察左右两项,左边只和旋转矩阵R相关,右边既有R也有t,单是只跟质心相关,只要获取了R,令第二项为零,即可得到t。
因此分三个步骤:


9.2 非线性优化方法

于是,在非线性优化中只需不断迭代,我们就能找到极小值。而且,可以证明 [6] , ICP 问题存在唯一解或无穷多解的情况。
在唯一解的情况下,只要我们能找到极小值解,那么 这个极小值就是全局最优值——因此不会遇到局部极小而非全局最小的情况。
这也意味着 ICP 求解可以任意选定初始值。这是已经匹配点时求解 ICP 的一大好处。 需要说明的是,我们这里讲的 ICP ,
是指已经由图像特征给定了匹配的情况下,进行 位姿估计的问题。在匹配已知的情况下,这个最小二乘问题实际上具有解析解 [52, 53, 54] ,
所以并没有必要进行迭代优化。 ICP 的研究者们往往更加关心匹配未知的情况。不过,在 RGB-D SLAM 中,由于一个像素的深度数据可能测量不到,
所以我们可以混合着使用 PnP 和 ICP 优化:对于深度已知的特征点,用建模它们的 3D-3D 误差;对于深度未知的特征
点,则建模 3D-2D 的重投影误差。于是,可以将所有的误差放在同一个问题中考虑,使得 求解更加方便。
10、实践:求解ICP
引用:
SLAM_OV 第七讲-视觉里程计-1 特征点法和特征提取和匹配实践
SLAM_OV 第七讲-视觉里程计-2 对极几何和对极约束、本质矩阵、基础矩阵
SLAM OV 第七讲-视觉里程计-5,6 视觉里程计-三角测量和实践