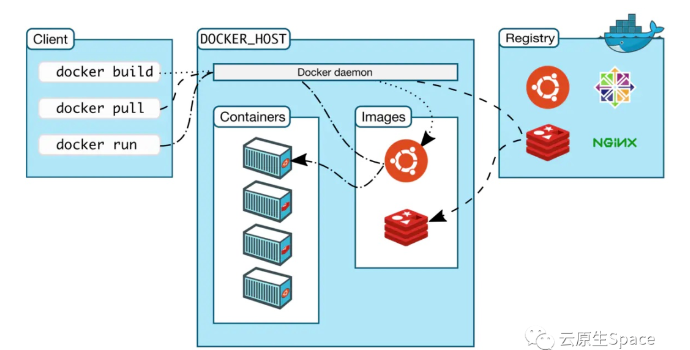
Docker 架构
Docker安装(Ubuntu) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 sudo apt update sudo apt install apt-transport-https ca-certificates curl gnupg-agent software-properties-common curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add - sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" sudo apt update sudo apt install docker-ce docker-ce-cli containerd.io sudo apt update apt list -a docker-ce systemctl status docker
docker Nvdia images 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 安装Docker: https://github.com/NVIDIA/nvidia-docker 注意:要在不带 sudo 的情况下运行 docker 命令,请创建 docker 组并添加用户。有关详情,请参阅针对 Linux 的安装后步骤。 https://docs.docker.com/install/linux/linux-postinstall/ 下载 TensorFlow Docker 映像 docker pull tensorflow/tensorflow # latest stable release docker pull tensorflow/tensorflow:1.12.0-gpu-py3 docker pull tensorflow/tensorflow:nightly-devel-gpu # nightly dev release w/ GPU support 运行测试: docker run --runtime=nvidia -it --rm tensorflow/tensorflow:latest-gpu \ python -c "import tensorflow as tf; tf.enable_eager_execution(); print(tf.reduce_sum(tf.random_normal([1000, 1000])))" docker run --runtime=nvidia -it --rm tensorflow/tensorflow:1.12.0-gpu-py3 \ python -c "import tensorflow as tf; tf.enable_eager_execution(); print(tf.reduce_sum(tf.random_normal([1000, 1000])))"
docker run -it –rm -v $PWD:/tmp -w /tmp tensorflow/tensorflow:1.12.0-gpu-py3 python3 ./selfplay/tf_nn_policy_network_01.py
docker run –runtime=nvidia -it –rm -v $PWD:/home/user/shixinxin tensorflow/tensorflow:1.12.0-gpu-py3
docker run –runtime=nvidia -it –rm -v $PWD:/home/user/shixinxin tensorflow/tensorflow:1.12.0-gpu-py3
创建一个镜像(共享文件路径)
sudo docker ps
查看dockers
sudo docker exec -it 88ce65ec31e3 /bin/bash
进入docker bash
python3 -u xxx.py
运行.py
Python3
运行python
nvidia-smi
Docker镜像 Docker
cuda10.0
1.2-cuda10.0-cudnn7-devel
cuda10.1
1.3.0 ~ 1.6.0-cuda10.1-cudnn7-devel
cuda10.2
1.8.1 ~ 1.9.0-cuda10.2-cudnn7-devel
cuda11.0
1.7.1-cuda11.0-cudnn8-devel
Docker测试 1 g++ -I/usr/local/cuda-11.0/targets/x86_64-linux/include/ gemfield.cpp -o gemfield -L/usr/local/cuda-11.0/targets/x86_64-linux/lib/ -lcudart
Docker 服务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 # Stop systemctl status docker systemctl stop docker systemctl disable docker.service # start # 重载unit配置文件 systemctl daemon-reload # 启动Docker systemctl start docker # 设置开机自启 systemctl enable docker.service
镜像 Pull & Run(创建容器) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 镜像 docker images # docker run IMAGE:TAG docker run -it --ipc host --gpus all -v /data/shixx/face_swap/hififace:/workspace -v /data:/DATA --name hififace hififace:latent # 单次运行容器,运行后会终止运行 docker run ubuntu:latest /bin/echo 'Hello world' # 交互方式运行容器 (-i 保持常开,-t 分配终端访问容器) docker run -t -i ubuntu:latest /bin/bash # run -d 后台(守护方式)运行; # docker container logs ID 查看日志
cp镜像(save,load) 1 2 3 4 5 6 7 8 9 10 # save docker save 镜像名字:版本号 > /root/打包名字.tar docker save -o /root/打包名字.tar 镜像名字:版本号 # load docker load < /root/打包名字.tar docker load -i qwenllmcu117.tar # tag docker tag 镜像ID 镜像名字:版本号
run 1 2 3 4 5 6 7 8 9 docker run -d:后台运行容器(以守护进程模式)。 -it:交互式操作,通常与 -d 一起使用。 --name:为容器指定一个名称。 --rm:容器停止后自动删除容器文件系统。 -v:挂载主机目录到容器内部的指定路径。 -p,指定端口映射,格式:主机(宿主)端口:容器端口 -P,随机端口映射,容器内部端口随机映射到主机的端口 -u,以什么用户身份创建容器
容器 命令(启动,关闭,结束) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 容器查看 docker ps -a(查看已经暂停的容器实例) # start (启动终止状态 (exited)容器) docker start xxxID docker container start ID # exec # # Stop docker stop ID/Name # Kill docker kill ID/Name # restart docker restart xxxx
运行容器 4 方法 1、shell参数
1 2 docker run --rm ubuntu:22.04 /bin/sh -c \ "apt-get update && apt-get install -y curl && curl --version"
2、shell交互 (适合调试场景)
1 2 3 4 5 docker run -it --name temp-container ubuntu:22.04 /bin/bash # 容器内执行: apt-get update apt-get install -y vim exit
3、文件挂载
1 2 3 4 5 6 # 宿主机创建脚本 echo -e "#!/bin/bash\napt update\napt install -y git" > setup.sh chmod +x setup.sh # 挂载并执行 docker run -v $(pwd)/setup.sh:/script.sh ubuntu:22.04 /script.sh
4、复合命令
1 2 docker run --rm alpine:3.18 sh -c \ "echo 'Step 1'; sleep 2; echo 'Step 2'"
进入容器 exited 状态的容器,需要先start之后,才能进入
启动的容器,会有一个overlay的存储占用/var/lib/docker/overlay2/container_id
1 2 3 4 5 6 7 8 9 10 11 docker start [container ID] # docker exec docker exec -i 69d1 bash # 只运行命令,不进入容器 docker exec -it [container ID or NAMES] /bin/bash # exit (只需键入 exit 命令回车即可)当使用 exit 退出容器时,不会导致容器停止。# docker attch docker attach [container ID or NAMES] # exit 当使用 exit 退出容器时,容器停止。
导出容器、导入成镜像 1 2 3 4 5 6 7 8 9 10 # export docker ps -a docker export XXXID > redis.tar # import cat redis.tar | docker import - test/redis:v1.0 docker iamges # import URL/目录 容器 docker import http://example.com/exampleimage.tgz example/imagerepo
容器–commit->镜像 1 docker commit <container_id> <image_name>
docker容器打包成镜像并导出_mob64ca12e9cad4的技术博客_51CTO博客
Docker:通过容器生成镜像的三种方法_docker容器打包成镜像-CSDN博客
RM删除容器 1 2 3 4 5 6 7 # 删除 docker rm [container-ID or Name] # 强制删除 docker rm -f [container-ID or Name] # 删除所有已经停止运行的容器 docker container prune
自定义容器 Docker File(## Build With PATH(本地路径)) 1 docker build -t test :v1.0 .
这个 . 就表示 PATH。Docker-client 会将当前目录下的所有文件打包全部发送给 Docker-engine。Docker build使用
04-docker-commit构建自定义镜像
RUN Demo 1 docker run --rm --gpus all nvidia/cuda:11.0.3-base-ubuntu18.04 nvidia-smi
Docker中使用GPU原来是需要安装nvidia-docker2的(方法在下面),已经不需要了: 从docker 19.03开始,已经内置支持,不需要单独安装和设置了。
docker-compose 1 2 3 4 5 6 7 8 9 docker-compose up docker-compose up -d docker-compose stop docker-compose logs --- docker-compose restart --- docker-compose down docker-compose up -d
docker-compose gpu 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 version: '3.9' services: hififace: command: 'bash' image: 'hififace:latent2' container_name: demo_hifi working_dir: /data logging: options: max-size: 1g volumes: - '/databig_2:/databig_2' - '/databig:/databig' - '/data3:/data3' restart: unless-stopped ipc: host network_mode: host tty: true ports: - '6080:6080' deploy: resources: reservations: devices: - driver: "nvidia" count: "all" capabilities: ["gpu" ]
docker-compose.yaml文件编写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 version: "3.8" services: pdf: image: "xxxx:xxxxx" user: "root" restart: "on-failure" expose: - "22" - "51002-51003" ports: - "51001:22" - "51002-51003:51002-51003" shm_size: "4g" networks: - "ana" container_name: "literature_pdf" tty: "true" fig: image: "xxxxx:xxxxx" user: "root" restart: "on-failure" expose: - "22" - "51009-51020" ports: - "51008:22" - "51009-51020:51009-51020" shm_size: "8g" volumes: - "/data/elfin/utils/detectron2-master:/home/appuser/detectron2-master" environment: - "NVIDIA_VISIBLE_DEVICES=all" deploy: resources: reservations: devices: - driver: "nvidia" count: "all" capabilities: ["gpu" ] networks: sd_net: driver: bridge
Docker Mirror 镜像 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ocr: image: "xxxxx:xxxxx" user: "root" restart: "on-failure" volumes: - /etc/localtime:/etc/localtime:ro - /etc/timezone:/etc/timezone:ro expose: - "22" - "51005-51007" ports: - "51004:22" - "51005-51007:51005-51007" shm_size: "6g" deploy: resources: reservations: devices: - device_ids: ["1" ] capabilities: ["gpu" ] driver: "nvidia" networks: - "ana" container_name: "ocr" tty: "true" entrypoint: ["supervisord" , "-n" , "-c" , "/etc/supervisor/supervisord.conf" ] networks: ana: driver: bridge
下面是关于容器的GPU依赖配置:
1 2 3 4 5 6 7 deploy: resources: reservations: devices: - driver: "nvidia" count: "all" capabilities: ["gpu" ]
这里的capabilities是必须要指定的,而且count、driver、capabilities这是一组,不能每个加”-“,不然会报错。关于GPU的其他配置可以参考官方文档 https://docs.docker.com/compose/gpu-support/ 。
Docker 切换主Root路径 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 # 1 Stop systemctl stop docker.service systemctl status docker. # 2 主目录创建,copy mkdir /home/service/docker/ mv /var/lib/docker/* /home/service/docker/ # 3.法1 # 修改 docker.service 配置文件,使用 --graph 参数指定存储位置 vim /usr/lib/systemd/system/docker.service ExecStart=/usr/bin/dockerd --graph /data/docker -H fd:// --containerd=/run/containerd/containerd.sock # 3法2(测试过) vim /etc/docker/daemon.json { "registry-mirrors":["http://docker.mirrors.ustc.edu.cn"], "exec-opts": ["native.cgroupdriver=systemd"], "data-root": "/dockerdata/docker" } # 4 reload dockerserver systemctl daemon-reload systemctl restart docker # 5 check docker info | grep -i dir # Docker Root Dir: /data/docker
容器瘦身 查看 Docker 镜像的大小 查看 Docker 容器的大小 1 docker container ls --format "{{.ID}} {{.Size}}"
查看 Docker 系统的总体磁盘使用情况 FIX Issue
V100 515驱动,docker无法运行torch2.2.1-cu121;
解决方案,cu121的torch需要的驱动版本较高,建议升级到530及以上
驱动更新后,docker无法启动nVidia容器
1 2 3 4 5 6 7 root@ubuntu8:sdgradio# ../docker-compose up -d Starting sdgradio ... error ERROR: for sdgradio Cannot start service server: could not select device driver "nvidia" with capabilities: [[gpu]] ERROR: for server Cannot start service server: could not select device driver "nvidia" with capabilities: [[gpu]] ERROR: Encountered errors while bringing up the project.
解决方案
1 2 3 apt install nvidia-docker2 systemctl daemon-reload systemctl restart docker
完美解决
1 2 3 4 5 6 7 8 9 10 11 # 设置 udev 规则 # 在 WSL2 中,你需要设置 udev 规则以允许 Docker 容器访问摄像头。在 /etc/udev/rules.d 目录下创建一个文件 # ,例如 99-webcam.rules,并添加以下内容 KERNEL=="video*", SUBSYSTEM=="video4linux", MODE="0666", GROUP="video" # reload rulues sudo udevadm control --reload-rules && sudo udevadm trigger sudo usermod -aG docker $USER docker run -it --name my_ros_container -v /dev/bus/usb:/dev/bus/usb --device=/dev/video0:/dev/video0 my_ros_image /bin/bash
【WSL 2】在 Windows10 上配置 WSL 2 连接 USB 设备 D435i_usbipd: error: wsl kernel is not usbip capable; up-CSDN博客
REf # 如何在 Ubuntu 20.04 上安装和使用 Docker