RGA
RAG:全称Retrieval-Augmented Generation,检索增强生成。我们知道本次由ChatGPT掀起的LLM大模型浪潮,其核心就是Generation生成,而 Retrieval-augmented 就是指除了 LLM 本身已经学到的知识之外,通过外挂其他数据源的方式来增强 LLM 的能力,这其中就包括了外部向量数据库、外部知识图谱、文档数据,WEB数据等。
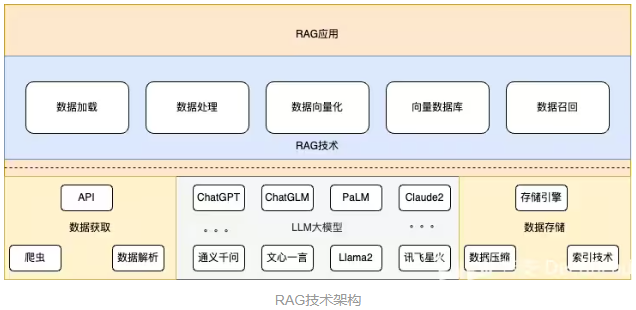
架构
如上图所示,经过Doc Loader,加载各种数据源的数据,经过embedding向量化后存储进向量数据库。这是Retrieval-augmented基础数据处理器。用户通过 QA向LLM提问,会通过QA问题向向量数据库召回相似度较高的上下文,通过Prompt提示词一起发给LLM,LLM通过问题与上下文一起生成答案返回给用户。
我们不经会问,为什么大模型动不动就千亿参数级别,涵盖了PB级的数据,还需要自己外挂数据源。
数据更新: LLM数据来源截止日期一般都是在2022年,而且它无法实时了解最新的信息。外挂知识库可以提供更新的、实时的信息,确保模型对新兴事实和领域内的最新发展有所了解。
领域专业知识: 尽快训练LLM的数据量很庞大,但是在某些特定领域,如医学、法律或科学,可能需要深入的专业知识。LLM在这些领域可能无法提供高度准确的信息,因此如果能提供这方面的数据,它能工作得好。
定制需求: 对于某些应用场景,用户可能需要LLM在特定方面的专业化,例如公司内部知识库、产品规格等。外挂知识库可以帮助模型更好地服务于特定用户或组织的需求。
避免错误: 在特定领域,LLM可能会生成不准确或误导性的信息。通过使用外挂知识库,可以提高答案的准确性,避免潜在的错误。 在实际应用中,外挂知识库通常与LLM进行集成,通过定制的方式来满足用户或企业的特殊需求,提供更专业、准确和个性化的服务。这种集成可以帮助弥补LLM通用性的不足,使其更好地适应特定的应用场景。
好,我们了解了RAG的基本概念,接下来我们就一起深入技术细节,了解RAG的实现原理。
技术实现(5-tech) 1 数据加载(Document Loaders) RAG的第一要解决的问题是数据来源的问题,数据有多种来源,各种格式的数据,如csv、html、json、markdown、PDF。所有的这些数据都需要有对应的Document Loaders来进行加工处理,将信息正确提取出来。
以langchain(LLM应用框架)为例,目前langchain社区中已经实现了154种文档加载器 如html:
1 2 from langchain_community.document_loaders import UnstructuredHTMLLoaderloader = UnstructuredHTMLLoader("example_data/fake-content.html" ) data = loader.load()
更多的文档加载器,可以访问langchain api
langchain–module-langchain_community.document_loaders
可以看到目前langchain社区目前涵盖了国内网诸多网站和平台的数据,如百度云盘、腾讯云文档,甚至包括了区块链信息
2 数据处理(Text Splitters) 数据分割 langchain api text_spiliters
加载完数据后,我们下一步通常需要将数据进行拆分,尤其是在处理长文本的情况下。如何将文本进行分割处理,听起来很简单,比如我按400个字符,直接切片就好了,但往往这样应用效果不甚理想。
我们通常希望能将将语义相关的文本片段保留在一起。 重点其实就在这个“语义相关”,比如中文,我们希望是句号为分割符,比如一段长代码,我们希望以编程语言特点来分割,比如Python中的def、class
以langchain为例,langchain目前支持HTML、字符、MarkdownHeader和多种代码分割,甚至正在实验中的语义分割。
1、按MarkdownHeader分割
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from langchain.text_splitter import MarkdownHeaderTextSplittermarkdown_document = "# Foo\n\n ## Bar\n\nHi this is Jim\n\nHi this is Joe\n\n ### Boo \n\n Hi this is Lance \n\n ## Baz\n\n Hi this is Molly" headers_to_split_on = [ ("#" , "Header 1" ), ("##" , "Header 2" ), ("###" , "Header 3" ), ] markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on) md_header_splits = markdown_splitter.split_text(markdown_document) md_header_splits {'content' : 'Hi this is Jim \nHi this is Joe' , 'metadata' : {'Header 1' : 'Foo' , 'Header 2' : 'Bar' }} {'content' : 'Hi this is Molly' , 'metadata' : {'Header 1' : 'Foo' , 'Header 2' : 'Baz' }}
2、按语义分割
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from langchain_experimental.text_splitter import SemanticChunkerfrom langchain_openai.embeddings import OpenAIEmbeddingswith open ("../../state_of_the_union.txt" ) as f: state_of_the_union = f.read() text_splitter = SemanticChunker(OpenAIEmbeddings()) docs = text_splitter.create_documents([state_of_the_union]) print (docs[0 ].page_content)Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court.
在进行文本分割的同时,我们还可以给分割的文本添加一下metadata的数据,方便记录该文本段的一些基本信息,如文章来源、作者信息等。
1 2 metadatas = [{"document" : 1 }, {"document" : 2 }] documents = text_splitter.create_documents( [state_of_the_union, state_of_the_union], metadatas=metadatas ) print (documents[0 ])
分割参数 在进行文本分割时,我们还需要重点关注两个参数 chunk_size 和 chunk_overlap,这两个参数分别表示分割长度和两段分割文本重合长度。
3 数据向量化 (Text embedding models) 在进行数据分割后,需要对文本数据段进行向量化,目前主流的中文向量化模型有
模型
中文支持
M3E
是
text2vec
是
OpenAlEmbeddings
是
使用OpenAIEmbeddings向量化处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from langchain_openai import OpenAIEmbeddingsembeddings_model = OpenAIEmbeddings(openai_api_key="..." ) embeddings = embeddings_model.embed_documents( [ "Hi there!" , "Oh, hello!" , "What's your name?" , "My friends call me World" , "Hello World!" ] ) len (embeddings), len (embeddings[0 ])(5 , 1536 )
目前Langchain支持37种embedding model,这些向量化模型核心功能就将文本向量化,提供给向量数据库进行存储
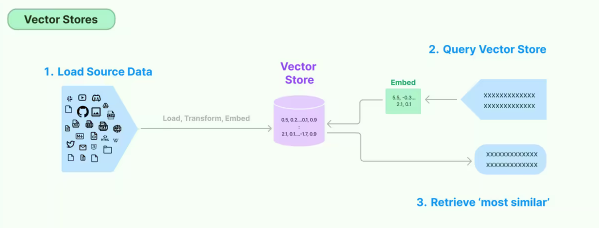
4 向量数据库 (Vector stores)
数据向量化后,就需要将向量数据存储进向量数据库。目前有很多开源向量数据库,如chromadb、faiss-cpu、lancedb。云服务厂商也陆续推出了向量数据库服务,包括腾讯云、阿里云的向量数据库
lancedb向量数据库使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from langchain_community.document_loaders import TextLoaderfrom langchain_openai import OpenAIEmbeddingsfrom langchain.text_splitter import CharacterTextSplitterfrom langchain_community.vectorstores import LanceDBimport lancedbdb = lancedb.connect("/tmp/lancedb" ) table = db.create_table( "my_table" , data=[ { "vector" : embeddings.embed_query("Hello World" ), "text" : "Hello World" , "id" : "1" , } ], mode="overwrite" , ) raw_documents = TextLoader('../../../state_of_the_union.txt' ).load() text_splitter = CharacterTextSplitter(chunk_size=1000 , chunk_overlap=0 ) documents = text_splitter.split_documents(raw_documents) db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table 作者:智安-DeedRead https://www.bilibili.com/read/cv29676672/ 出处:bilibili
如以Langchain VertorStore为基础类,实现的支持腾讯云的向量数据库服务 TencentVectorDB
目前Langchain支持47种向量数据库接入,开发者也可以自行实现VertorStore,定义自己的向量数据库。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 @abstractmethod def add_texts ( self, texts: Iterable[str ], metadatas: Optional [List [dict ]] = None , **kwargs: Any , ) -> List [str ]: """Run more texts through the embeddings and add to the vectorstore. Args: texts: Iterable of strings to add to the vectorstore. metadatas: Optional list of metadatas associated with the texts. kwargs: vectorstore specific parameters Returns: List of ids from adding the texts into the vectorstore. """ @abstractmethod def similarity_search ( self, query: str , k: int = 4 , **kwargs: Any ) -> List [Document]: """Return docs most similar to query.""" @classmethod @abstractmethod def from_texts ( cls: Type [VST], texts: List [str ], embedding: Embeddings, metadatas: Optional [List [dict ]] = None , **kwargs: Any , ) -> VST: """Return VectorStore initialized from texts and embeddings."""
add_texts: 将文本数据向量化,添加进向量数据库
similarity_search: 从向量数据库召回数据
from_texts:类方法,实现将文本数据向量化,添加进向量数据库
5 数据召回(Retrievers) 在讲解完数据加载、数据处理、数据向量化和向量数据库后,我们开始进入数据召回的环节。数据召回是我们向 LLM提问时,需要根据我们提问的问题向向量数据库召回相关的文档数据,并和问题加载进Prompt发送给LLM。
比如下面这段提示词:
1 2 3 4 5 6 template = """Answer the question based only on the following context: {context} Question: {question} """
context就是我们召回的上下文
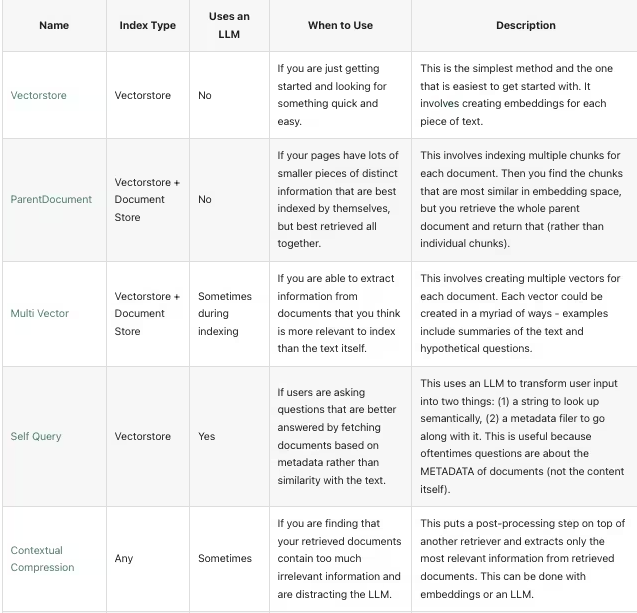
数据召回的方法有许多种,应用在不同应用场景,当前Langchain主流支持的Retrievers有以下8种
应用场景 这里简述一下不同Retrievers的主要应用场景,大家可以具体问题具体分析,再去查阅一下相关文档
Vectorstore 基础的向量召回方法,根据用户问题直接向向量数据库召回数据
ParentDocument 如果你文档数据有许多不同的小块信息,你可以根据问题检索出小块信息,再根据小块信息去索引出原文档或者更大块的数据,将大块数据作为上下文发送给LLM
Multi Vector 如果你有相关问题的数据集 ,可以为问题和文档分别存储到不同的向量数据库,在检索时可以根据问题检索出合适文档上下文
Self Query 如果你提出的问题可以通过基于元数据(而不是与文本的相似性)来获取文档,可以使用这种Retrievers,利用LLM的能力,自动生成对应的检索方法,来召回数据
Contextual Compression 如果您发现您检索的文档包含太多不相关的信息,并且分散了LLM的注意力,可以利用上下文压缩的方法,将召回的数据利用LLM进行数据处理
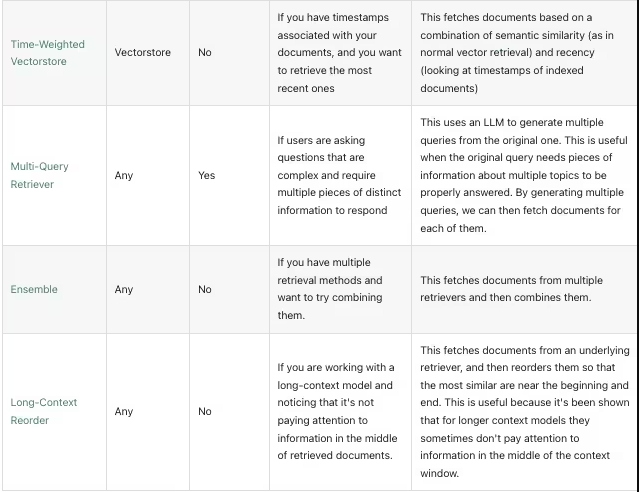
Time-Weighted Vectorstore 如果你的文档数据中包含时间相关的数据,可以考虑用此Retriever
Multi-Query Retriever 用户提出的问题很复杂,需要多个不同的信息来回答,可以使用此Retriever,利用LLM生成多个相关的问题,再分别从向量数据库召回数据
Ensemble 如果您有多种检索方法,并希望尝试将它们组合起来,可以使用此Retriever
Long-Context Reorder 当你需要召回多段上下文数据时,但发现LLM并没有根据你的上下文来回答问题时,可以考虑使用 Retriever对你召回的数据进行重新排序,将相似度较高的排在前面,让LLM能更好的利用上下文来回答问题
数据召回算法 在数据召回中,目前业内有两种较为通用的召回算法
1 相似度匹配算法(Similarity Search with Euclidean Distance)
这是向量数据库自身具备的特点,通过比较向量之间的距离来判断它们的相似度。
1 2 3 4 5 6 7 docs_with_score = db.max_marginal_relevance_search_with_score(query) for doc, score in docs_with_score:print ("-" * 80 )print ("Score: " , score)print (doc.page_content)print ("-" * 80 ) 作者:智安-DeedRead https://www.bilibili.com/read/cv29676672/ 出处:bilibili
2 最大边界相关算法(Maximal Marginal Relevance)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def maximal_marginal_relevance ( query_embedding: np.ndarray, embedding_list: list , lambda_mult: float = 0.5 , k: int = 4 , List [int ]: """Calculate maximal marginal relevance.""" if min (k, len (embedding_list)) <= 0 : return [] if query_embedding.ndim == 1 : query_embedding = np.expand_dims(query_embedding, axis=0 ) similarity_to_query = cosine_similarity(query_embedding, embedding_list)[0 ] most_similar = int (np.argmax(similarity_to_query)) idxs = [most_similar] selected = np.array([embedding_list[most_similar]]) while len (idxs) < min (k, len (embedding_list)): best_score = -np.inf idx_to_add = -1 similarity_to_selected = cosine_similarity(embedding_list, selected) for i, query_score in enumerate (similarity_to_query): if i in idxs: continue redundant_score = max (similarity_to_selected[i]) equation_score = ( lambda_mult * query_score - (1 - lambda_mult) * redundant_score ) if equation_score > best_score: best_score = equation_score idx_to_add = i idxs.append(idx_to_add) selected = np.append(selected, [embedding_list[idx_to_add]], axis=0 ) return idxs
我们可以在数据召回实践中,测试不同算法下的效果,来选择合适的算法。
总结 最后,我们对RAG进行一下总结。RAG底层依赖LLM大模型和数据获取、数据存储等相关技术,在RAG技术层面基于底层技术,共实现了数据加载、数据处理、数据向量化、向量数据库和数据召回等五种技术。可以使用这个5种技术,完成RAG应用实现。
REF 深入理解LLM RAG检索生成
LangChain+通义千问+AnalyticDB向量引擎保姆级教程_langchain 通义千问-CSDN博客