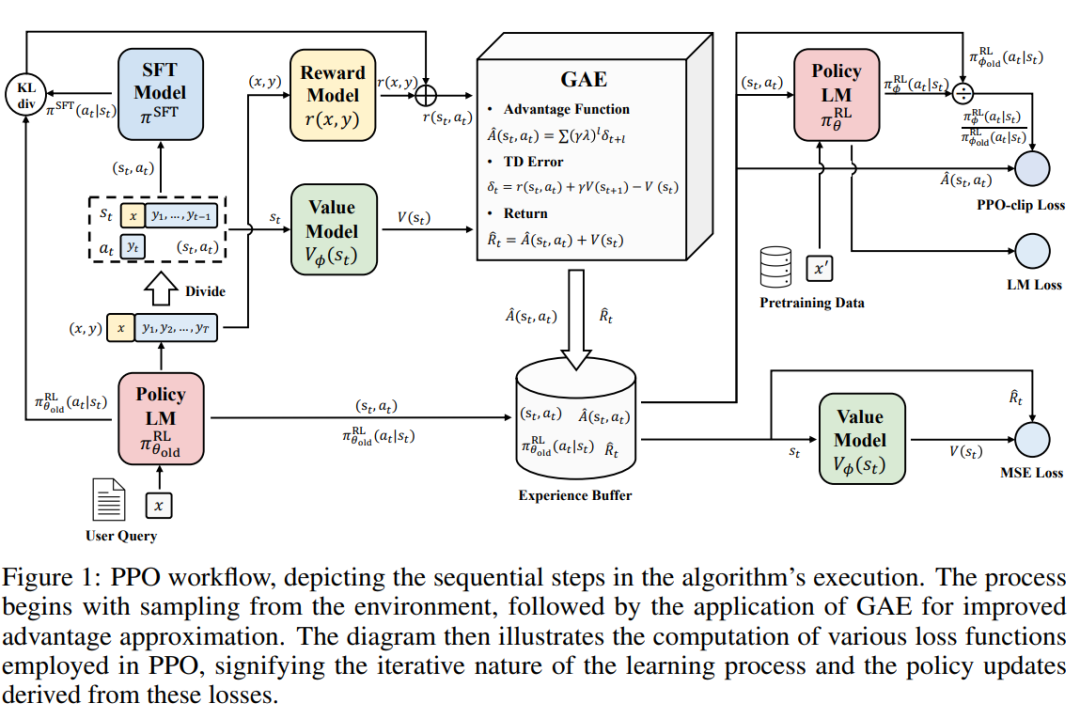
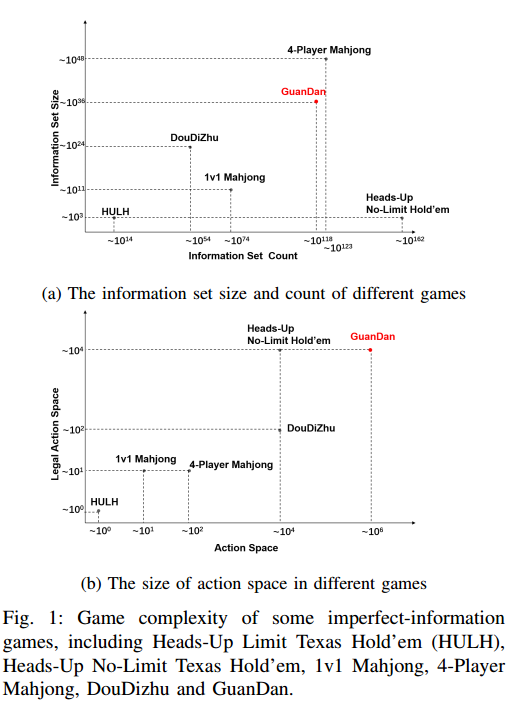
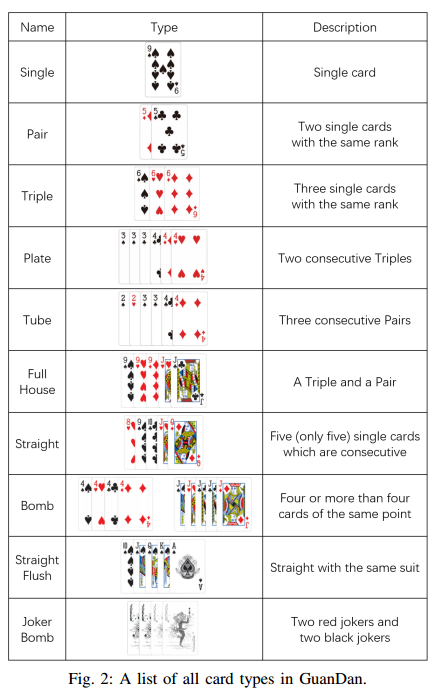
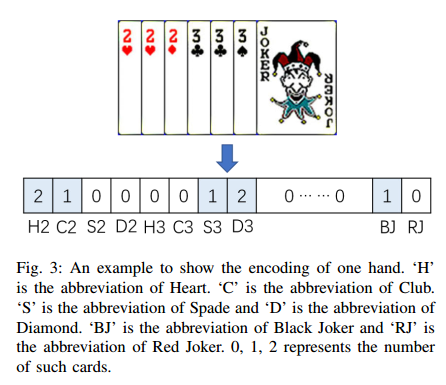
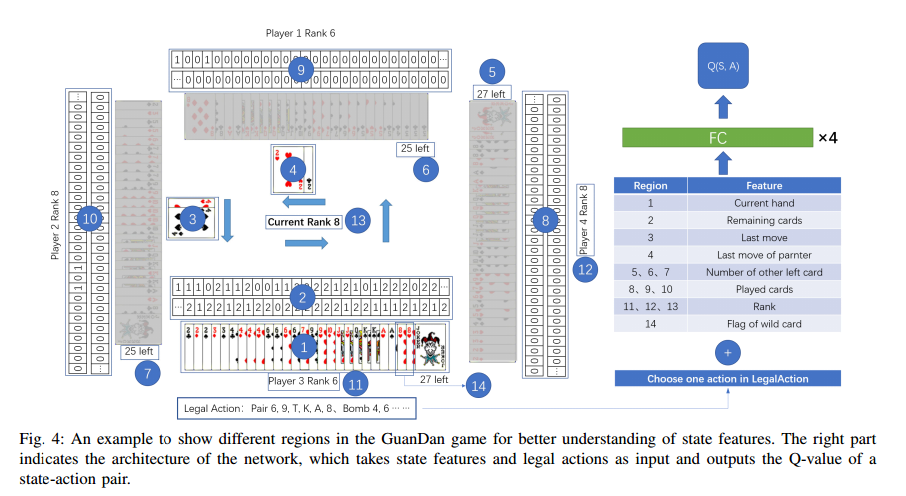
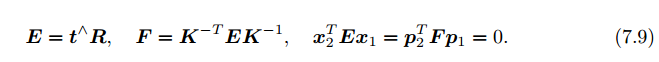1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
| from __future__ import print_function
import numpy as np
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
from PIL import ImageDraw
from yolov3_to_onnx import download_file
from data_processing import PreprocessYOLO, PostprocessYOLO, ALL_CATEGORIES
import sys, os
sys.path.insert(1, os.path.join(sys.path[0], ".."))
import common
TRT_LOGGER = trt.Logger()
def draw_bboxes(image_raw, bboxes, confidences, categories, all_categories, bbox_color='blue'):
"""Draw the bounding boxes on the original input image and return it.
Keyword arguments:
image_raw -- a raw PIL Image
bboxes -- NumPy array containing the bounding box coordinates of N objects, with shape (N,4).
categories -- NumPy array containing the corresponding category for each object,
with shape (N,)
confidences -- NumPy array containing the corresponding confidence for each object,
with shape (N,)
all_categories -- a list of all categories in the correct ordered (required for looking up
the category name)
bbox_color -- an optional string specifying the color of the bounding boxes (default: 'blue')
"""
draw = ImageDraw.Draw(image_raw)
print(bboxes, confidences, categories)
for box, score, category in zip(bboxes, confidences, categories):
x_coord, y_coord, width, height = box
left = max(0, np.floor(x_coord + 0.5).astype(int))
top = max(0, np.floor(y_coord + 0.5).astype(int))
right = min(image_raw.width, np.floor(x_coord + width + 0.5).astype(int))
bottom = min(image_raw.height, np.floor(y_coord + height + 0.5).astype(int))
draw.rectangle(((left, top), (right, bottom)), outline=bbox_color)
draw.text((left, top - 12), '{0} {1:.2f}'.format(all_categories[category], score), fill=bbox_color)
return image_raw
def get_engine(onnx_file_path, engine_file_path=""):
"""Attempts to load a serialized engine if available, otherwise builds a new TensorRT engine and saves it."""
def build_engine():
"""Takes an ONNX file and creates a TensorRT engine to run inference with"""
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = 1 << 30
builder.max_batch_size = 1
if not os.path.exists(onnx_file_path):
print('ONNX file {} not found, please run yolov3_to_onnx.py first to generate it.'.format(onnx_file_path))
exit(0)
print('Loading ONNX file from path {}...'.format(onnx_file_path))
with open(onnx_file_path, 'rb') as model:
print('Beginning ONNX file parsing')
parser.parse(model.read())
print('Completed parsing of ONNX file')
print('Building an engine from file {}; this may take a while...'.format(onnx_file_path))
engine = builder.build_cuda_engine(network)
print("Completed creating Engine")
with open(engine_file_path, "wb") as f:
f.write(engine.serialize())
return engine
if os.path.exists(engine_file_path):
print("Reading engine from file {}".format(engine_file_path))
with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
else:
return build_engine()
def main():
"""Create a TensorRT engine for ONNX-based YOLOv3-608 and run inference."""
onnx_file_path = 'yolov3.onnx'
engine_file_path = "yolov3.trt"
input_image_path = download_file('dog.jpg',
'https://github.com/pjreddie/darknet/raw/f86901f6177dfc6116360a13cc06ab680e0c86b0/data/dog.jpg', checksum_reference=None)
input_resolution_yolov3_HW = (608, 608)
preprocessor = PreprocessYOLO(input_resolution_yolov3_HW)
image_raw, image = preprocessor.process(input_image_path)
shape_orig_WH = image_raw.size
output_shapes = [(1, 255, 19, 19), (1, 255, 38, 38), (1, 255, 76, 76)]
trt_outputs = []
with get_engine(onnx_file_path, engine_file_path) as engine, engine.create_execution_context() as context:
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
print('Running inference on image {}...'.format(input_image_path))
inputs[0].host = image
trt_outputs = common.do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
trt_outputs = [output.reshape(shape) for output, shape in zip(trt_outputs, output_shapes)]
postprocessor_args = {"yolo_masks": [(6, 7, 8), (3, 4, 5), (0, 1, 2)],
"yolo_anchors": [(10, 13), (16, 30), (33, 23), (30, 61), (62, 45),
(59, 119), (116, 90), (156, 198), (373, 326)],
"obj_threshold": 0.6,
"nms_threshold": 0.5,
"yolo_input_resolution": input_resolution_yolov3_HW}
postprocessor = PostprocessYOLO(**postprocessor_args)
boxes, classes, scores = postprocessor.process(trt_outputs, (shape_orig_WH))
obj_detected_img = draw_bboxes(image_raw, boxes, scores, classes, ALL_CATEGORIES)
output_image_path = 'dog_bboxes.png'
obj_detected_img.save(output_image_path, 'PNG')
print('Saved image with bounding boxes of detected objects to {}.'.format(output_image_path))
if __name__ == '__main__':
main()
|