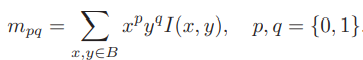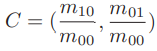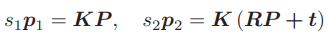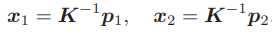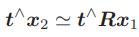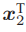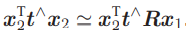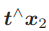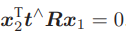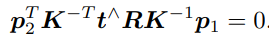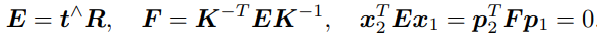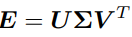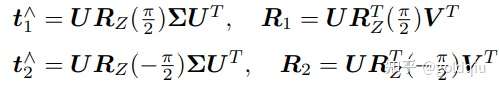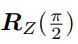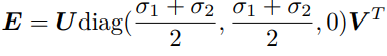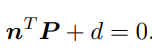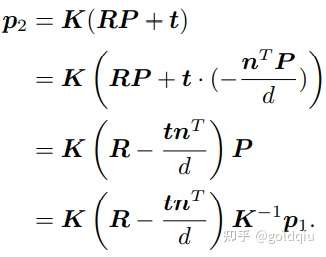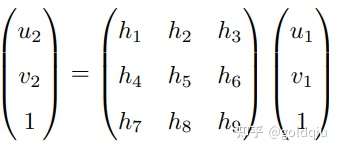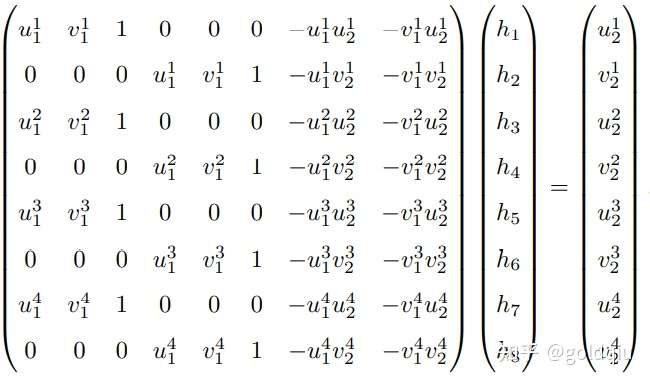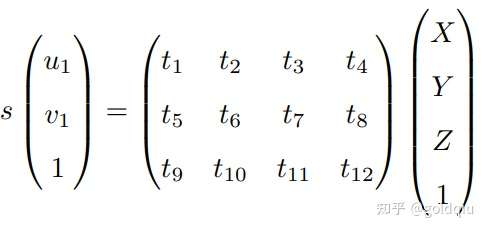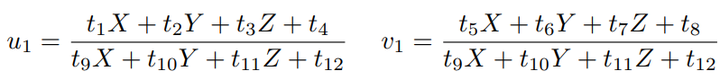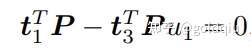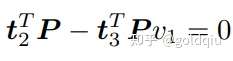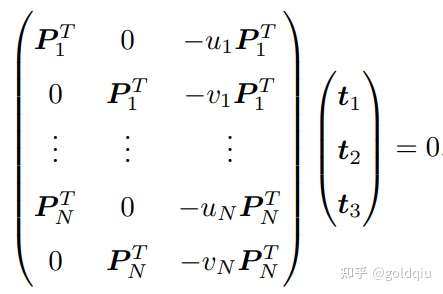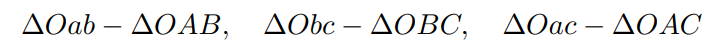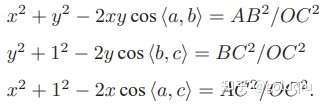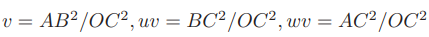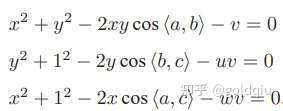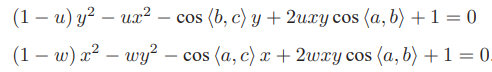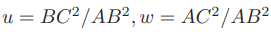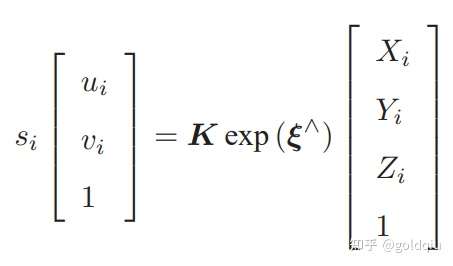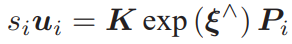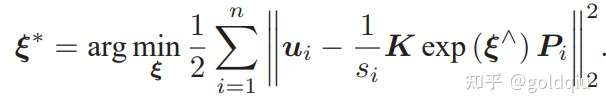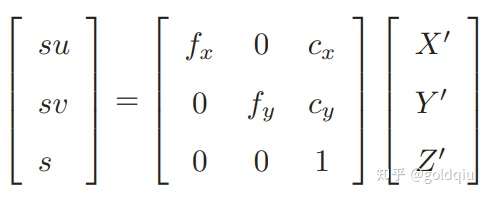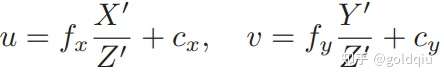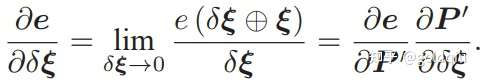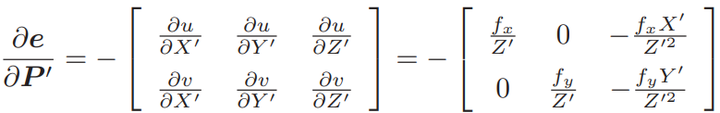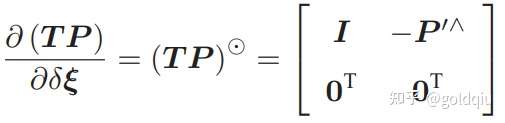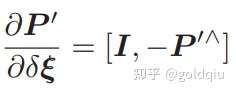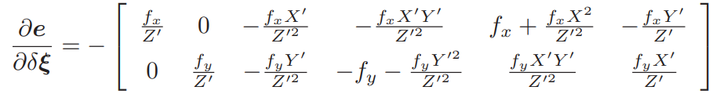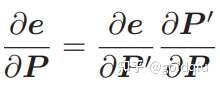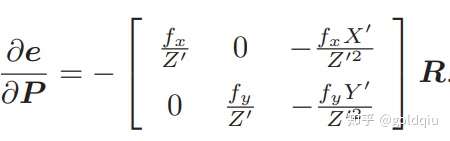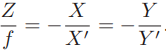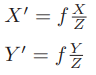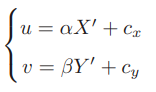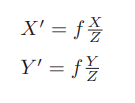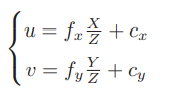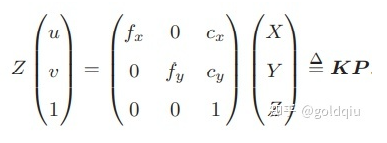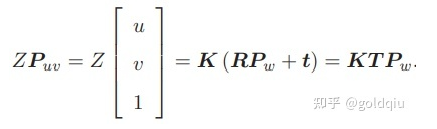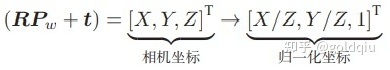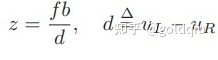// Optional, but useful to time-stamp the start of the log. // Will also detect verbosity level on command line as -v. // loguru::init(argc, argv);
// Put every log message in "everything.log": loguru::add_file("everything.log", loguru::Append, loguru::Verbosity_MAX);
// Only log INFO, WARNING, ERROR and FATAL to "latest_readable.log": loguru::add_file("latest_readable.log", loguru::Truncate, loguru::Verbosity_INFO);
// Only show most relevant things on stderr: // loguru::g_stderr_verbosity = 1;
LOG_SCOPE_F(INFO, "Will indent all log messages within this scope."); LOG_F(INFO, "I'm hungry for some %.3f!", 3.14159); LOG_F(2, "Will only show if verbosity is 2 or higher"); // VLOG_F(get_log_level(), "Use vlog for dynamic log level (integer in the range 0-9, inclusive)"); LOG_IF_F(ERROR, true, "Will only show if badness happens"); // auto fp = fopen(filename, "r"); std::string a = "Here is a string."; //CHECK_F(1 == 0, "Assertion 1 == 0 failed.\n '%s'\n '%d' ", a.c_str(), 1000); /// CHECK_GT_F(length, 0); // Will print the value of `length` on failure. /// CHECK_EQ_F(a, b, "You can also supply a custom message, like to print something: %d", a + b);
// Each function also comes with a version prefixed with D for Debug: /// DCHECK_F(expensive_check(x)); // Only checked #if !NDEBUG DLOG_F(INFO, "Only written in debug-builds");
// Turn off writing to stderr: loguru::g_stderr_verbosity = loguru::Verbosity_OFF;
// Turn off writing err/warn in red: loguru::g_colorlogtostderr = false; return0; }
st=>start: Start e=>end: End op1=>operation: 特征点 | past op2=>operation: ORB匹配 | past op3=>operation: 特征匹配 | past
st(right)->op1(right)->op2(right)->op3(right)->e
1、特征点法
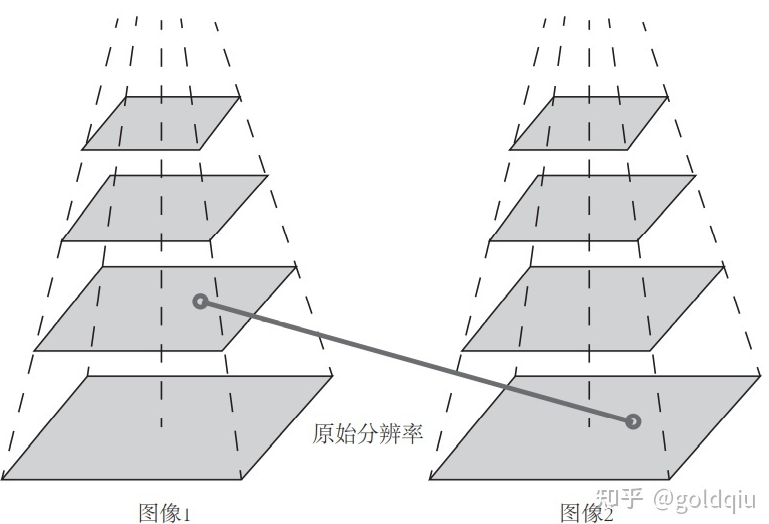
一个 SLAM 系统分为前端和后端,其中是视觉SLAM前端也称为视觉里程计(VO)。VO根据相邻图像的信息估计出粗略的相机运动,给后端提供较好的初始值。VO的算法主要分为两个大类:特征点法和直接法。基于特征点法的前端,被认为是视觉里程计的主流方法。它具有稳定,对光照、动态物体不敏感的优势,是目前比较成熟的解决方案。如何提取、匹配图像特征点,然后估计两帧之间的相机运动和场景结构,从而实现一个两帧间视觉里程计。这类算法也称为两视图几何(Two-view geometry)。
在提取 Oriented FAST 关键点后,对每个点计算其描述子。ORB使用改进的BRIEF特征描述。
BRIEF 是一种二进制描述子,其描述向量由许多个0和1组成,这里的0和1编码了关键点附近两个随机像素(比如 p 和 q)的大小关系:如果 p 比 q 大,则取 1,反之就取 0。如果取了 128 个这样的 p, q,最后就得到128维由 0、1 组成的向量。BRIEF 使用了随机选点的比较,速度非常快,而且由于使用了二进制表达,存储起来也十分方便,适用于实时的图像匹配。原始的 BRIEF描述子不具有旋转不变性,因此在图像发生旋转时容易丢失。而 ORB 在 FAST 特征点提取阶段计算了关键点的方向,所以可以利用方向信息,计算了旋转之后的“Steer BRIEF”特征使ORB 的描述子具有较好的旋转不变性。 由于考虑到了旋转和缩放,使得 ORB 在平移、旋转和缩放的变换下仍有良好的表现。同时,FAST和BREIF的组合也非常高效,使得ORB特征在实时SLAM中非常受欢迎。
1.3 特征匹配
特征匹配是视觉 SLAM 中极为关键的一步,解决了SLAM中的数据关联问题(data association),即确定当前看到的路标与之前看到的路标之间的对应关系。通过对图像与图像或者图像与地图之间的描述子进行准确匹配,可以为后续的姿态估计、优化等操作减轻大量负担。然而,由于图像特征的局部特性,误匹配的情况广泛存在,成为视觉SLAM中制约性能提升的一大瓶颈。部分原因是场景中经常存在大量的重复纹理,使得特征描述非常相似。在这种情况下,仅利用局部特征解决误匹配是非常困难的。
这八个方程构成了一个线性方程组。它的系数矩阵由特征点位置构成,大小为 8 × 9。 e 位于该矩阵的零空间中。如果系数矩阵是满秩的(即秩为 8),那么它的零空间维数为 1, 也就是 e 构成一条线。这与 e 的尺度等价性是一致的。如果八对匹配点组成的矩阵满足秩为 8 的条件,那么E的各元素就可由上述方程解得。
接下来的问题是如何根据已经估得的本质矩阵E,恢复出相机的运动 R, t。这个过程是由奇异值分解(SVD)得到的。设 E 的 SVD 分解为:
其中 U,V 为正交阵,Σ 为奇异值矩阵。根据 E 的内在性质,可以知道 Σ = diag(σ, σ, 0)。 在 SVD 分解中,对于任意一个 E,存在两个可能的 t, R 与它对应:
其中
表示沿 Z 轴旋转 90 度得到的旋转矩阵。同时,由于 −E 和 E 等价,所以对任意一个 t 取负号,也会得到同样的结果。因此,从 E 分解到 t, R 时,一共存在四个可能的解。只有第一种解中,P 在两个相机中都具有正的深度。因此,只要把任意一点代入四种解中,检测该点在两个相机下的深度,就可以确定哪个解是正确的了。
如果利用 E 的内在性质,那么它只有五个自由度。所以最小可以通过五对点来求解相机运动。然而这种做法形式复杂,从工程实现角度考虑,由于平时通常会有几十对乃至上百对的匹配点,从八对减至五对意义并不明显。剩下的问题还有一个:根据线性方程解出的 E,可能不满足 E 的内在性质——它的奇异值不一定为 σ, σ, 0 的形式。这时,在做 SVD 时会刻意地把 Σ 矩阵调整成上面的样子。通常的做法是,对八点法求得的 E 进行 SVD 分解后,会得到奇异值矩阵 Σ = diag(σ1, σ2, σ3),不妨设 σ1 ≥ σ2 ≥ σ3。取:
这相当于是把求出来的矩阵投影到了 E 所在的流形上。更简单的做法是将奇异值矩阵取成 diag(1, 1, 0),因为 E 具有尺度等价性,这样做也是合理的。
这种做法把H矩阵看成了向量,通过解该向量的线性方程来恢复H,又称直接线性变换法(Direct Linear Transform)。求出单应矩阵以后需要对其进行分解,才可以得到相应的旋转矩阵 R 和平移向量 t。分解的方法包括数值法与解析法 。单应矩阵的分解会返回四组旋转矩阵与平移向量,并且同时可以计算出它们分别对应的场景点所在平面的法向量。如果已知成像的地图点的深度全为正值(即在相机前方),则又可以排除两组解。最后仅剩两组解,这时需要通过更多的先验信息进行判断。通常可以通过假设已知场景平面的法向量来解决,如场景平面 与相机平面平行,那么法向量n的理论值为1。
单应性在 SLAM 中具有重要意义。当特征点共面,或者相机发生纯旋转的时候,基础矩阵的自由度下降,这就出现了所谓的退化(degenerate)。现实中的数据总包含一些噪声, 这时候如果继续使用八点法求解基础矩阵,基础矩阵多余出来的自由度将会主要由噪 声决定。为了能够避免退化现象造成的影响,通常会同时估计基础矩阵 F 和单应矩阵 H,选择重投影误差比较小的那个作为最终的运动估计矩阵。
build/pose_estimation_2d2d 1.png 2.png -- Max dist : 95.000000 -- Min dist : 4.000000 一共找到了 79 组匹配点 fundamental_matrix is [4.844484382466111e-06, 0.0001222601840188731, -0.01786737827487386; -0.0001174326832719333, 2.122888800459598e-05, -0.01775877156212593; 0.01799658210895528, 0.008143605989020664, 1] essential_matrix is [-0.0203618550523477, -0.4007110038118445, -0.03324074249824097; 0.3939270778216369, -0.03506401846698079, 0.5857110303721015; -0.006788487241438284, -0.5815434272915686, -0.01438258684486258] homography_matrix is [0.9497129583105288, -0.143556453147626, 31.20121878625771; 0.04154536627445031, 0.9715568969832015, 5.306887618807696; -2.81813676978796e-05, 4.353702039810921e-05, 1] R is [0.9985961798781875, -0.05169917220143662, 0.01152671359827873; 0.05139607508976055, 0.9983603445075083, 0.02520051547522442; -0.01281065954813571, -0.02457271064688495, 0.9996159607036126] t is [-0.8220841067933337; -0.03269742706405412; 0.5684264241053522] t^R= [0.02879601157010516, 0.5666909361828478, 0.04700950886436416; -0.5570970160413605, 0.0495880104673049, -0.8283204827837456; 0.009600370724838804, 0.8224266019846683, 0.02034004937801349] epipolar constraint = [0.002528128704106625] epipolar constraint = [-0.001663727901710724] epipolar constraint = [-0.0008009088410884102
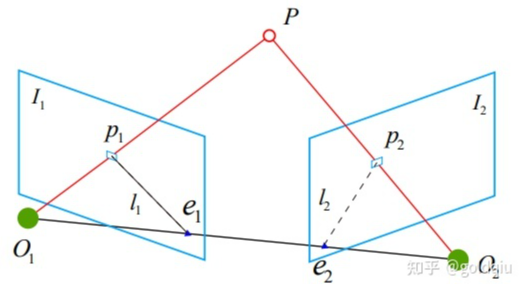
可以看出,对极约束的满足精度约在 10−3 量级。OpenCV 使用三角化检测角点的深度是否为正,从而选出正确的解。 对极约束是从 x2 = Rx1 + t 得到的。这里的 R, t 组成的变换矩阵,是第一个图到第二个图的坐标变换矩阵: x2 = T21x1.
4.1 讨论
从演示程序中可以看到,输出的 E 和 F 相差了相机内参矩阵。从 E,F 和 H 都可以分解出运动,不过 H 需要假设特征点位于平面上。 由于 E 本身具有尺度等价性,它分解得到的 t, R 也有一个尺度等价性。而 R ∈ SO(3) 自身具有约束,所以认为 t 具有一个尺度。换言之,在分解过程中,对 t 乘以任意非零常数,分解都是成立的。因此通常把 t 进行归一化,让它的长度等于 1。
尺度不确定性
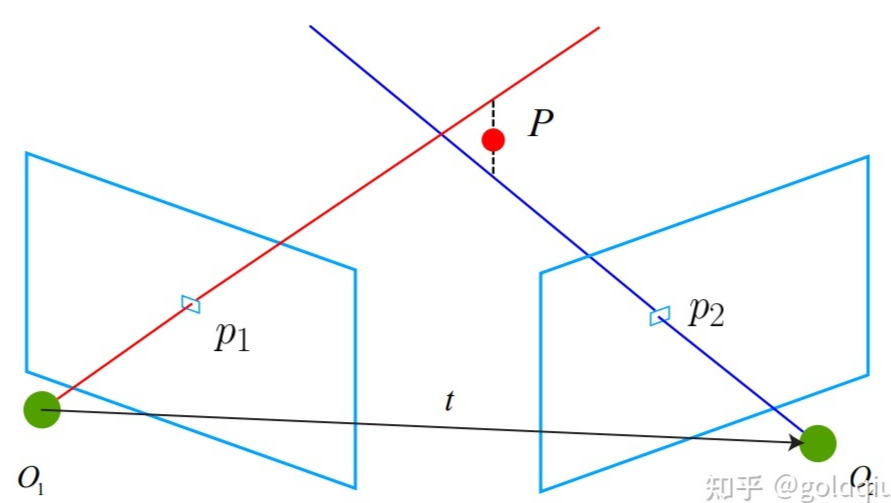
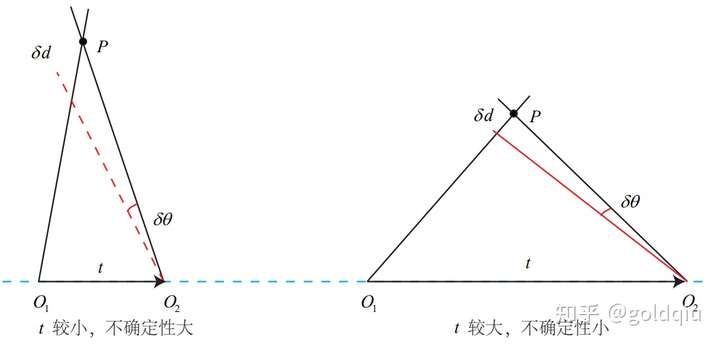
对 t 长度的归一化,直接导致了单目视觉的尺度不确定性(Scale Ambiguity)。例如,程序中输出的 t 第一维约 0.822。这个 0.822 究竟是指 0.822 米呢,还是 0.822 厘米 呢,是没法确定的。因为对 t 乘以任意比例常数后,对极约束依然是成立的。换言之, 在单目 SLAM 中,对轨迹和地图同时缩放任意倍数,得到的图像依然是一样的。 在单目视觉中,对两张图像的 t 归一化,相当于固定了尺度。虽然不知道它的实际长度为多少,但以这时的 t 为单位 1,计算相机运动和特征点的 3D 位置。这被称为单目 SLAM 的初始化。在初始化之后,就可以用 3D-2D 来计算相机运动了。初始化之后的轨迹和地图的单位,就是初始化时固定的尺度。因此,单目 SLAM 有一步不可避免的初始化。初始化的两张图像必须有一定程度的平移,而后的轨迹和地图都将以此步的平移为单位。 除了对 t 进行归一化之外,另一种方法是令初始化时所有的特征点平均深度为 1,也 可以固定一个尺度。相比于令 t 长度为 1 的做法,把特征点深度归一化可以控制场景的规模大小,使计算在数值上更稳定些。
初始化的纯旋转问题
从 E 分解到 R, t 的过程中,如果相机发生的是纯旋转,导致 t 为零,那么,得到的 E 也将为零,这将导致无从求解 R。不过,此时可以依靠 H 求取旋转,但仅有旋转时,无法用三角测量估计特征点的空间位置,于是,另一个结论是,单目初始化不能只有纯旋转,必须要有一定程度的平移。如果没有平移,单目将无法初始化。在实践当中,如果初始化时平移太小,会使得位姿求解与三角化结果不稳定, 从而导致失败。相对的,如果把相机左右移动而不是原地旋转,就容易让单目 SLAM 初始化。
point in the first camera frame: [0.0844072, -0.0734976] point projected from 3D [0.0843702, -0.0743606], d=14.9895 point in the second camera frame: [0.0431343, -0.0459876] point reprojected from second frame: [0.04312769812378599, -0.04515455276163744, 1]
PnP(Perspective-n-Point)是求解 3D 到 2D 点对运动的方法。它描述了当知道 n 个 3D 空间点以及它们的投影位置时,如何估计相机所在的位姿。前面的2D-2D 的对极几何方法需要八个或八个以上的点对(以八点法为例),且存在着初始化、纯旋转和尺度的问题。然而,如果两张图像中,其中一张特征点的 3D 位置已知,那么最少只需三个点对(需要至少一个额外点验证结果)就可以估计相机运动。特征点的 3D 位置可以由三角化,或者由RGB-D 相机的深度图确定。因此,在双目或 RGB-D 的视觉里程计中, 可以直接使用 PnP 估计相机运动。而在单目视觉里程计中,必须先进行初始化,然后才能使用 PnP。3D-2D 方法不需要使用对极约束,又可以在很少的匹配点中获得较好的运动估计,是最重要的一种姿态估计方法。 PnP 问题有很多种求解方法,例如用三对点估计位姿的P3P,直接线性变换(DLT), EPnP(Efficient PnP),UPnP等等。此外,还能用非线性优化的方式,构建最小二乘问题并迭代求解,也就是万金油式的 Bundle Adjustment。
7.1 直接线性变换
考虑某个空间点 P,它的齐次坐标为 P = (X, Y, Z, 1)T。在图像 I1 中,投影到特征点 x1 = (u1, v1, 1)T(以归一化平面齐次坐标表示)。此时相机的位姿 R, t 是未知的。与单应矩阵的求解类似,定义增广矩阵 [R|t] 为一个 3 × 4 的矩阵,包含了旋转与平移信息。展开形式列写如下:
用最后一行把 s 消去,得到两个约束:
定义 T 的行向量: t1 = (t1, t2, t3, t4) T , t2 = (t5, t6, t7, t8) T , t3 = (t9, t10, t11, t12) T , 于是有:
t 是待求的变量,可以看到每个特征点提供了两个关于 t 的线性约束。假设一共有 N 个特征点,可以列出线性方程组:
由于 t 一共有 12 维,因此最少通过六对匹配点,即可实现矩阵 T 的线性求解,这种方法称为直接线性变换(Direct Linear Transform,DLT)。当匹配点大于六对时,可以使用 SVD 等方法对超定方程求最小二乘解。 在 DLT 求解中,直接将 T 矩阵看成了 12 个未知数,忽略了它们之间的联系。因为旋转矩阵 R ∈ SO(3),用 DLT 求出的解不一定满足该约束,它是一个一般矩阵。平移向量属于向量空间,对于旋转矩阵 R,必须针对 DLT 估计的 T 的左边寻找一个最好的旋转矩阵对它进行近似。这可以由 QR 分解完成, 相当于把结果从矩阵空间重新投影到 SE(3) 流形上,转换成旋转和平移两部分。 这里的 x1 使用了归一化平面坐标,去掉了内参矩阵 K 的影响 ——这是因为内参 K 在 SLAM 中通常假设为已知。如果内参未知,也能用 PnP 去估计 K, R, t 三个量。然而由于未知量的增多,效果会差一些。
7.7.2 P3P
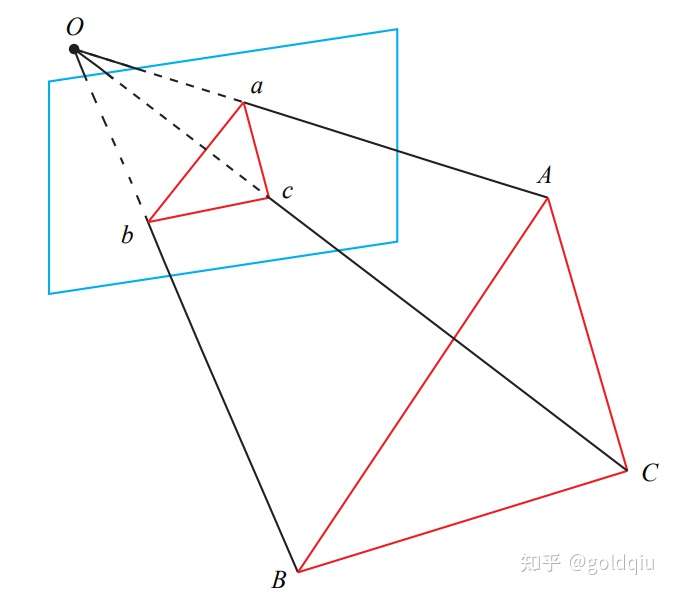
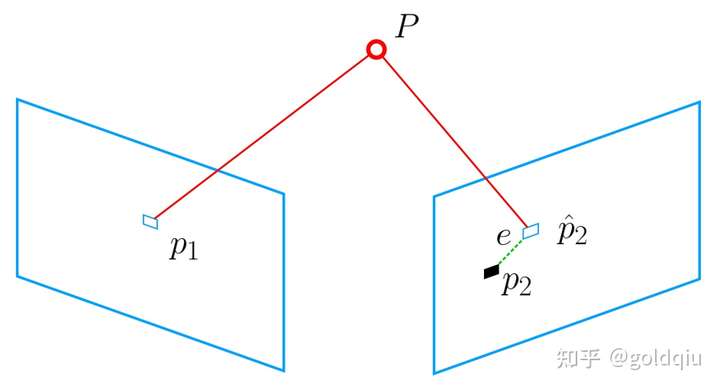
P3P仅使用三对匹配点,对数据要求较少,需要利用给定的三个点的几何关系。它的输入数据为三对 3D-2D 匹配点。记 3D 点为 A, B, C,2D 点为 a, b, c,其中小写字母代表的点为大写字母在相机成像平面上的投影,如图所示。
此外,P3P 还需要使用一对验证点,以从可能的解出选出正确的那一个(类似于对极几何情形)。记验证点对为 D − d,相机光心为 O。注意,预知的是 A, B, C 在世界坐标系中的坐标,而不是在相机坐标系中的坐标。一旦3D 点在相机坐标系下的坐标能够算出,就得到了 3D-3D 的对应点,把 PnP 问题转换为了 ICP 问题。三角形之间存在对应关系:
可以通过 A, B, C 在世界坐标系下的坐标算出,变换到相机坐标系下之后,并不改变这个比值。该式中的 x, y 是未知的,随着相机移动会发生变化。因此,该方程组是关于 x, y 的一个二元二次方程(多项式方程)。解析地求解该方程组是一个复杂的过程,需要用吴消元法。类似于分解 E 的情况,该方程最多可能得到四个解,但可以用验证点来计算最可能的解,得到 A, B, C 在相机坐标系下的 3D 坐标。然后,根据 3D-3D 的点对,计算相机的运动 R, t。
从 P3P 的原理上可以看出,为了求解 PnP,利用了三角形相似性质,求解投影点 a, b, c 在相机坐标系下的 3D 坐标,最后把问题转换成一个 3D 到 3D 的位姿估计问题。
P3P 也存在着一些问题:
P3P 只利用三个点的信息。当给定的配对点多于 3 组时,难以利用更多的信息。
如果 3D 点或 2D 点受噪声影响,或者存在误匹配,则算法失效。 所以后续人们还提出了许多别的方法,如 EPnP、UPnP 等。它们利用更多的信息,而且用迭代的方式对相机位姿进行优化,以尽可能地消除噪声的影响。在 SLAM 当中,通常的做法是先使用 P3P/EPnP 等方法估计相机位姿,然后构建最小二乘优化问题对估计值进行调整(Bundle Adjustment)。
首先用 OpenCV 提供的 EPnP 求 解 PnP 问题,然后通过 g2o 对结果进行优化。由于 PnP 需要使用 3D 点,为了避免初始化带来的麻烦,使用了 RGB-D 相机中的深度图(1_depth.png),作为特征点的 3D 位置。
代码为: slambook/ch7/pose_estimation_3d2d.cpp
在例程中,得到配对特征点后,在第一个图的深度图中寻找它们的深度,并求出空间位置。以此空间位置为 3D 点,再以第二个图像的像素位置为 2D 点,调用 EPnP 求解 PnP 问题。程序输出后可以看到,在有3D信息时,估计的 R 几乎是相同的,而 t 相差的较多。这是由于引入了新的深度信息所致。 不过,由于 Kinect 采集的深度图本身会有一些误差,所以这里的 3D 点也不是准确的。后面会希望把位姿 ξ 和所有三维特征点 P 同时优化。
8.2 使用 BA 优化
使用前一步的估计值作为初始值,把问题建模成一个最小二乘的图优化问题,如图所示。
在这个图优化中,节点和边的选择为:
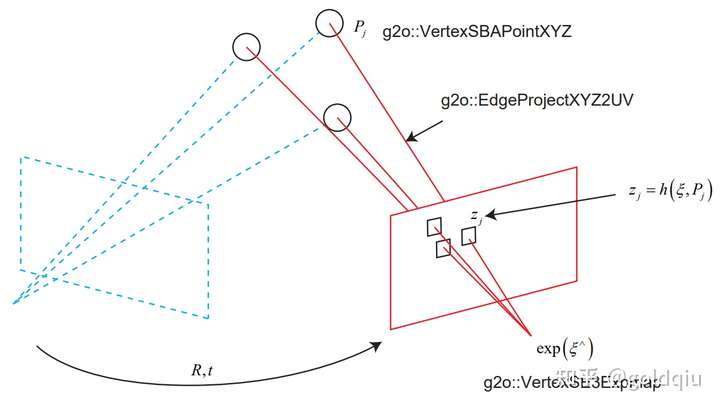
节点:第二个相机的位姿节点 ξ ∈ se(3),以及所有特征点的空间位置 P ∈ R3。
边:每个 3D 点在第二个相机中的投影,以观测方程来描述: zj = h(ξ, Pj ).
由于第一个相机位姿固定为零,没有把它写到优化变量里。现在根据一组 3D 点和第二个图像中的 2D 投影,估计第二个相机的位姿。所以把第一个相机画成虚线,表明不希望考虑它。 g2o 提供了许多关于 BA 的节点和边,不必自己从头实现所有的计算。在 g2o/types/sba/types_six_dof_expmap.h 中提供了李代数表达的节点和边。文件中有VertexSE3Expmap(李代数位姿)、VertexSBAPointXYZ(空间点位置) 和 EdgeProjectXYZ2UV(投影方程边)这三个类。
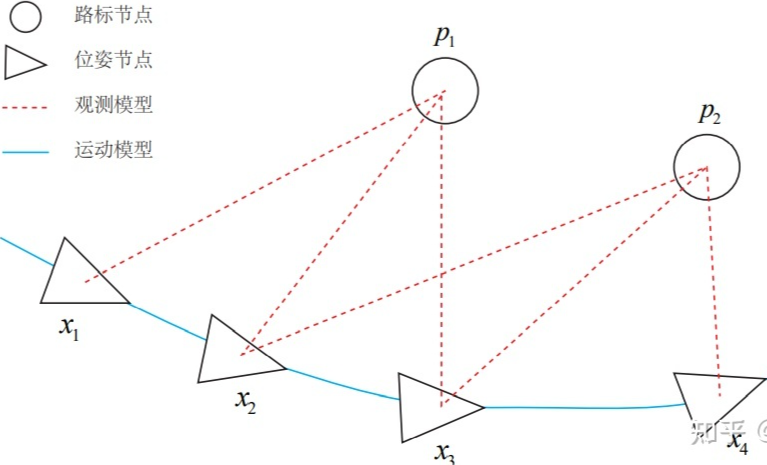
增量方法仅关心当前时刻的状态估计xk,而对之前的状态则不多考虑;相对地,批量方法可以在更大的范围达到最优化,被认为优于传统的滤波器,成为当前视觉SLAM的主流方法。极端情况下,可以让机器人或无人机收集所有时刻的数据,再带回计算中心统一处理,这也正是SfM(Structure from Motion)的主流做法。这种极端情况不实时,不符合SLAM的运用场景。所以在SLAM中,实用的方法通常是一些折中的手段。比如,固定一些历史轨迹,仅对当前时刻附近的一些轨迹进行优化,这就是滑动窗口估计法。还有因子图增量平滑优化的方法,能够增量增加优化问题并进行动态调整,能够达到有滤波器的速度和图优化的精度。
这样就得到了一个最小二乘问题(Least Square Problem),它的解等价于状态的最大似然估计。直观上看,由于噪声的存在,当我们把估计的轨迹与地图代入 SLAM 的运动、观测方程中时,它们并不会完美地成立。这时对状态的估计值进行微调,使得整体的误差下降一些。当然这个下降也有限度,它一般会到达一个极小值。这就是一个典型非线性优化的过程。
解此方程,就得到了导数为零处的极值,可能是极大,极小或鞍点处的值。只要逐个比较函数值大小即可。如果 f 为简单的线性函数,那么这个问题就是简单的线性最小二乘问题,但是有些导函数形式复杂,使得该方程不容易求解。求解这个方程需要知道关于目标函数的全局性质,而通常这是不大可能的。对于不方便直接求解的最小二乘问题,可以用迭代的方式,从一个初始值出发,不断地更新当前的优化变量,使目标函数下降。具体步骤可列写如下:
给定某个初始值x0。
对于第 k 次迭代,寻找一个增量 ∆xk,使得
$$ || f(x_k + \Delta x_k) ||^2_2 $$
达到极小值。
若 ∆xk 足够小,则停止。
否则,令x(k+1) = xk + ∆xk,返回第 2 步。
这让求解导函数为零的问题变成了一个不断寻找下降增量 ∆xk 的问题。由于可以对 f 进行线性化,增量的计算将简单很多。当函数下降直到增量非常小的时候,就认为算法收敛,目标函数达到了一个极小值。在这个过程中,问题在于如何找到每次迭代点的增量,而这是一个局部的问题,只需要关心 f 在迭代值处的局部性质而非全局性质。这类方法在最优化、机器学习等领域应用非常广泛。
下面是如何寻找这个增量 ∆xk的方法。
2.1 一阶和二阶梯度法
考虑第 k 次迭代,假设在xk处,想要找到增量 ∆xk,最直观的方式是将目标函数在xk附近进行泰勒展开:
列文伯格—马夸尔特方法在一定程度上修正了这些问题,比高斯牛顿法更为鲁棒,但收敛速度会比高斯牛顿法更慢,被称为阻尼牛顿法(Damped Newton Method)。
2.3 列文伯格—马夸尔特方法
高斯牛顿法中采用的近似二阶泰勒展开只能在展开点附近有较好的近似效果,所以应该给∆x添加一个范围,称为信赖区域(Trust Region)。这个范围定义了在什么情况下二阶近似是有效的,这类方法也称为信赖区域方法(Trust Region Method)。在信赖区域里边,近似是有效的;出了这个区域,近似可能会出问题。
[31] J. Nocedal and S. Wright, Numerical Optimization. Springer Science & Business Media, 2006.
以高斯牛顿法和列文伯格—马夸尔特方法为代表的优化方法,在很多开源的优化库中都已经实现并提供给用户。最优化是处理许多实际问题的基本数学工具,不光在视觉 SLAM 中起着核心作用,在类似于深度学习等其他领域,它也是求解问题的核心方法之一(深度学习数据量很大,以一阶方法为主)。
无论是高斯牛顿法还是列文伯格—马夸尔特方法,在做最优化计算时,都需要提供变量的初始值。这个初始值不能随意设置。实际上非线性优化的所有迭代求解方案,都需要用户来提供一个良好的初始值。由于目标函数太复杂,导致在求解空间上的变化难以预测,对问题提供不同的初始值往往会导致不同的计算结果。这种情况是非线性优化的通病:大多数算法都容易陷入局部极小值。因此,无论是哪类科学问题,提供初始值都应该有科学依据,例如视觉 SLAM 问题中,会用 ICP、PnP 之类的算法提供优化初始值(视觉前端)。一个良好的初始值对最优化问题非常重要。
int a = sizeof( programNames)/sizeof( programNames[0]); for (int i = 0; i < a; i++) { cout << "Send data for " << programNames[i][1] << endl; string body = constructBody(programNames[i], file); char header[1024]; // cout << header sprintf(header, "POST %s HTTP1.1 \r\n" "Host: %s\r\n" "Content-Length: %d\r\n" "Content-Type: multipart/from-data; boundary=%s\r\n" "Accept-Charset: utf-8\r\n\r\n", RECEIVER, IP, strlen(body.c_str()), BOUNDARY);
cout << header << endl; // int p = send(dataSock, header, strlen(header), 0); // int k = send(dataSock, body.c_str(), strlen(body.c_str()), 0); char buf[64] = "My UDP"; // int t = send(dataSock, buf, strlen(buf), 0); int t = send(dataSock, buf, 64, 0);
classSocketfinal { public: #if defined(_WIN32) || defined(__CYGWIN__) using Type = SOCKET; staticconstexpr Type invalid = INVALID_SOCKET; #else using Type = int; staticconstexpr Type invalid = -1; #endif// defined(_WIN32) || defined(__CYGWIN__)
explicitSocket(const InternetProtocol internetProtocol): endpoint{socket(getAddressFamily(internetProtocol), SOCK_STREAM, IPPROTO_TCP)} { if (endpoint == invalid) throw std::system_error{getLastError(), std::system_category(), "Failed to create socket"};
#if defined(_WIN32) || defined(__CYGWIN__) ULONG mode = 1; if (ioctlsocket(endpoint, FIONBIO, &mode) != 0) { close(); throw std::system_error{WSAGetLastError(), std::system_category(), "Failed to get socket flags"}; } #else constauto flags = fcntl(endpoint, F_GETFL); if (flags == -1) { close(); throw std::system_error{errno, std::system_category(), "Failed to get socket flags"}; }
if (fcntl(endpoint, F_SETFL, flags | O_NONBLOCK) == -1) { close(); throw std::system_error{errno, std::system_category(), "Failed to set socket flags"}; } #endif// defined(_WIN32) || defined(__CYGWIN__)
#ifdef __APPLE__ constint value = 1; if (setsockopt(endpoint, SOL_SOCKET, SO_NOSIGPIPE, &value, sizeof(value)) == -1) { close(); throw std::system_error{errno, std::system_category(), "Failed to set socket option"}; } #endif// __APPLE__ }
while (result == -1 && WSAGetLastError() == WSAEINTR) result = ::send(endpoint, reinterpret_cast<constchar*>(buffer), static_cast<int>(length), 0);
if (result == -1) throw std::system_error{WSAGetLastError(), std::system_category(), "Failed to send data"}; #else auto result = ::send(endpoint, reinterpret_cast<constchar*>(buffer), length, noSignal);
while (result == -1 && errno == EINTR) result = ::send(endpoint, reinterpret_cast<constchar*>(buffer), length, noSignal);
if (result == -1) throw std::system_error{errno, std::system_category(), "Failed to send data"}; #endif// defined(_WIN32) || defined(__CYGWIN__) returnstatic_cast<std::size_t>(result); }
while (result == -1 && WSAGetLastError() == WSAEINTR) result = ::recv(endpoint, reinterpret_cast<char*>(buffer), static_cast<int>(length), 0);
if (result == -1) throw std::system_error{WSAGetLastError(), std::system_category(), "Failed to read data"}; #else auto result = ::recv(endpoint, reinterpret_cast<char*>(buffer), length, noSignal);
while (result == -1 && errno == EINTR) result = ::recv(endpoint, reinterpret_cast<char*>(buffer), length, noSignal);
if (result == -1) throw std::system_error{errno, std::system_category(), "Failed to read data"}; #endif// defined(_WIN32) || defined(__CYGWIN__) returnstatic_cast<std::size_t>(result); }
// RFC 7230, 3.2.3. WhiteSpace template <typename C> constexprboolisWhiteSpaceChar(const C c)noexcept { return c == 0x20 || c == 0x09; // space or tab };
// RFC 5234, Appendix B.1. Core Rules template <typename C> constexprboolisDigitChar(const C c)noexcept { return c >= 0x30 && c <= 0x39; // 0 - 9 }
// RFC 5234, Appendix B.1. Core Rules template <typename C> constexprboolisAlphaChar(const C c)noexcept { return (c >= 0x61 && c <= 0x7A) || // a - z (c >= 0x41 && c <= 0x5A); // A - Z }
// RFC 7230, 3.2.6. Field Value Components template <typename C> constexprboolisTokenChar(const C c)noexcept { return c == 0x21 || // ! c == 0x23 || // # c == 0x24 || // $ c == 0x25 || // % c == 0x26 || // & c == 0x27 || // ' c == 0x2A || // * c == 0x2B || // + c == 0x2D || // - c == 0x2E || // . c == 0x5E || // ^ c == 0x5F || // _ c == 0x60 || // ` c == 0x7C || // | c == 0x7E || // ~ isDigitChar(c) || isAlphaChar(c); };
// RFC 5234, Appendix B.1. Core Rules template <typename C> constexprboolisVisibleChar(const C c)noexcept { return c >= 0x21 && c <= 0x7E; }
template <classIterator> Iterator skipWhiteSpaces(const Iterator begin, const Iterator end) { auto i = begin; for (i = begin; i != end; ++i) if (!isWhiteSpaceChar(*i)) break;
// RFC 5234, Appendix B.1. Core Rules template <typename T, typename C, typename std::enable_if<std::is_unsigned<T>::value>::type* = nullptr> constexpr T hexDigitToUint(const C c) { // HEXDIG return (c >= 0x30 && c <= 0x39) ? static_cast<T>(c - 0x30) : // 0 - 9 (c >= 0x41 && c <= 0x46) ? static_cast<T>(c - 0x41) + T(10) : // A - Z (c >= 0x61 && c <= 0x66) ? static_cast<T>(c - 0x61) + T(10) : // a - z, some services send lower-case hex digits throw ResponseError{"Invalid hex digit"}; }
// RFC 3986, 3. Syntax Components template <classIterator> Uri parseUri(const Iterator begin, const Iterator end) { Uri result;
// RFC 3986, 3.1. Scheme auto i = begin; if (i == end || !isAlphaChar(*begin)) throw RequestError{"Invalid scheme"};
result.scheme.push_back(*i++);
for (; i != end && (isAlphaChar(*i) || isDigitChar(*i) || *i == '+' || *i == '-' || *i == '.'); ++i) result.scheme.push_back(*i);
if (i == end || *i++ != ':') throw RequestError{"Invalid scheme"}; if (i == end || *i++ != '/') throw RequestError{"Invalid scheme"}; if (i == end || *i++ != '/') throw RequestError{"Invalid scheme"};
if (i == end || *i++ != 'H') throw ResponseError{"Invalid HTTP version"}; if (i == end || *i++ != 'T') throw ResponseError{"Invalid HTTP version"}; if (i == end || *i++ != 'T') throw ResponseError{"Invalid HTTP version"}; if (i == end || *i++ != 'P') throw ResponseError{"Invalid HTTP version"}; if (i == end || *i++ != '/') throw ResponseError{"Invalid HTTP version"};
if (i == end) throw ResponseError{"Invalid HTTP version"};
// RFC 7230, 3.1.2. Status Line template <classIterator> std::pair<Iterator, std::uint16_t> parseStatusCode(const Iterator begin, const Iterator end) { std::uint16_t result = 0;
auto i = begin; while (i != end && isDigitChar(*i)) result = static_cast<std::uint16_t>(result * 10U) + digitToUint<std::uint16_t>(*i++);
if (std::distance(begin, i) != 3) throw ResponseError{"Invalid status code"};
return {i, result}; }
// RFC 7230, 3.1.2. Status Line template <classIterator> std::pair<Iterator, std::string> parseReasonPhrase(const Iterator begin, const Iterator end) { std::string result;
auto i = begin; for (; i != end && (isWhiteSpaceChar(*i) || isVisibleChar(*i) || isObsoleteTextChar(*i)); ++i) result.push_back(static_cast<char>(*i));
return {i, std::move(result)}; }
// RFC 7230, 3.2.6. Field Value Components template <classIterator> std::pair<Iterator, std::string> parseToken(const Iterator begin, const Iterator end) { std::string result;
auto i = begin; for (; i != end && isTokenChar(*i); ++i) result.push_back(static_cast<char>(*i));
if (result.empty()) throw ResponseError{"Invalid token"};
auto i = begin; for (; i != end && (isWhiteSpaceChar(*i) || isVisibleChar(*i) || isObsoleteTextChar(*i)); ++i) result.push_back(static_cast<char>(*i));
// trim white spaces result.erase(std::find_if(result.rbegin(), result.rend(), [](constchar c) noexcept { return !isWhiteSpaceChar(c); }).base(), result.end());
for (;;) { constauto fieldValueResult = parseFieldValue(i, end); i = fieldValueResult.first; result += fieldValueResult.second;
// Handle obsolete fold as per RFC 7230, 3.2.4. Field Parsing // Obsolete folding is known as linear white space (LWS) in RFC 2616, 2.2 Basic Rules auto obsoleteFoldIterator = i; if (obsoleteFoldIterator == end || *obsoleteFoldIterator++ != '\r') break;
if (obsoleteFoldIterator == end || *obsoleteFoldIterator++ != '\n') break;
if (obsoleteFoldIterator == end || !isWhiteSpaceChar(*obsoleteFoldIterator++)) break;
result.push_back(' '); i = obsoleteFoldIterator; }
return {i, std::move(result)}; }
// RFC 7230, 3.2. Header Fields template <classIterator> std::pair<Iterator, HeaderField> parseHeaderField(const Iterator begin, const Iterator end) { auto tokenResult = parseToken(begin, end); auto i = tokenResult.first; auto fieldName = std::move(tokenResult.second);
if (i == end || *i++ != ':') throw ResponseError{"Invalid header"};
i = skipWhiteSpaces(i, end);
auto valueResult = parseFieldContent(i, end); i = valueResult.first; auto fieldValue = std::move(valueResult.second);
if (i == end || *i++ != '\r') throw ResponseError{"Invalid header"};
if (i == end || *i++ != '\n') throw ResponseError{"Invalid header"};
// RFC 7230, 4.1. Chunked Transfer Coding template <typename T, classIterator, typename std::enable_if<std::is_unsigned<T>::value>::type* = nullptr> T stringToUint(const Iterator begin, const Iterator end) { T result = 0; for (auto i = begin; i != end; ++i) result = T(10U) * result + digitToUint<T>(*i);
return result; }
template <typename T, classIterator, typename std::enable_if<std::is_unsigned<T>::value>::type* = nullptr> T hexStringToUint(const Iterator begin, const Iterator end) { T result = 0; for (auto i = begin; i != end; ++i) result = T(16U) * result + hexDigitToUint<T>(*i);
// RFC 7230, 3.2. Header Fields inline std::string encodeHeaderFields(const HeaderFields& headerFields) { std::string result; for (constauto& headerField : headerFields) { if (headerField.first.empty()) throw RequestError{"Invalid header field name"};
for (constauto c : headerField.first) if (!isTokenChar(c)) throw RequestError{"Invalid header field name"};
for (constauto c : headerField.second) if (!isWhiteSpaceChar(c) && !isVisibleChar(c) && !isObsoleteTextChar(c)) throw RequestError{"Invalid header field value"};
constchar* port = uri.port.empty() ? "80" : uri.port.c_str();
addrinfo* info; if (getaddrinfo(uri.host.c_str(), port, &hints, &info) != 0) throw std::system_error{getLastError(), std::system_category(), "Failed to get address info of " + uri.host};
// take the first address from the list socket.connect(addressInfo->ai_addr, static_cast<socklen_t>(addressInfo->ai_addrlen), (timeout.count() >= 0) ? getRemainingMilliseconds(stopTime) : -1);
auto remaining = requestData.size(); auto sendData = requestData.data();
if (!parsingBody) { // RFC 7230, 3. Message Format // Empty line indicates the end of the header section (RFC 7230, 2.1. Client/Server Messaging) constauto endIterator = std::search(responseData.cbegin(), responseData.cend(), headerEnd.cbegin(), headerEnd.cend()); if (endIterator == responseData.cend()) break; // two consecutive CRLFs not found
dest - pointer to the object to copy to src - pointer to the object to copy from c - terminating character, converted to unsignedchar at first count - number of characters to copy
这里容易出现理解偏差的是参数 c,“terminating character, converted to unsigned char at first” 也就是参数会转化为unsigned char 也就是需要传入的是单个字符,当检测到传入的src 中字符与”c”匹配时,停止copy,退出.
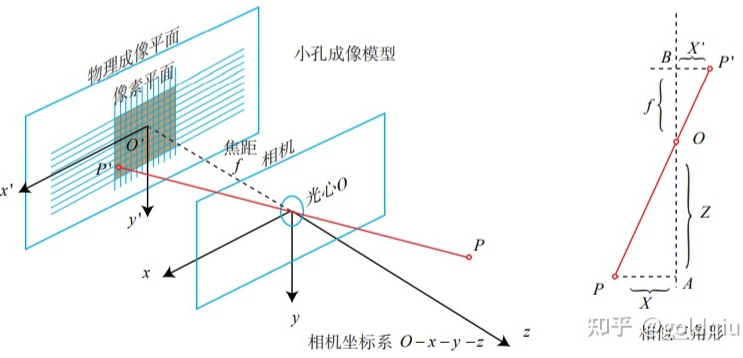
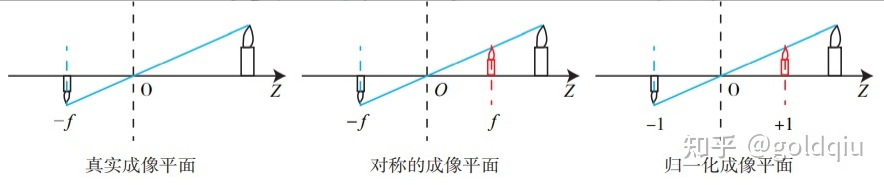
初中物理的蜡烛投影实验:在一个暗箱的前方放着一支点燃的蜡烛,蜡烛的光透过暗箱上的一个小孔投影在暗箱的后方平面上,并在这个平面上形成一个倒立的蜡烛图像。小孔模型能够把三维世界中的蜡烛投影到一个二维成像平面。同理,可以用这个简单的模型来解释相机的成像过程。对这个简单的针孔模型进行几何建模。设 O − x − y − z 为相机坐标系,z 轴指向相机前方,x 向右,y 向下。O为摄像机的光心,也是针孔模型中的针孔。现实世界的空间点P,经过小孔O投影之后,落在物理成像平面 O′ − x′ − y′ 上,成像点为 P′。设 P 的坐标为 [X,Y,Z]T,P′ 为 [X′,Y′,Z′]T,设物理成像平面到小孔的距离为f(焦距)。那么,根据三角形相似关系,有:
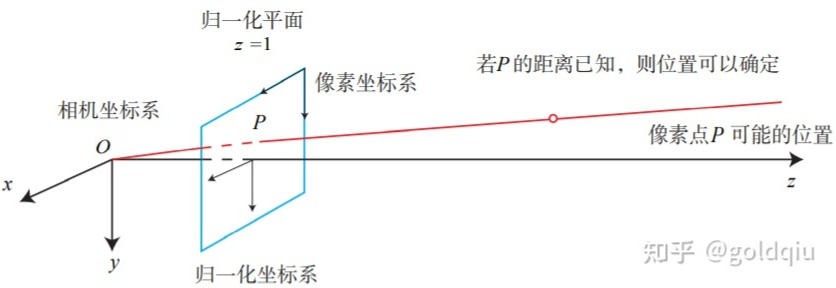
这描述了点 P和它的像之间的空间关系。不过,在相机中最终获得的是一个个的像素,这还需要在成像平面上对像进行采样和量化。为了描述传感器将感受到的光线转换成图像像素的过程,设在物理成像平面上固定着一个像素平面 o − u − v,在像素平面有P′的像素坐标:[u,v]T。
像素坐标系通常的定义方式是:原点o′位于图像的左上角,u 轴向右与 x 轴平行,v 轴向下与 y 轴平行。像素坐标系与成像平面之间,相差了一个缩放和一个原点的平移。设像素坐标在 u 轴上缩放了 α 倍,在 v 上缩放了 β 倍。同时,原点平移了 [cx,cy]T。那么,P′ 的坐标与像素坐标[u,v]T 的关系为:
(单目棋盘格张正友标定法[25]Z. Zhang, “Flexible camera calibration by viewing a plane from unknown orientations,” in Computer Vision, 1999. The Proceedings of the Seventh IEEE International Conference on, vol. 1, pp. 666–673, Ieee, 1999.)
后一个式子隐含了一次齐次坐标到非齐次坐标的转换。它描述了P的世界坐标到像素坐标的投影关系。相机的位姿R,t称为相机的外参数(Camera Extrinsics) 。 相比于不变的内参,外参会随着相机运动发生改变,同时也是 SLAM 中待估计的目标,代表着机器人的轨迹。 式子表明,可以把一个世界坐标点先转换到相机坐标系,再除掉它最后一维(Z)的数值(即该点距离相机成像平面的深度),这相当于把最后一维进行归一化处理,得到点 P 在相机归一化平面上的投影:
归一化坐标可看成相机前方z=1处的平面上的一个点,这个 z = 1 平面也称为归一化平面。归一化坐标再左乘内参就得到了像素坐标,所以可以把像素坐标 [u,v]T 看成对归一化平面上的点进行量化测量的结果。从这个模型中可以看出,对相机坐标同时乘以任意非零常数,归一化坐标都是一样的,这说明点的深度在投影过程中被丢失了,所以单目视觉中没法得到像素点的深度值。
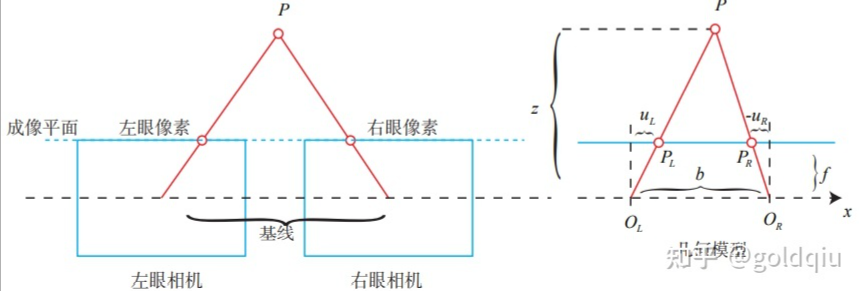
双目相机一般由左眼相机和右眼相机两个水平放置的相机组成。在左右双目相机中,我们可以把两个相机都看作针孔相机。它们是水平放置的,意味着两个相机的光圈中心都位于 x 轴上。两者之间的距离称为双目相机的基线(Baseline,记作 b),是双目相机的重要参数。
考虑一个空间点 P,它在左眼相机和右眼相机各成一像,记作 PL,PR。由于相机基线的存在,这两个成像位置是不同的。理想情况下,由于左右相机只在 x 轴上有位移,因此 P 的像也只在 x 轴(对应图像的u轴)上有差异。记它的左侧坐标为 uL,右侧坐标为 uR,几何关系如图所示。
根据 △PPLPR 和 △POLOR 的相似关系,整理得:
双目相机的成像模型:OL,OR 为左右光圈中心,方框为成像平面,f 为焦距。uL 和 uR 为成像平面的坐标。注意,按照图中坐标定义,uR 应该是负数,所以图中标出的距离为 −uR。
其中 d 定义为左右图的横坐标之差,称为视差(Disparity)。根据视差,我们可以估计一个像素与相机之间的距离。视差与距离成反比:视差越大,距离越近。同时,由于视差最小为一个像素,于是双目的深度存在一个理论上的最大值,由 fb 确定。可以看到,当基线越长时,双目能测到的最大距离就会越远。类似人眼在看非常远的物体时(如很远的飞机),通常不能准确判断它的距离。
视差 d 的计算比较困难,需要确切地知道左眼图像某个像素出现在右眼图像的哪一个位置(即对应关系)。当想计算每个像素的深度时,其计算量与精度都将成为问题,而且只有在图像纹理变化丰富的地方才能计算视差。由于计算量的原因,双目深度估计仍需要使用 GPU 或FPGA 来实时计算。
例程中调用了OpenCV实现的SGBM算法(Semi-global Batch Matching)[26] H. Hirschmuller, “Stereo processing by semiglobal matching and mutual information,” IEEE Transactions on pattern analysis and machine intelligence, vol. 30, no. 2, pp. 328–341, 2008.
[27] D. Scharstein and R. Szeliski, “A taxonomy and evaluation of dense two-frame stereo correspondence algorithms,” International journal of computer vision, vol. 47, no. 1-3, pp. 7–42, 2002.
[28] S. M. Seitz, B. Curless, J. Diebel, D. Scharstein, and R. Szeliski, “A comparison and evaluation of multi-view stereo reconstruction algorithms,” in null, pp. 519–528, IEEE, 2006.