[TOC]
相关书籍
| 入门 | C++ Primer Plus | |
| C++ Primer | ||
| 提高 | 深度探索C++对象模型 | |
| More Effective C++ 35 | ||
| Effective C++ 55 | ||
| Effective Modern C++ | ||
| 进阶篇 | STL 源码剖析 | |
| C++标准库 | ||
| GOF23 设计模式 C++ | ||
| C++并发编程实战 | ||
| C++性能优化指南 | ||
| 网络编程 | Linux多线程-服务端编程- 使用muduo c++ 网络库 |
|
| Unix网络编程 三件套 | ||
| TCP/UP协议 三卷 |
APIs
标准库
1.int/float to string/array:
C语言提供了几个标准库函数,可以将任意类型(整型、长整型、浮点型等)的数字转换为字符串,下面列举了各函数的方法及其说明。
● itoa():将整型值转换为字符串
● ltoa():将长整型值转换为字符串。
● ultoa():将无符号长整型值转换为字符串。
● gcvt():将浮点型数转换为字符串,取四舍五入。
● ecvt():将双精度浮点型值转换为字符串,转换结果中不包含十进制小数点。
● fcvt():指定位数为转换精度,其余同ecvt()。
除此外,还可以使用sprintf系列函数把数字转换成字符串,其比itoa()系列函数运行速度慢
2. string/array to int/float
C/C++语言提供了几个标准库函数,可以将字符串转换为任意类型(整型、长整型、浮点型等)。
● atof():将字符串转换为双精度浮点型值。
● atoi():将字符串转换为整型值。
● atol():将字符串转换为长整型值。
● strtod():将字符串转换为双精度浮点型值,并报告不能被转换的所有剩余数字。
● strtol():将字符串转换为长整值,并报告不能被转换的所有剩余数字。
● strtoul():将字符串转换为无符号长整型值,并报告不能被转换的所有剩余数字。
数据类型&变量&常量
int to string
1 | // 1. |
rand
1 |
|
修饰符
unsinge
存储类
auto
register
static 全局变量
extern 全局变量的引用
mutable
thread_local (C++11)
const (只读变量)
constptr (常量)
C++ 11标准中,为了解决 const 关键字的双重语义问题,保留了 const 表示“只读”的语义,而将“常量”的语义划分给了新添加的 constexpr 关键字。
从 C++ 17 开始,auto 关键字不再是 C++ 存储类说明符,且 register 关键字被弃用。
运算符 循环 判断
函数
1 | void func(Cobject* object); |
有什么区别呢?
void func(Cobject* object)
这种方式是将类指针作为参数,函数压入参数时实际上复制了指针的值(其实指针可以看作一个存放地址值的×××),实际复制的指针仍指向原对象的空间,所以func函数对该指针的操作是对原对象空间的操作。
void func(Cobject& object)
这种方式和传指针类似,但函数压入参数时实际上复制了object对象的this指针,其实this指针不是一个真正存在的指针,可以看作是每个对象的数据空间起始地址。func函数中对this指针的操作,实际上也是对原对象空间的操作。
void func(Cobject object)
这种函数是非常不建议的,因为函数参数压栈时,对object进行了复制(还记得拷贝构造函数吗),所以函数对object的操作实际上是对新的对象空间进行的操作,不会影响原对象空间。由于不必要的拷贝对象是十分浪费时间的,也没有意义,我们完全可以用下面函数代替
1
func(const Cobject& object);
这样也能保护对象的只读性质。
1 | 1、值传递 |
数字运算
cos, sin tan, log, pow,
hypot, sqrt, abs, fabs, floor
数组
1 | int *pia = new int[10]; // array of 10 uninitialized ints |
枚举enum
1 | // 定义格式:枚举类型的定义格式为: |
字符串String
1 | # |
string 赋值
1 | // 方法1 (ostringstream) |
string.substr(起点, length)
1 | // string对象.substr(起点 , 切片长度) |
string.erase()
1 | 1.erase(pos,n); |
string 对比
1 | std::string h2 = "BUS_0001"; |
string 高级
1 | ## 1. 逆序 |
指针
引用
memcpy…apis
memset(void *str, int c, size_t n)
复制字符 c(一个无符号字符)到参数 str 所指向的字符串的前 n 个字符。
memcpy(void *destin, void *source, unsigned n);
从存储区 source复制n 个字节到存储区 destin。
将地址从src开始的前count个字节的内容拷贝到地址从dst开始的内存空间中。
文件读取I/O
C++文件读写详解(ofstream,ifstream,fstream)
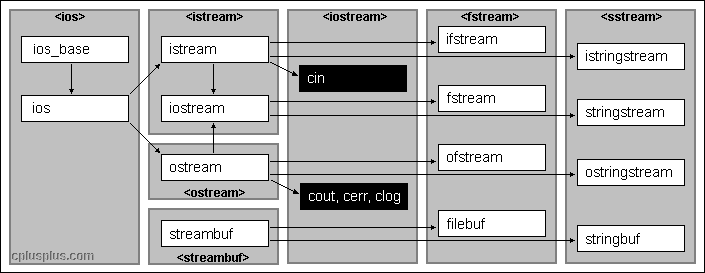
1、基于控制台io
1 | #include <iostream> |
2、基于文件IO [ifstream/ofstream]
1 |
|
ref:
https://www.toptip.ca/2012/11/is-it-necessary-to-manually-close.html
3、基于字符串IO [i/ostringstream]
1 |
|
ref:
c++的输入输出 [一](istream,ostream,iostream)
c++的输入输出 [二](ifstream,ofstream,fstream)
c++的输入输出 [三](istringstream,ostringstream,stringstream)
C++文件读写详解(ofstream,ifstream,fstream)
c++输入文件流ifstream用法详解_陈 洪 伟的博客-CSDN博客_ifstream用法
时间
1、时间戳毫秒/秒
gettimeofday()
1 | // linux |
chrono
1 |
|
Demo
1 |
|
掩耳盗铃
1 | time_t now = time(nullptr); |
2、时间戳(s)
1 | // time for int s |
1 | std::time_t t = std::time(NULL); |
3、localtime(time_t)
C 库函数 struct tm *localtime(const time_t *timer) 使用 timer 的值来填充 tm 结构。timer 的值被分解为 tm 结构,并用本地时区表示。
4、strftime()
size_t strftime(char *str, size_t count, const char *format, const struct tm *tm);
1 | str, 表示返回的时间字符串 |
基本的输入输出
数据结构
APIs C++ 11
auto
C++11这次的更新带来了令很多C++程序员期待已久的for range循环,每次看到javascript, lua里的for range,心想要是C++能有多好,心里别提多酸了。这次C++11不负众望,再也不用羡慕别家人的for range了。
字符串 & 数组
1 | std::string str = “hello, world”; |
1 | int arr[] = {1, 2, 3, 4}; |
stl 容器
1 | std::vector<std::string> str_vec = {“i”, “like”, "google”}; |
遍历stl map
1 | std::map<int, std::string> hash_map = {{1, “c++”}, {2, “java”}, {3, “python”}}; |
算法
迭代器
对象
对象创建
1 | //隐式创建 |
VS 快捷键
1 | 多行注释:Ctrl+K+C(先按ctrl,再按K,最后按C) |



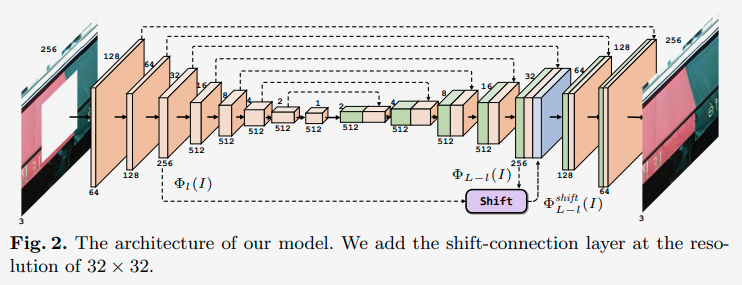
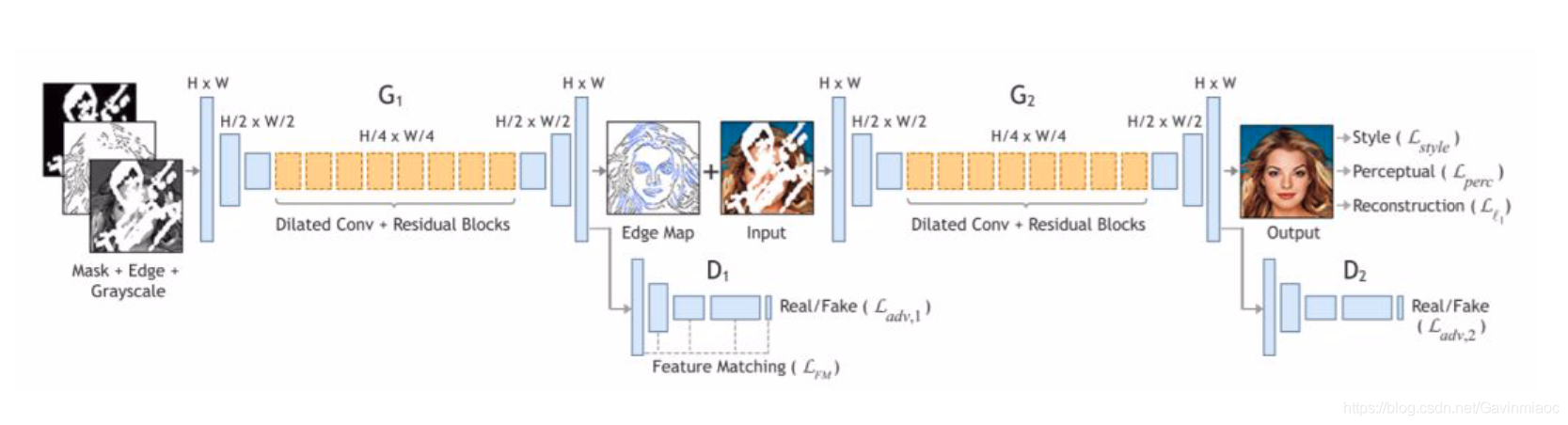

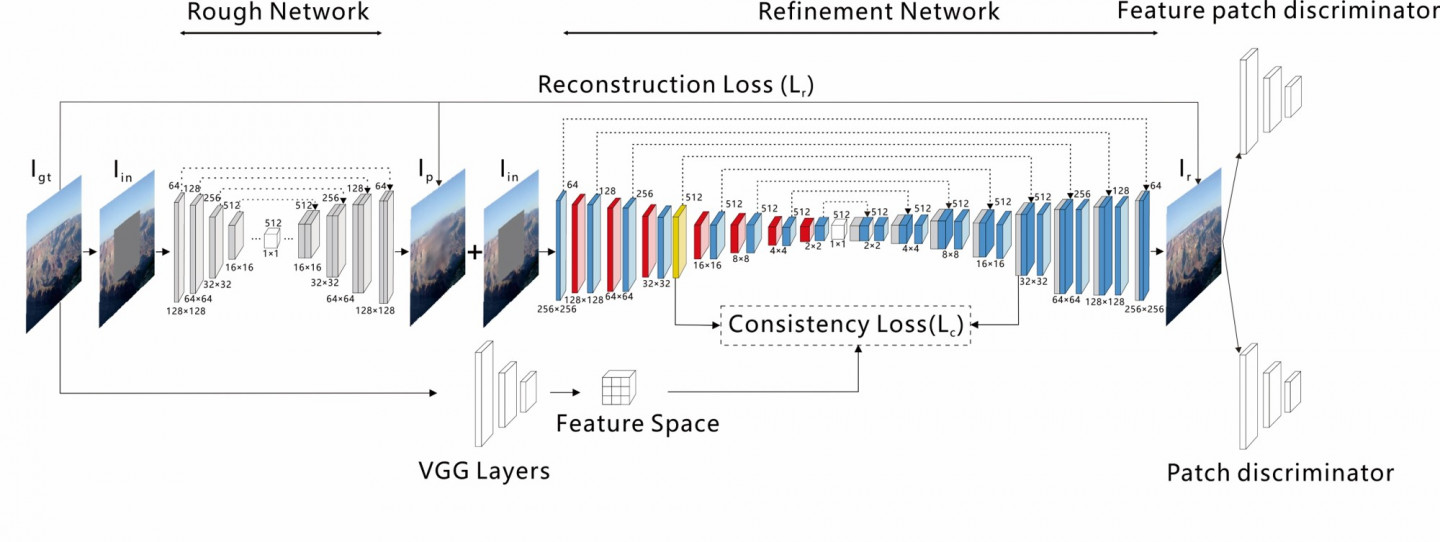
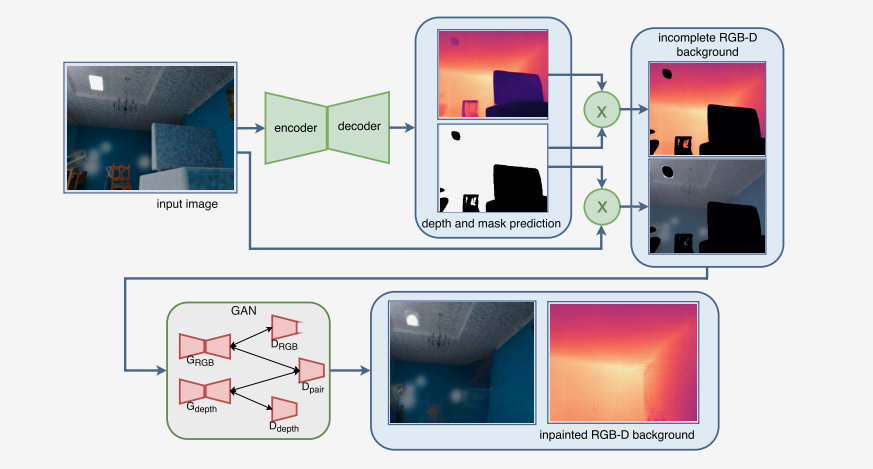
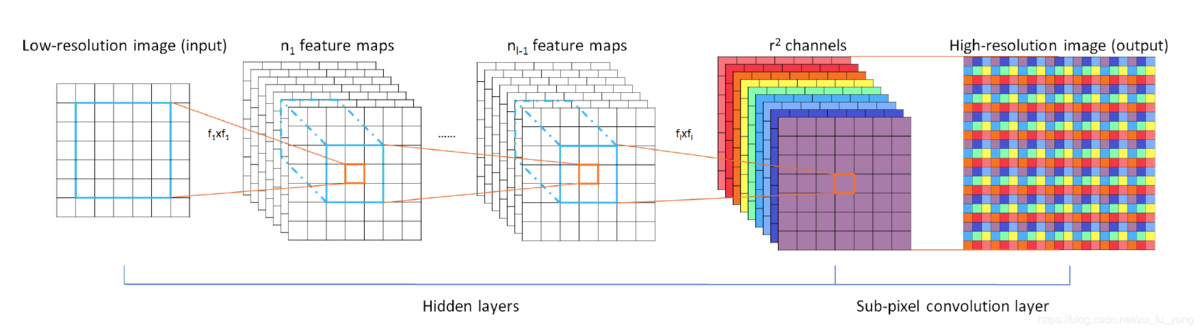
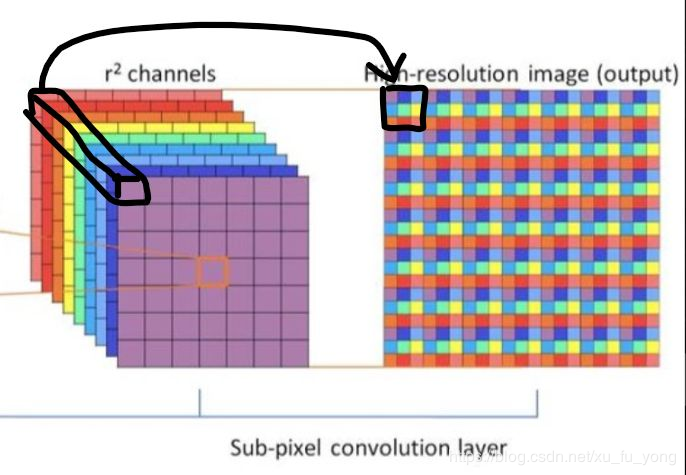
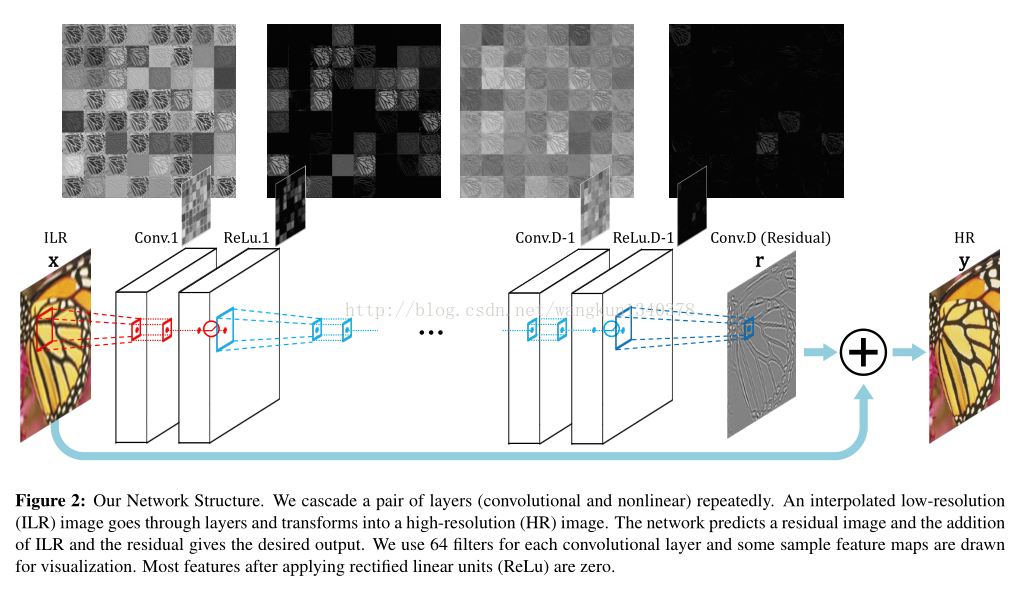
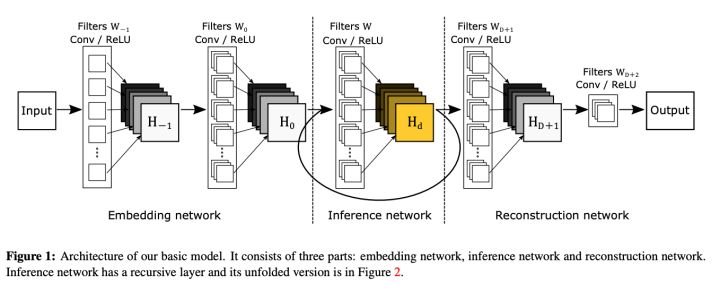
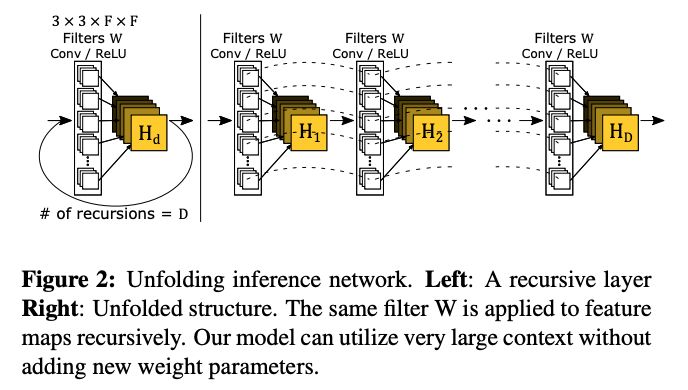
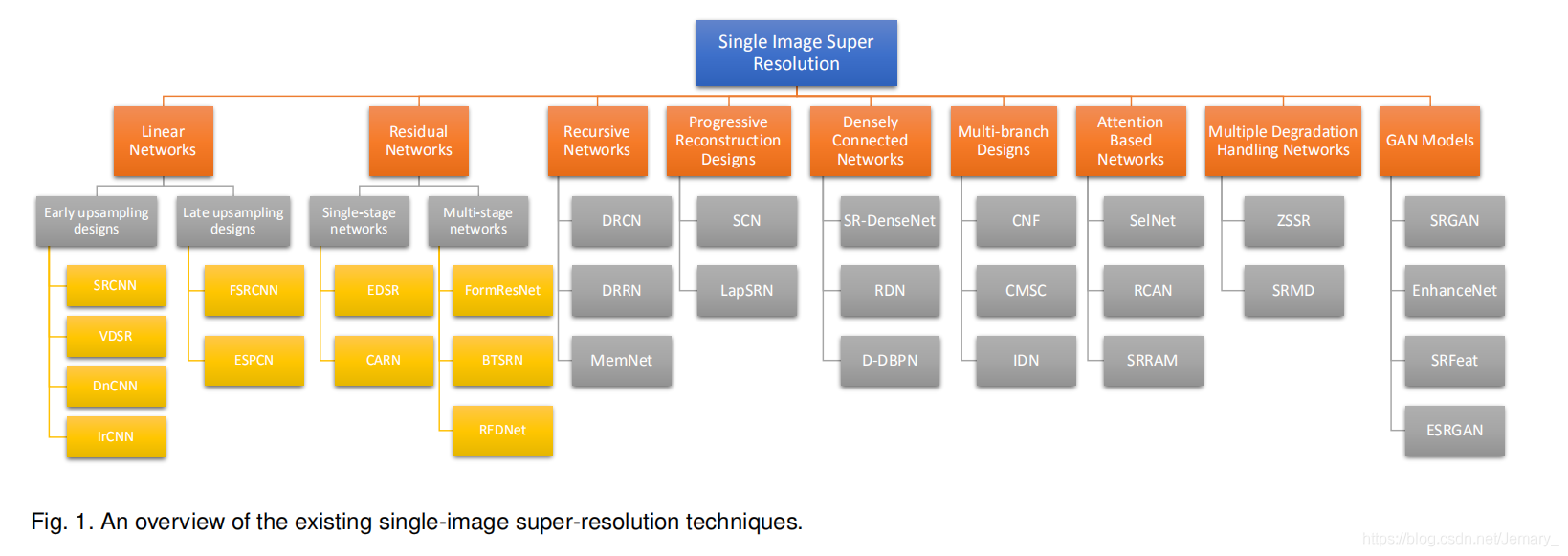
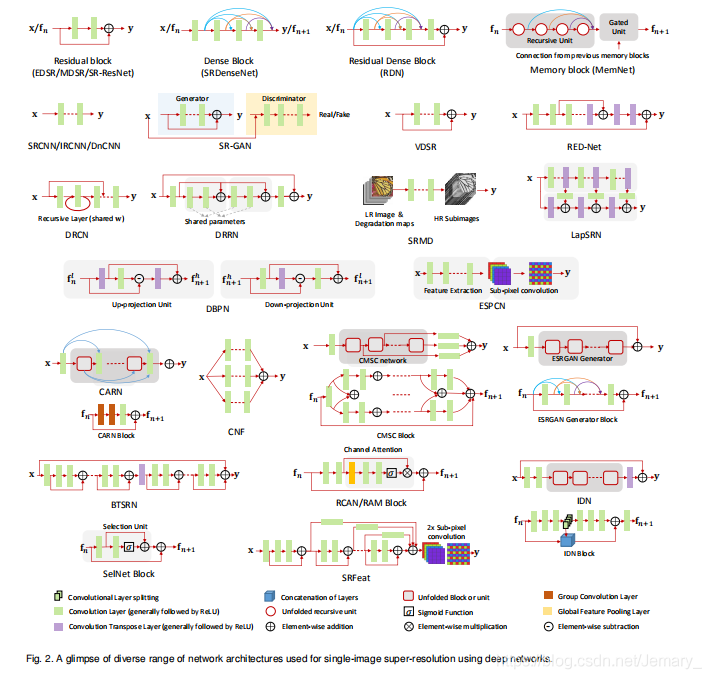
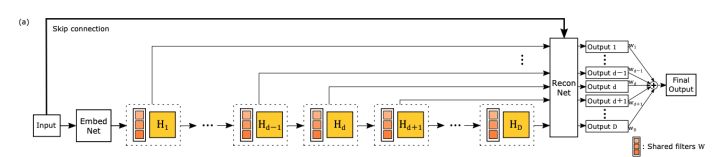 鉴于此,作者提出了递归监督的方法,来使得递归层中间的输出经过重建之后也可以加上监督的信息;然后采用残差学习的方法来解决输入与输出之间的这种长期依赖的关系,来使得输出获得较好的细节。
鉴于此,作者提出了递归监督的方法,来使得递归层中间的输出经过重建之后也可以加上监督的信息;然后采用残差学习的方法来解决输入与输出之间的这种长期依赖的关系,来使得输出获得较好的细节。