Ubuntu启动时间转时间戳
1 | root@ubuntu:/home/user# cat ../../tools_data.sh |
dmesg
1 | dmesg |
常用日志目录代表的意思
1 | => /var/log/messages:常规日志消息 |
1 | root@ubuntu:/home/user# cat ../../tools_data.sh |
1 | dmesg |
1 | => /var/log/messages:常规日志消息 |
[TOC]
| OpenSpiel | 框架 | DeepMind | |
| SpriteWorld & Bsuite | 框架 | DeepMind | |
| Acme | 分布式强化学习算法框架 | DeepMind | |
| PPO | facebook-OpenAI | ||
| gym | 框架工具包 | facebook-OpenAI | |
| Baselines | 框架,Demo | facebook-OpenAI |
RLCard
Atari
| Value-Base | Policy Gradient | AC | ||
|---|---|---|---|---|
| TD3 | ||||
| DQN | Y | |||
| AC | ||||
| A2C | Y | |||
| A3C | Y | |||
| REINFORCE | Y | |||
| DDPG | Y | Y | ||
| TRPG | Y | |||
| PPO | on-policy | Y | ||
| SAC | off-policy | |||
| IMPALA | Y |
Advance函数是什么?为什么这样设计?
PPO算法的改进点有几个?
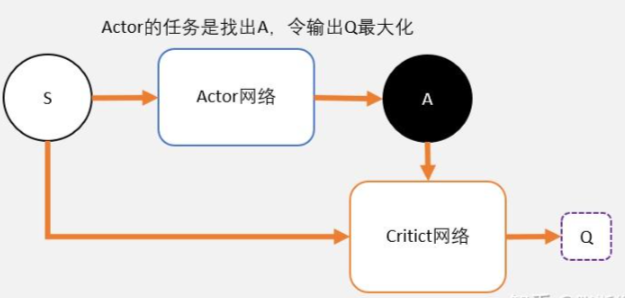
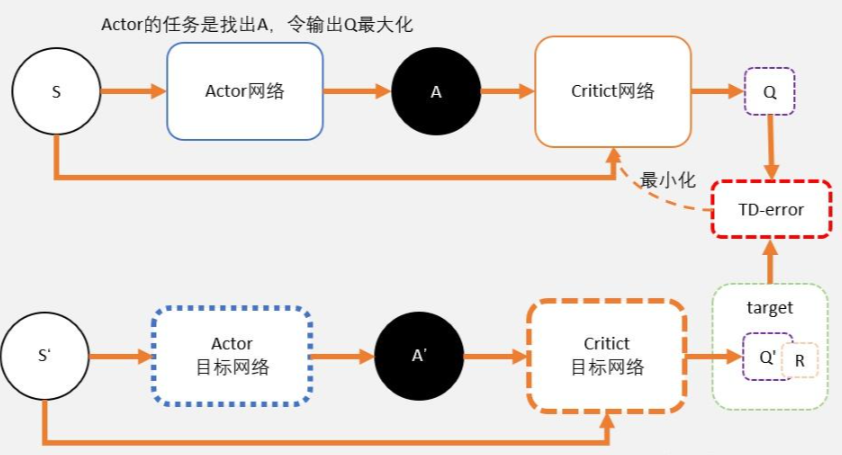
两个神经网络,一个延迟更新权重,一个实时训练中进行参数更新。
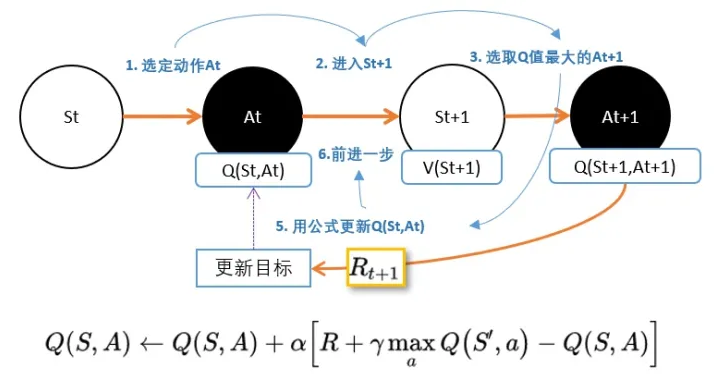
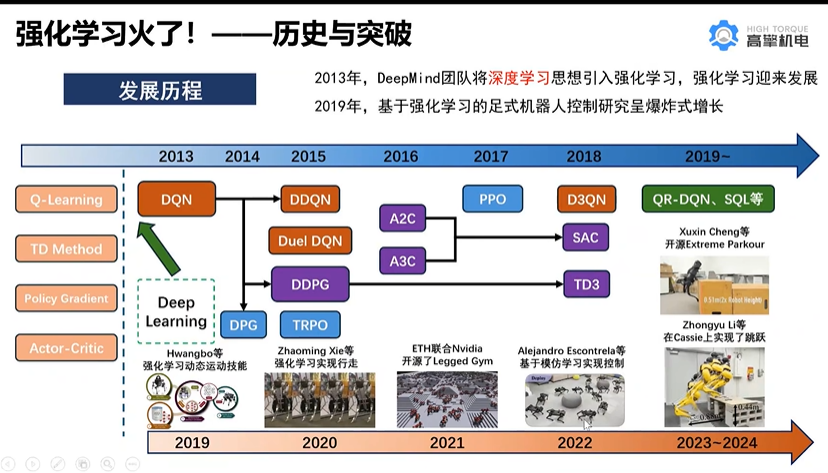
我们从公式中也能看出,DQN不能用于连续控制问题原因,是因为maxQ(s’,a’)函数只能处理离散型的。那怎么办?
我们知道DQN用magic函数,也就是神经网络解决了Qlearning不能解决的连续状态空间问题。那我们同样的DDPG就是用magic解决DQN不能解决的连续控制型问题就好了。
也就是说,用一个magic函数,直接替代maxQ(s’,a’)的功能。也就是说,我们期待我们输入状态s,magic函数返回我们动作action的取值,这个取值能够让q值最大。这个就是DDPG中的Actor的功能。
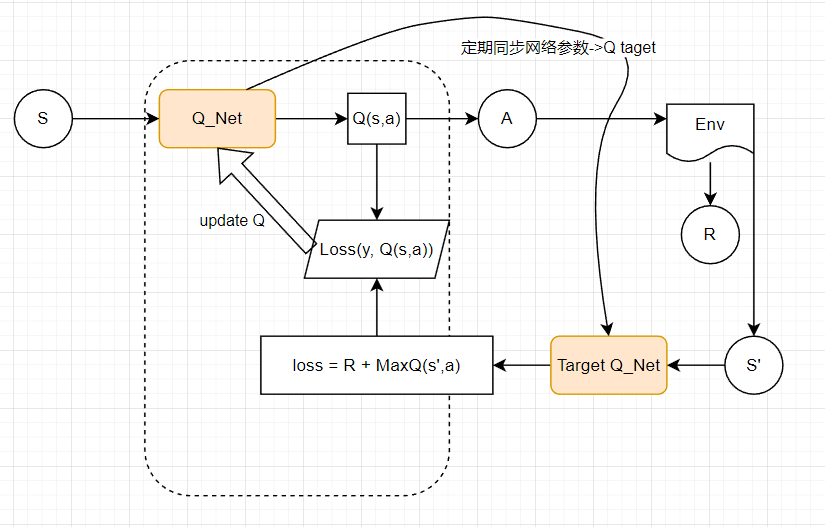
# DQN(Double/ Duel/ D3DQN)bilibili
深度 Q 网络(deep Q network,DQN)原理&实现 - 缙云山车神 - 博客园
1 | fc1 = relu(fc(X)) |
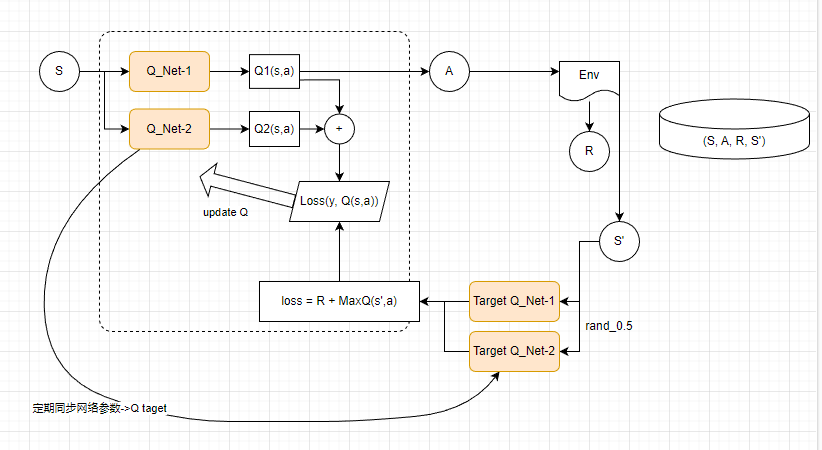
Q学习是基于贪心策略的,这会导致最大化偏差问题,和双Q学习思想一致。下面是双Q学习的伪代码,可以借鉴一下。
对偶网络(duel network)
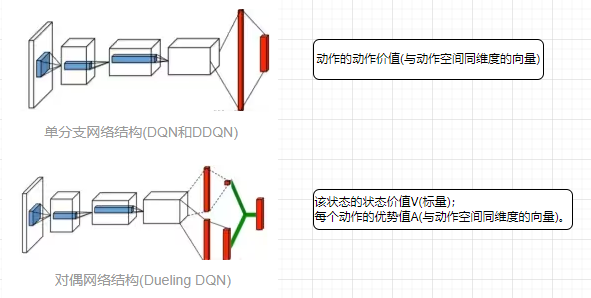
D3QN(Dueling Double Deep Q Network)
/todo
集合了在此之前的六大卓有成效的DQN变体,将其训练技巧有机的组合到一起
有两个缺陷:方差大,离线学习
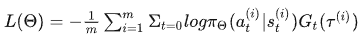
# 强化学习从零到RLHF(五)Actor-Critic,A2C,A3C zhihu
# 强化学习基础 Ⅷ: Vanilla Policy Gradient 策略梯度原理与实战 zhihu
# 如何理解策略梯度(Policy Gradient)算法?(附代码及代码解释)zhihu

(解决高方差问题)
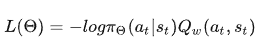 策略梯度的Gt(轨迹t时刻的实际后续累计回报,变成了t时刻采取动作a的期望后续累计回报)=等效于Qt(a,s) ; Q指动作值函数;
策略梯度的Gt(轨迹t时刻的实际后续累计回报,变成了t时刻采取动作a的期望后续累计回报)=等效于Qt(a,s) ; Q指动作值函数;
需要维护两套可训练参数 $\theta$ 、$w$ :
actor,$\theta$ 控制策略
Critic, w评估动作,输出Q value 用于策略梯度的计算。

# 理解Actor-Critic的关键是什么?(附代码及代码分析) 知乎
我们也可以使用优势函数作为Critic来进一步稳定学习,实际上A2C才是Actor-Critic 架构更多被使用的做法。
这个想法是,优势函数计算一个操作与某个状态下可能的其他操作相比的相对优势:与状态的平均值相比,在某个状态执行该操作如何更好。它从状态-动作对中减去状态的期望值。
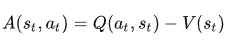
换句话说,此函数计算我们在该状态下执行此操作时获得的额外奖励,与在该状态获得的期望奖励相比。
额外的奖励是超出该状态的预期值。
我们的actor损失函数为 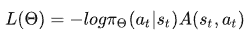

A3C全称为Asynchronous advantage actor-critic。
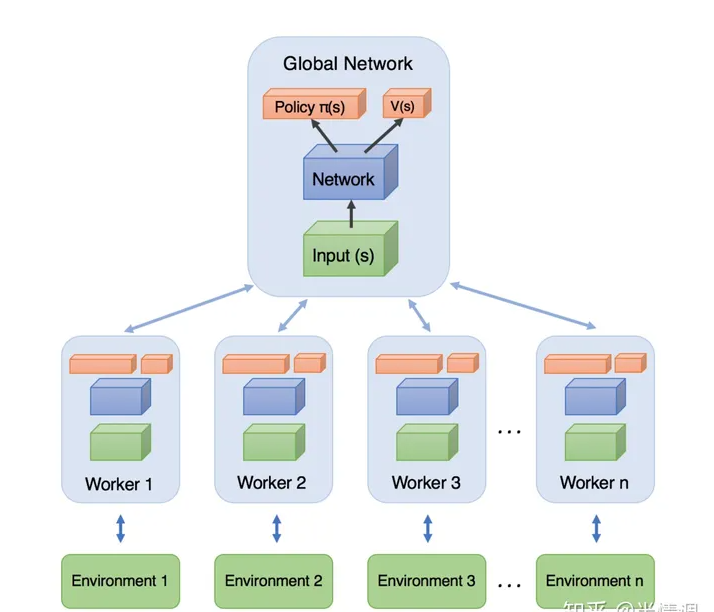
前文讲到,神经网络训练时,需要的数据是独立同分布的,为了打破数据之间的相关性,DQN等方法都采用了经验回放的技巧。然而经验回放需要大量的内存,打破数据的相关性,经验回放并非是唯一的方法。另外一种是异步的方法,所谓异步的方法是指数据并非同时产生,A3C的方法便是其中表现非常优异的异步强化学习算法。
A3C模型如下图所示,每个Worker直接从Global Network中拿参数,自己与环境互动输出行为。利用每个Worker的梯度,对Global Network的参数进行更新。每一个Worker都是一个A2C。
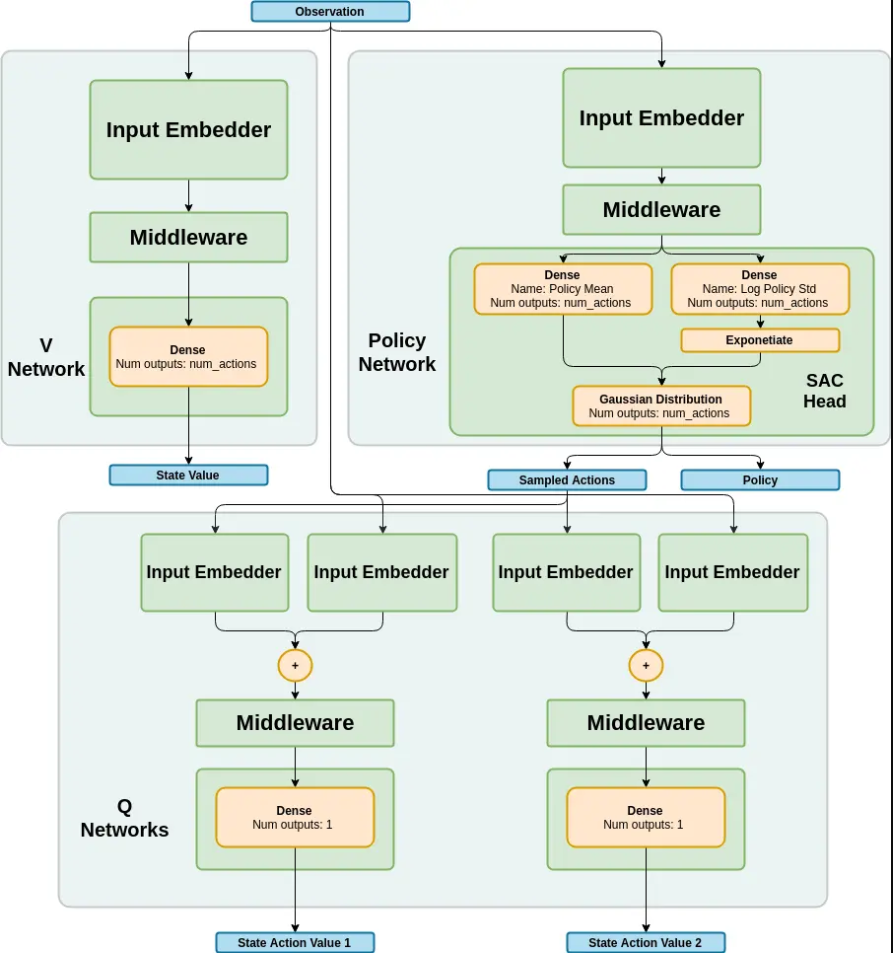
SAC即Soft Actor-Critic(柔性致动/评价),它是一种基于off-policy和最大熵的深度强化学习算法,其由伯克利和谷歌大脑的研究人员提出。
SAC算法是强化学习中的一种off-policy算法,全称为Soft Actor-Critic,它属于最大熵强化学习范畴。
SAC算法的网络结构类似于TD3算法,都有一个Actor网络和两个Critic网络,但SAC算法的目标网络只有两个Critic网络,没有Actor网络。
SAC算法解决的问题是离散动作空间和连续动作空间的强化学习问题,它学习一个随机性策略,在不少标准环境中取得了领先的成绩,是一个非常高效的算法。
在SAC算法中,每次用Critic网络时会挑选一个值小的网络,从而缓解值过高估计的问题,进而提高算法的稳定性和收敛速度。
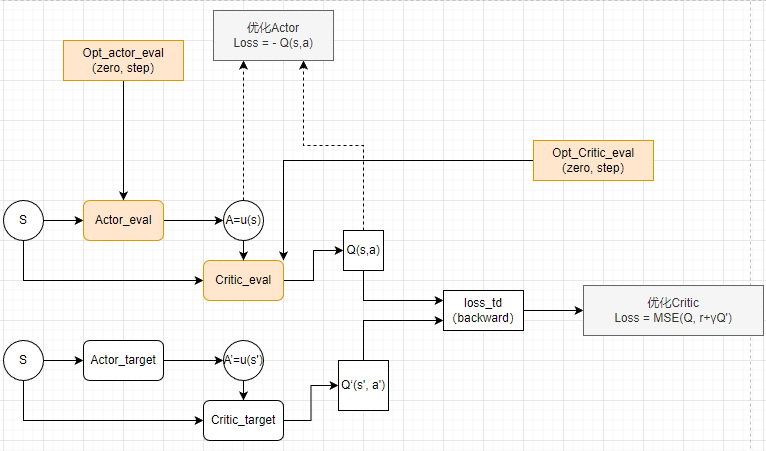
deep deterministic policy gradient,深度确定性策略梯度算法。
Deep Deterministic Policy Gradient (DDPG) | 莫烦Python
Pytorch实现DDPG算法_ddpg pytorch-CSDN博客
TD3算法主要解决了DDPG算法的高估问题。在DDPG算法的基础上,TD3算法提出了三个关键技术:
TD3算法在许多连续控制任务上都取得了不错的表现。
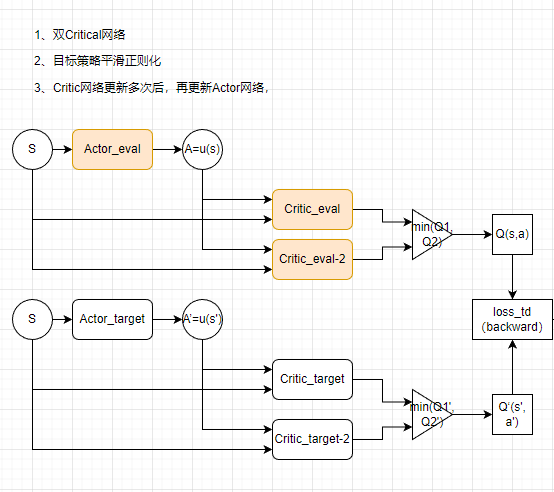
TD3算法(Twin Delayed Deep Deterministic policy gradient)-CSDN博客
TRPO优化效率上一个改进,其通过修改TRPO算法,使其可以使用SGD算法来做置信域更新,并且用clipping的方法方法来限制策略的过大更新,保证优化在置信域中进行。
PPO 算法利用新策略和旧策略的比例,从而限制了新策略的更新幅度。
PPO-Max
https://blog.csdn.net/jinzhuojun/article/details/80417179
PPO算法是一种用于强化学习的策略优化算法,全称为Proximal Policy Optimization。
PPO算法基于策略梯度方法,通过约束优化的方式来保证每次迭代的更新幅度不会过大,从而提高算法的稳定性和收敛速度。
PPO算法通过两个不同的目标函数来更新策略函数,分别是Clipped Surrogate Objective和Trust Region Policy Optimization。其中,PPO-Penalty类似于TRPO算法,将KL散度作为目标函数的一个惩罚项,并自动调整惩罚系数,使其适应数据的规模;而PPO-Clip则没有KL散度项,也没有约束条件,使用一种特殊的裁剪技术,在目标函数中消除了新策略远离旧策略的动机。
PPO算法还使用了Generalized Advantage Estimation(GAE)的技术来估计策略函数的价值函数,从而提高了算法的性能和收敛速度。
PPO算法的应用范围非常广泛,可以用于各种强化学习任务,如机器人控制、游戏玩法、自然语言处理等方面。在OpenAl的研究中,PPO算法被用于训练人工智能玩Atari游戏,以及AlphaGo Zero等强化学习任务中,取得了优秀的表现。
总的来说,PPO算法是一种稳定、高效的强化学习算法,具有广泛的应用价值。
PPO算法实现gym连续动作空间任务Pendulum(pytorch)
Python强化练习之PyTorch opp算法实现月球登陆器(得分观察)
影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现
【深度强化学习】(6) PPO 模型解析,附Pytorch完整代码[【运行过】
Coding PPO from Scratch with PyTorch (Part 1/4)[专业详细]
深度增强学习PPO(Proximal Policy Optimization)算法源码走读_ppo算法-CSDN博客
强化学习(9):TRPO、PPO以及DPPO算法-CSDN博客
组成Rainbow的这六大变体如下:
soft actor-critic
在经典的强化学习中,智能体通过与环境交互和最大化reward期望来学习策略。
在模仿学习中没有显式的reward,因而只能从专家示例中学习。
**GAIL的核心思想:**策略生成器G和判别器D的一代代博弈
策略生成器:策略网络,以state为输入,以action为输出
判别器:二分类网络,将策略网络生成的 (s, a) pair对为负样本,专家的(s,a)为正样本
learn 判别器D:
给定G,在与环境交互中通过G生成完整或不完整的episode(但过程中G要保持不变)作为负样本,专家样本作为正样本来训练D
learn 生成器G:
给定D,通过常规的强化学习算法(如PPO)来学习策略网络,其中reward通过D得出,即该样本与专家样本的相似程度
G和D的训练过程交替进行,这个对抗的过程使得G生成的策略在与环境的交互中得到的reward越来越大,D“打假”的能力也越来越强。
Learning Robust Rewards with Adversarial Inverse Reinforcement learning
| info | ||
|---|---|---|
| DouZero | ||
| DanZero | Distribute Q-learning | |
| MuZero |
启发式搜索(MCTS)+强化学习+自博弈的方法,
Muzero的贡献在AlphaZero强大的搜索和策略迭代算法的基础上加入了模型学习的过程,使其能够在不了解状态转移规则的情况下,达到了当时的SOTA效果。
Muzero的模型有三部分:
representation:表征编码,使用历史观测序列编码为隐空间的
dynamics:动态模型,这个就是MBRL经典的Dynamic Model
prediction:值模型。输入输出策略和价值函数
接下来是NIPS2021的EfficientZero,这篇文章强调的是sample-efficiency,使用limited data,在仅有两小时实时游戏经验的情况下,在Atari 100K基准上实现了190.4%的平均人类性能和116%的中位数人类性能,并且在DMC Control 100K基准超过了state SAC(oracle),性能接近2亿帧的DQN,而消耗的数据少500倍。
EfficientZero基于MuZero,做了如下三点改进:
(1)使用自监督的方式来学习temporally consistent environment model
(2)端到端的学习value prefix,预测时间段内奖励值之和,降低预测reward不准导致的误差
(3)改变Multi-step reward的算法,使用一个自适应的展开长度来纠正off-policy target
https://blog.csdn.net/weixin_31351409/article/details/101189820
https://github.com/deepmind/spriteworld
https://github.com/deepmind/bsuite
https://www.sohu.com/a/400058213_473283
https://github.com/deepmind/acme
https://arxiv.org/pdf/2006.00979v1.pdf
https://www.deepmind.com/research?tag=Reinforcement+learning
https://zhuanlan.zhihu.com/p/80526746
极小化极大(Alpha-beta剪枝)搜索、蒙特卡洛树搜索、序列形式线性规划、虚拟遗憾最小化(CFR)、Exploitability
外部抽样蒙特卡洛CFR、结果抽样蒙特卡洛CFR、Q-learning、价值迭代、优势动作评论算法(Advantage Actor Critic,A2C)、Deep Q-networks (DQN)
短期价值调整(EVA)、Deep CFR、Exploitability 下降(ED) 、(扩展形式)虚拟博弈(XFP)、神经虚拟自博弈(NFSP)、Neural Replicator Dynamics(NeuRD)
遗憾策略梯度(RPG, RMPG)、策略空间回应oracle(PSRO)、基于Q的所有行动策略梯度(QPG)、回归CFR (RCFR)、PSROrN、α-Rank、复制/演化动力学。
https://blog.csdn.net/kittyzc/article/details/83006403
https://github.com/openai/baselines
spinning up是一个深度强化学习的很好的资源
https://spinningup.openai.com/en/latest/
根据官方文档,spinning up实现的算法包括:
Vanilla Policy Gradient (VPG)
Trust Region Policy Optimization (TRPO)
Proximal Policy Optimization (PPO)
Deep Deterministic Policy Gradient (DDPG)
Twin Delayed DDPG (TD3)
Soft Actor-Critic (SAC)
**张伟楠:**我在上海交通大学给致远学院ACM班和电院AI试点班的同学讲授强化学习,由于学生的专业和本课程内容很贴合,因此学生对强化学习的原理部分关注较多。在夏令营中获得学生的反馈更多来自如何在各种各样的领域用好强化学习技术,当然也有不少本专业的学生对强化学习本身的研究十分了解。对于来我们APEX实验室的强化学习初学者,我建议的学习路线是:
\1. 先学习UCL David Silver的强化学习课程:https://www.davidsilver.uk/teaching/
这是强化学习的基础知识,不太包含深度强化学习的部分,但对后续深入理解深度强化学习十分重要。
\2. 然后学习UC Berkeley的深度强化学习课程:http://rail.eecs.berkeley.edu/deeprlcourse/
\3. 最后可以可以挑着看OpenAI 的夏令营内容:https://sites.google.com/view/deep-rl-bootcamp/lectures
当然,如果希望学习中文的课程,我推荐的是:
\1. 我本人在上海交通大学的强化学习课程: https://www.boyuai.com/rl
\2. 周博磊老师的强化学习课程:https://www.bilibili.com/video/BV1LE411G7Xj
深度强化学习系列(15): TRPO算法原理及Tensorflow实现-CSDN博客
Pytorch实现强化学习DQN玩迷宫游戏(莫凡强化学习DQN章节pytorch版本)_莫烦迷宫 强化学习 pytorch实现-CSDN博客
(七月在线2019)无人驾驶系列知识入门到提高 QQ89425879
(七月在线)无人驾驶感知融合实战
(东南大学)智能汽车技术
(北理工) 无人驾驶车辆
从落地的角度来看,感知的一些功能会逐渐硬件化;
从技术演进的角度,感知的工作重点会突出三个方面:
作者:张小牙
链接:https://www.zhihu.com/question/486962254/answer/2142322427

内容

MIT提出BEVFusion:具有统一鸟瞰图表示的多任务多传感器融合 - CVer计算机视觉的文章 - 知乎 https://zhuanlan.zhihu.com/p/521402618
https://games-cn.org/gamescoursescollection/
Games 101 现代计算机图形学入门 闫令琪 加州大学芭芭拉分校
Games 102 几何建模与处理技术 刘利刚 中国科学技术大学
Games 103 基于物理的计算机动画入门 王华民 凌迪科技(Style3D)
Games 104 现代游戏引擎:从入门到实战 王希 不鸣科技
Games 201 高级物理引擎实战指南 胡渊鸣 麻省理工学院
Games 202 高质量实时渲染 闫令琪 加州大学芭芭拉分校
Games 203 三维重建和理解 黄其兴 德州大学奥斯丁分校
Games 204 计算成像 孙启林 香港中文大学(深圳)
Games 301 曲面参数化 刘利刚等 中国科学技术大学
Games 401 泛动引擎(PeriDyno)物理仿真编程与实践 何小伟&蔡勇 中科院
何小伟:中科院软件研究所副研究员;参与GPU/CPU混合架构的开源物理仿真引擎PhysIKA,同时面向实时智能与物理仿真构建开源系统PeriDyno
蔡勇:湖南大学副教授,高性能工程软件设计与研发
本课程将全面而系统地介绍现代计算机图形学的四大组成部分:(1)光栅化成像,(2)几何表示,(3)光的传播理论,以及(4)动画与模拟。每个方面都会从基础原理出发讲解到实际应用,并介绍前沿的理论研究。
变换
光栅化
着色
几何
光线追踪
动画与模拟
现代计算机图形学入门 闫令琪 加州大学芭芭拉分校
视频:bilibili
本课程将全面而系统地介绍现代计算机图形学的四大组成部分:(1)光栅化成像,(2)几何表示,(3)光的传播理论,以及(4)动画与模拟。每个方面都会从基础原理出发讲解到实际应用,并介绍前沿的理论研究。
变换(二维与三维,模型,视图,投影)
光栅化(三角形离散化,抗锯齿)
着色(光照,着色模型,频率,图形管线,纹理映射,插值,高级纹理映射)
几何(表示,曲线,曲面,网格处理,阴影图)
光线追踪(原理,加速结构,蒙特卡洛积分,路径追踪)
动画与模拟
图形理论体系+可编程渲染管线+图形编程技能(C++,OpenGL,GLSL)(在图形编程尤其是着色器编程方面与Unity相通)
第一,管线视角的图形学,按照图形渲染管线的三个概念阶段,即应用程序阶段、几何阶段、光栅化阶段来组织课程内容,将整个课程内容划分为五篇:基础篇、应用程序、几何阶段、光栅化阶段、高级话题。

第二,构建完整的理论体系,将传统理论和图形新发展结合起来,既包括朴素的软光栅、经典的造型技术,也包括真实感图形学的光照、纹理、阴影等内容,在这些内容中不仅体现经典的算法,还包括一些新的算法如实时光线追踪、法线贴图、实时动态阴影等。

第三,搭建先进实用的编程框架,基于可编程管线进行图形编程,采用主流的图形标准OpenGL,并用采用其着色器语言OpenGL Shading Language(简称GLSL)进行着色器的编写(Shader的编写思想与Unity3D相通)。这个图形编程框架充分利用了日趋强大的GPU的计算能力,和目前工业界的实际做法完全相通。设置了从在一个窗口中绘制多边形到粒子系统、延迟渲染的多个进阶实验,逐步提高学生的图形编程能力。
实验将提供配套代码的下载链接。
https://github.com/wanlin405/Computer-Graphics
为了使对计算机图形学感兴趣的同学们拥有更好的学习体验,本次我们的计算机图形学课程将添加了光栅渲染器何PBR渲染器的演示。
视频:bilibili up: 啥都会一点的研究生
知乎:王博Kings
无人驾驶系列知识入门到提高
[TOC]
跳转【】

http://wiki.ros.org/cn/Installation/Ubuntu
1 | 1 sudo apt-key adv --keyserver 'hkp://keyserver.ubuntu.com:80' --recv-key C1CF6E31E6BADE8868B172B4F42ED6FBAB17C654 |
Clion(收费)
snap install clion –classic
VSCode
1 | mkdir –p ~/catkin_ws/src/ |
1 | ----------------julay_say |
IDE Procject Cmakelist.txt
1 | find |
/home/simon/catkin_ws/src/julay_say/src/julay_say_node.cpp
1 |
|
/home/simon/catkin_ws/src/julay_listen/src/julay_listen_node.cpp
1 |
|
1 | catkin_create_pkg julay_msgs std_msgs roscpp |
catkin_ws/src/julay_msgs/msg/JulyMsg.msg
1 | string detail |
1 | find_package(catkin REQUIRED COMPONENTS |
1 | <build_depend>message_generation</build_depend> |
1 |
|
1 | find_package(catkin REQUIRED COMPONENTS |
1 | <build_depend>julay_msgs</build_depend> |
1 | roscore |
todo
王博Kings:无人驾驶系列知识入门到提高4–动态环境感知与2D检测
王博Kings:无人驾驶系列知识入门到提高5–动态环境感知与3D检测
王博Kings:无人驾驶系列知识入门到提高6-动态环境感知与跟踪
王博Kings:无人驾驶系列知识入门到提高7-高精度地图 V2X HD MAP
[TOC]
1 |
|
1 |
|
1 |
|
https://cloud.tencent.com/developer/article/1583894
论文:
云文件:
笔记:
Ipad pen:
思维导图:
流程图:
扫描:
(前端)图片标注
vitural Network:
3D Render:
背单词:
everything
Shell / 文件传输:
对比工具:
编辑器
版本管理:
代码检查:
AI+
codegeex
codeFuse(阿里)
地图:
装修:
hexo(静态网页)
Typecho(中国团队开发的开源跨平台博客程序。它基于PHP5构建,并支持多种操作系统(Linux,Unix,BSD,Windows)、 服务器(Apache,Lighttpd,IIS,Nginx)和数据库(Mysql,PostgreSQL,SQLite)。)
Octopress(是一套使用 Ruby 语言开发的博客网站框架。)
Farbox
Wordpress
Ghost (基于 Node.js 语言和 MySql 数据库的个人博客系统)
博客主题:maupassant