基础架构
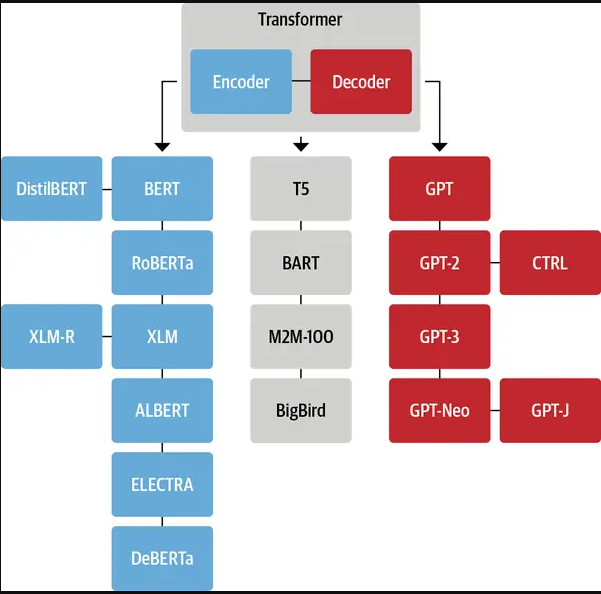
纯 Encoder 模型(例如 BERT),又称自编码 (auto-encoding) Transformer 模型;适用于只需要理解输入语义的任务,例如句子分类、命名实体识别;
纯 Decoder 模型(例如 GPT),又称自回归 (auto-regressive) Transformer 模型;适用于生成式任务,例如文本生成;
Encoder-Decoder 模型(例如 BART、T5),又称 Seq2Seq (sequence-to-sequence) Transformer 模型。适用于需要基于输入的生成式任务,例如翻译、摘要。
一个完整的AI应用包含了4个重要的环节:
第一个环节是关于大语言模型(LLM),这是大家在AI体系中接触最多的部分;
第二个环节是与模型相关的Embedding;
第三个环节是向量数据库;
最后一个环节是Promote Engineer(AI提示词(Prompt))。
基础模块
Embeddding
Mutil-Head Attention
Feed Forward
Add & Norm
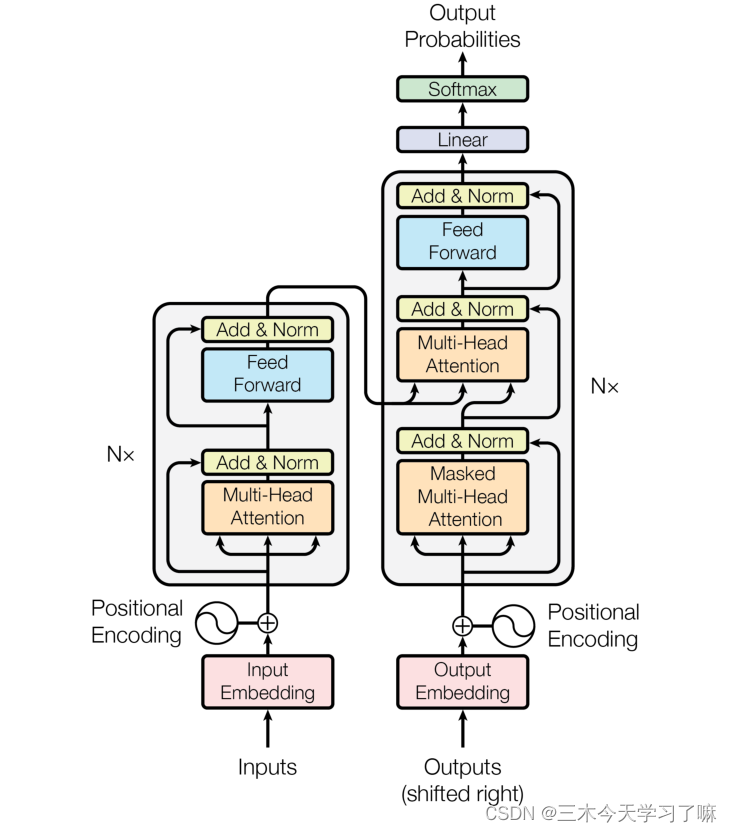
模型seq2seq
-输入部分、输出部分、编码器部分、解码器部分。
 \
\
输入部分
文本嵌入层的作用:
无论是源文本嵌入还是目标文本嵌入,都是为了将文本中词汇的数字表示转变为向量表示,希望在这样的高维空间捕捉词汇间的关系。
位置编码器的作用:
因为在Transformer的编码器结构中,并没有针对词汇位置信息的处理,因此需要在Embedding层后加入位置编码器,将词汇位置不同可能会产生不同语义的信息加入到词嵌入张量中,以弥补位置信息的缺失。
编码器部分
由N个编码器层堆叠而成
每个编码器层由两个子层连接结构组成
第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
Prompt
02Prompt基本组成部分
基于Prompt的格式化结果输出与正则表达式提取Prompt设计是大语言模型互动的关键,它可以显著影响模型的输出结果质量。一个合理设计的Prompt应当包含以下四个元素:
**1.指令(Instruction):**这是Prompt中最关键的部分。指令直接告诉模型用户希望执行的具体任务。
**2.输入数据(Input Data):**输入数据是模型需要处理的具体信息。
**3.背景信息(Context):**背景信息为模型提供了执行任务所需的环境信息或附加细节。
**4.输出指示器(Output Indicator):**输出指示器定义了模型输出的期望类型或格式。
参考资料
【Transformer】架构解析_transformer架构_三木今天学习了嘛的博客-CSDN博客
# 基于向量数据库的文档语义搜索实战【Qdrant】