Secrets of RLHF in Large Language Models
论文链接:https://arxiv.org/pdf/2307.04964.pdf
仓库链接:https://github.com/OpenLMLab/MOSS-RLHF
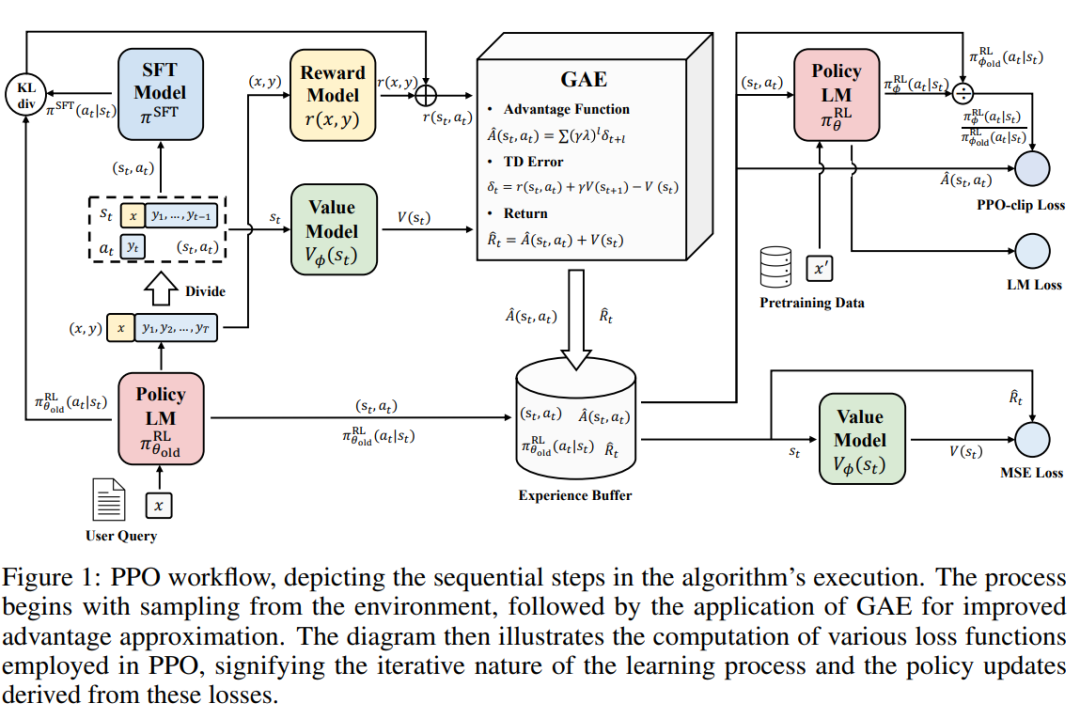
研究人员探究了PPO算法的高级版本PPO-max,可以有效提高策略模型的训练稳定性,并基于主要实验结果,综合分析了RLHF与SFT模型和ChatGPT的能力对比。
RLHF go
人工智能助手的训练过程包括三个主要阶段:有监督微调(SFT)、奖励模型(RM)训练和奖励模型上的近端策略优化(PPO)。