[数学体系解读](http://gwang-cv.github.io/2015/11/15/数学体系解读(by MIT Lin Dahua)/)
代数学、几何学、分析数学是数学的三大基础学科
[数学体系解读](http://gwang-cv.github.io/2015/11/15/数学体系解读(by MIT Lin Dahua)/)
代数学、几何学、分析数学是数学的三大基础学科
[TOC]
Principal Component Analysis(PCA)
Singular Value Decomposition (SVD),
Iterative Closest Point (ICP)
刚性3D点云配准算法研究 2014
使用深度传感器(例如飞行时间相机)获得的3D点云的几何对齐对于机器人技术和计算机视觉中的重要应用而言是一项艰巨的任务。由于便宜的深度感测设备的最新出现,文献中提出了许多不同的3D配准算法,着重于不同的领域,例如定位和映射或图像配准。在这篇调查论文中,我们回顾了最新的注册算法,并讨论了它们的通用数学基础。从简单的确定性方法(例如主成分分析(PCA)和奇异值分解(SVD))开始,对最近引入的方法(例如迭代最近点(ICP)及其变体)进行了分析和比较。
从简单的确定性方法(例如主成分分析(PCA)和奇异值分解(SVD))开始,对最近引入的方法(例如迭代最近点(ICP)及其变体)
https://blog.csdn.net/miracle0_0/article/details/82839534
傅里叶矩匹配(FMM)的加权重叠局部仿射图像配准算法[22]
https://github.com/marvin-eisenberger/smooth-shells
https://arxiv.org/abs/1905.12512
2009 book
从微观到宏观,可变形物体在我们周围的世界中无处不在。从医学到安全性的广泛应用都需要研究这种形状并对其行为进行建模。近年来,非刚性形状吸引了越来越多的兴趣,这导致了该领域的快速发展,其中最先进的技术源于截然不同的科学领域-理论和数值几何,优化,线性代数,图论,机器学习和计算机图形学(仅举几例)被用于寻找解决方案。
2012
2019

https://www.sciencedirect.com/topics/mathematics/eigensystem
数值分析手册,2019 5.3 Laplace–Beltrami特征图方法
5.3 使用LB特征图进行非刚性歧管配准
拉普拉斯-贝尔特拉米算子(Laplace–Beltrami operator)
基于四边形的网格通常使用Catmull-Clark,而基于三角形的网格通常使用环细分
https://ww2.mathworks.cn/matlabcentral/fileexchange/24942-loop-subdivision
https://ww2.mathworks.cn/matlabcentral/fileexchange/27982-wavefront-obj-toolbox?s_tid=srchtitle
function write_wobj(OBJ,fullfilename)
function read_wobj(fullfilename)
https://ww2.mathworks.cn/matlabcentral/fileexchange/18957-readobj?s_tid=srchtitle
function obj = readObj(fname)
商汤科技 SenseTime
[TOC]
入选CVPR 2020论文《对人脸生成模型的隐空间可解释性分析》提出了一种简单而通用的技术InterFaceGAN,用于在潜在空间中进行语义人脸编辑,可控制姿势以及其他面部属性,例如性别、年龄、眼镜等,还能够纠正GAN造成的伪影。

这种方法对GAN的隐空间进行了深入分析,能更好理解GAN是如何将一个随机噪声转化为一张高质量图片的。
《CARAFE:基于内容感知的特征重组》
《CARAFE: Content-Aware ReAssembly of FEatures》
特征上采样是深度神经网络结构中的一种基本的操作,例如:特征金字塔。它的设计对于需要进行密集预测的任务,例如物体检测、语义分割、实例分割,有着关键的影响。
内容感知的特征重组(CARAFE),它是一种通用的,轻量的,效果显著的特征上采样操作。
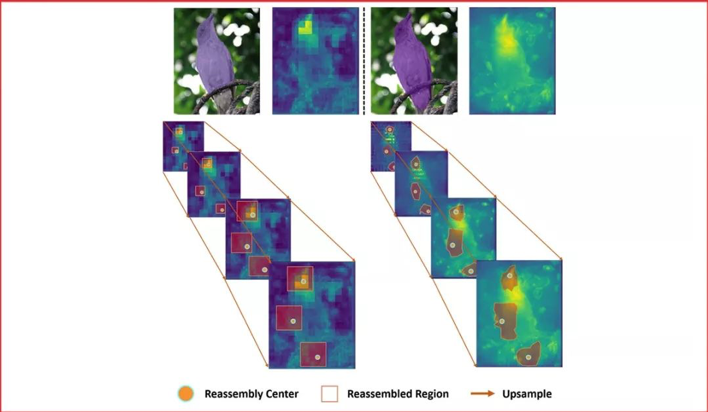
CARAFE有这样一些引人注目的特性:1.大视野。不同于之前的上采样方法(如:双线性插值),仅使用亚像素的临近位置。CARAFE可以聚合来自大感受野的环境特征信息。2.基于特征感知的处理。不同于之前方法对于所有样本使用固定的核(如:反卷积),CARAFE可以对不同的位置进行内容感知,用生成的动态的核进行处理。3.轻量和快速计算。CARAFE仅带来很小的额外开销,可以容易地集成到现有网络结构中。我们对CARAFE在目标检测,实例分割,语义分割和图像修复的主流方法上进行广泛的测试,CARAFE在全部4种任务上都取得了一致的明显提升。CARAFE具有成为未来深度学习研究中一个有效的基础模块的潜力。
Interpolated Convolutional Networks for 3D Point Cloud Understanding
内插卷积网络以了解3D点云
代表性论文:《基于插值卷积的点云处理主干网络》
点云是一种重要的三维数据类型,被广泛地运用于自动驾驶等场景中。传统方法依赖光栅化或者多视角投影,将点云转化成图像、体素其他数据类型进行处理。近年来池化和图神经元网络在点云处理中展现出良好的性能,但仍然受限于计算效率,并且算法易受物体尺度、点云密度等因素影响。
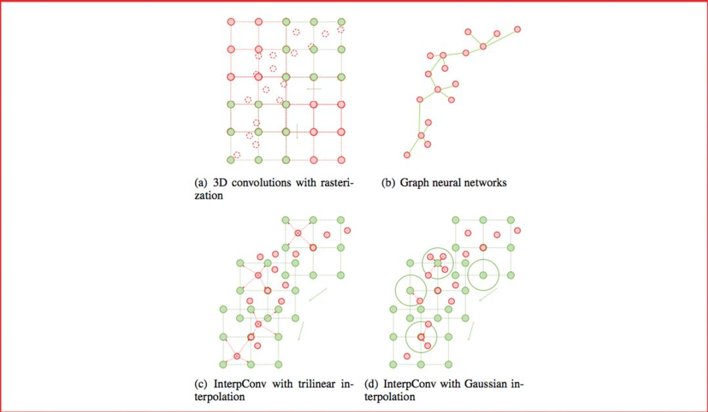
本文提出了一种全新的卷积方式,即插值卷积,能够从点云中高效地学习特征。插值卷积从标准图像卷积和图像插值中获取灵感,卷积核被划分成一组空间中离散的向量,每个向量拥有各自的三维坐标,当点云中的某点落在卷积向量的邻域时,参考图像插值的过程,我们将该点对应的特征向量插值到卷积向量对应的位置上,然后进行标准的卷积运算,最后通过正则化消除点云局部分布不均的影响。
面向不同的任务,我们提出了基于插值卷积的点云分类和分割网络。分类网络采用多路径设计,每一条路径的插值卷积核具有不同的大小,从而网络能够同时捕获全局和细节特征。分割网络参考图像语义分割的网络设计,利用插值卷积做降采样。在三维物体识别,分割以及室内场景分割的数据集上,我们均取得了领先于其他方法的性能。
代表性论文:《深入研究用于无限制图片3D人体重建中的混合标注》
《Delving Deep into Hybrid Annotations for 3D Human Recovery in the Wild》
https://penincillin.github.io/dct_iccv2019
虽然计算机视觉研究者在单目3D人体重建方面已经取得长足进步,但对无限制图片进行3D人体重建依然是一个挑战。主要原因是在无限制图片上很难取得高质量的3D标注。为解决这个问题,之前的方法往往采用一种混合训练的策略来利用多种不同的标注,其中既包括3D标注,也包括2D标注。虽然这些方法取得了不错的效果,但是他们并没有研究不同标注对于这个任务的有效程度。
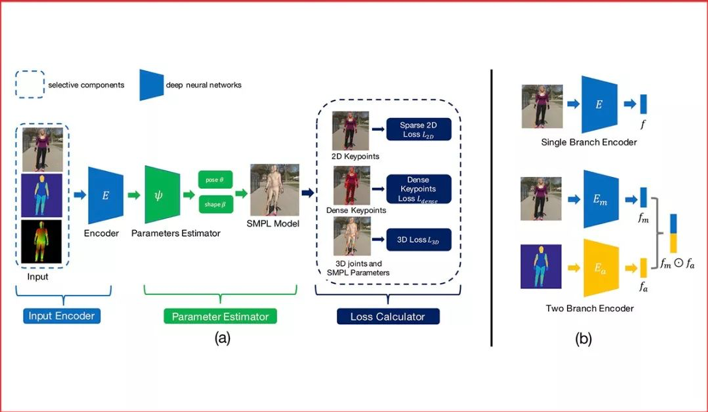
**本篇论文的目标就是详细地研究不同种类标注的投入产出比。**特别的,我们把目标定为重建给定无限制图片的3D人体。通过大量的实验,我们得到以下结论:1.3D标注非常有效,同时传统的2D标注,包括人体关键点和人体分割并不是非常有效。2.密集响应是非常有效的。当没有成对的3D标注时,利用了密集响应的模型可以达到使用3D标注训练的模型92%的效果。
代表性论文:《基于卷积网络的人体骨骼序列生成》
《Convolutional Sequence Generation for Skeleton-Based Action Synthesis》
现有的计算机视觉技术以及图形学技术已经可以生成或者渲染出栩栩如生的影像片段。在这些方法中,人体骨骼序列的驱动是不可缺少的。高质量的骨骼序列要么使用动作捕捉设备从人身上获取,要么由动作设计师手工制作。而让计算机代为完成这些动作,高效地生成丰富、生动、稳定、长时间的骨骼序列,就是这一工作的目标。
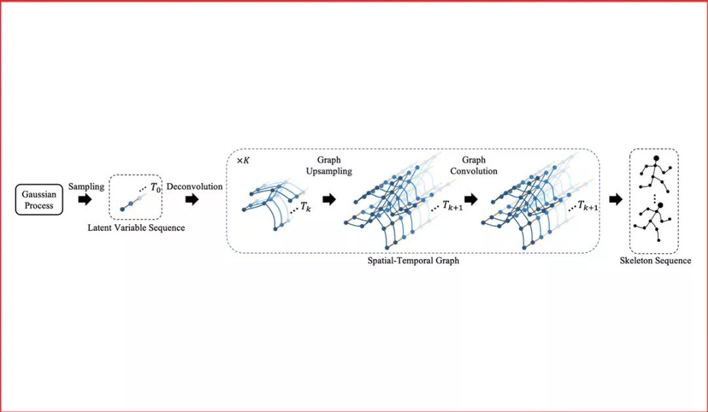
本文使用高斯过程产生随机序列,使用对抗网络和时空图卷积网络来学习随机序列和动作序列之间的映射关系。该方法既可以产生动作序列,也可将动作序列映射到随机序列所在的空间,并利用高斯过程进行编辑、合成、补全。
本方法在由真人动作捕捉得到的NTU-RGB+D数据集上,以及我们收集的虚拟歌手“初音未来”的大量舞蹈设计动作上,完成了详细的对比实验。实验表明,相对于传统的自回归模型(Autoregressive Model),本文使用的图卷积网络可以大大提高生成的质量和多样性。
代表性论文:《基于图匹配的电影视频跨模态检索框架》
电影视频检索在日常生活中拥有极大需求。例如,人们在浏览某部电影的文字简介时,时常会被其中的精彩部分吸引而想要看相应的片段。但是,通过文字描述检索电影片段目前还存在许多挑战。相比于日常生活中普通人拍摄的短视频,电影有着极大的不同:1.电影是以小时为单位的长视频,时序结构很复杂。2.电影中角色的互动是构成故事情节的关键元素。因此,我们利用了电影的这两种内在结构设计了新的算法来匹配文本段落与电影片段,进而达到根据文本检索电影片段的目标。
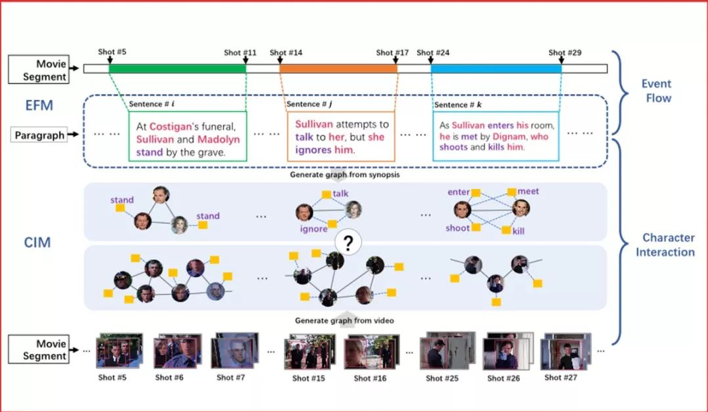
首先,我们提出事件流模块以建模电影的时序特性。该模块基于二分图匹配,将文本中的每一句话按照事件与电影片段的对应子片段匹配。其次,我们提出人物互动模块,该模块通过图匹配算法计算文本中解析得到的人物互动图和视频中提取的人物互动图的相似度。综合两个模块的结果,我们能得到与传统方法相比更精准的匹配结果,从而提高检索的正确率。
代表性论文:《融合视觉信息的音频修复》
多模态融合是交互智能发展的重要途径。在多媒体信息中,一段音频信号可能被噪声污染或在通信中丢失,从而需要进行修复。本文我们提出依据视频信息对缺失音频信息进行修复的一种融合视觉信息的音频修复方案。
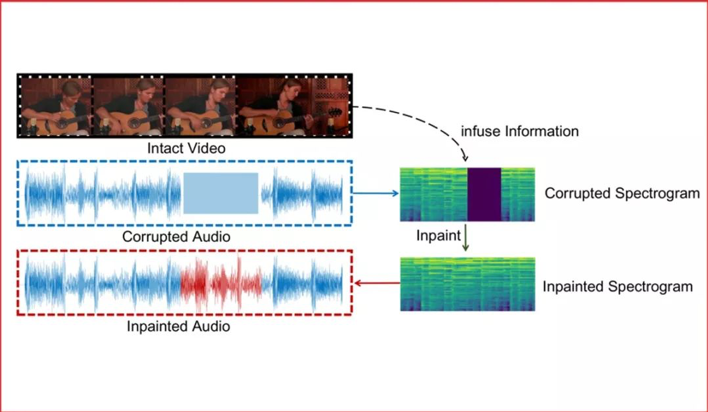
此方案核心思想在于:1.将音频信号在频谱上进行操作,并将频谱作为二维图像信号进行处理,可以极大地利用计算机视觉领域的优势,超越传统的音频解决方案。2.为了融合视觉信息,基于音视频同步学习得到的联合子空间会发挥巨大的优势。
针对此问题的研究,我们将已有的多模态乐器演奏数据集MUSIC扩大成为一个新的更全面的数据集,MUSICES。实验证明我们提出的视觉融合的音频修复系统可以在没有视频信息注入的情况下取得可观的效果,并在加入视频信息后,生成与视频和谐的音频片段。
https://ps.is.tuebingen.mpg.de/research_projects/virtual-humans-old
人体肯定对我们的生活至关重要,通常以图像和视频形式描绘。通过学习人体的形状以及如何从数据中移动出来,我们正在开发世界上最真实的人体模型。我们的目标是使人体3D模型的外观和移动方式与真实人类没有区别。这样的虚拟人可以用于特殊效果,并将在新兴的虚拟现实系统中扮演重要角色。它们还可以用于计算机视觉,以生成用于学习方法的训练数据,或者可以直接适合于传感器数据。造成这种困难的原因是,人体的关节运动非常激烈,会随着运动的变化而变形,并且在各个对象之间呈现出很大的形状变异性。
在过去的五年中,我们开发了一系列可用于图形和视觉的3D人体模型:BlendSCAPE [ ], Delta [ ], Dyna [ ] and SMPL [ ]。特别是,SMPL是一种逼真的人体模型,比以前的SCAPE模型更准确,但它基于标准的混合蒙皮和混合形状。姿势混合形状可纠正混合蒙皮伪影,并由身体部位旋转矩阵的元素驱动。形状融合形状可以捕捉人的身体形状变化情况。这些是使用4000人的姿态标准化3D扫描计算得出的。动态混合形状捕获软组织如何随着运动变形。
我们公式的简单性意味着可以从大量数据中训练SMPL。这也意味着它与当前的游戏引擎和图形软件兼容,运行速度比实时速度快得多。该模型已获Body Labs Inc.商业许可,可免费用于研究目的。
概念理解:什么是人脸识别?
人脸识别的过程中有4个关键的步骤:
常用api: Yolo > Dlib > cv2
人脸检测的目的是寻找图片中人脸的位置。当发现有人脸出现在图片中时,不管这个脸是谁,都会标记出人脸的坐标信息,或者将人脸切割出来。
可以使用方向梯度直方图(HOG)来检测人脸位置。先将图片灰度化,接着计算图像中像素的梯度。通过将图像转变成HOG形式,就可以获得人脸位置。

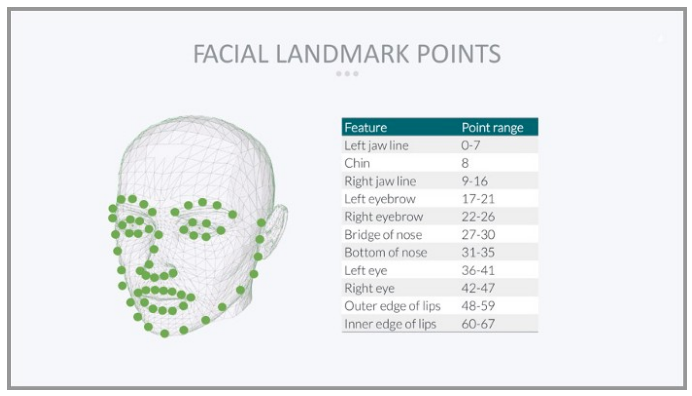
人脸对齐是将不同角度的人脸图像对齐成同一种标准的形状。
先定位人脸上的特征点,然后通过几何变换(仿射、旋转、缩放),使各个特征点对齐(将眼睛、嘴等部位移到相同位置)。
人脸图像的像素值会被转换成紧凑且可判别的特征向量,这也被称为模板(template)。理想情况下,同一个主体的所有人脸都应该映射到相似的特征向量。

在人脸匹配构建模块中,两个模板会进行比较,从而得到一个相似度分数,该分数给出了两者属于同一个主体的可能性。

一文看懂人脸识别-4个特点-4个实现步骤-5个难点-算法发展轨迹
人脸识别(Facial Recognition),即通过视频采集设备获取用户的面部图像,再利用核心的算法对其脸部的五官位置、脸型和角度进行计算分析,进而和自身数据库里已有的范本进行比对,从而判断出用户的真实身份.人脸识别算法,在检测到人脸并定位面部关键特征点之后,主要的人脸区域就可以被裁剪出来,经过预处理之后,馈入后端的识别算法。识别算法要完成人脸特征的提取,并与库存的已知人脸进行比对,完成最终的分类
2、人脸验证
人脸验证做的是1:1的比对,其身份验证模式本质上是计算机对当前人脸与人像数据库进行快速人脸比对,并得出是否匹配的过程,可以简单理解为证明你就是你。就是我们先告诉人脸识别系统,我是张三,然后用来验证站在机器面前的“我”到底是不是张三。
这种模式最常见的应用场景便是人脸解锁,终端设备(如手机)只需将用户事先注册的照片与临场采集的照片做对比,判断是否为同一人,即可完成身份验证.1:1作为一种静态比对,一般在金融、信息安全领域中应用较多。例如在高速路、机场安检时,受检人员手持身份证等证件,通过检查通道,同时对受检人员的外貌及身份证信息进行识别,此过程就是典型的1:1模式的人脸识别。
1,face++(0.9950 );2,DeepFace(0.9735 );3,FR+FCN(0.9645 );4,DeepID(0.9745 );5,FaceNet(0.9963 );6, baidu的方法(0.9977 );7,pose+shape+expression augmentation(0.9807);8,CNN-3DMM estimation(0.9235 )
第一类:face++,DeepFace,DeepID,FaceNet和baidu。他们方法的核心是搜集大数据,通过更多更全的数据集让模型学会去识别人脸的多样性。这类方法适合百度/腾讯/谷歌等大企业,未来可以搜集更多更全的训练数据集。数据集包扩同一个体不同年龄段的照片,不同人种的照片,不同类型(美丑等)。通过更全面的数据,提高模型对现场应用中人脸差异的适应能力。
第二类:FR+FCN,pose+shape+expression augmentation和CNN-3DMM estimation。这类方法采用的是合成的思路,通过3D模型等合成不同类型的人脸,增加数据集。这类方法操作成本更低,更适合推广。其中,特别是CNN-3DMM estimation,作者做了非常出色的工作,同时提供了源码,可以进一步参考和深度研究。
常规人脸识别流程是:人脸检测-对齐-表达-分类。
一,基于3d模型的人脸对齐方法;二,大数据训练的人工神经网络。
简介:基于开源框架实现的人脸识别、脸脸检测、人脸关键点检测等任务 各个任务分别在FaceDetection, FaceAlignment, FaceRecognition 三个文件中。人脸检测 baseline: 基于基于滑动窗口的人脸检测,将训练好了的网络改为全卷积网络,然后利用全卷积网络对于任意大小的图像输入,进行获取输出HeapMap。
源码网址:https://github.com/RiweiChen/DeepFace
1 | detect -> aligh -> represent -> classify |
DeepID和FaceNet并没有对齐,
DeepID的解决方案是将一个人脸切成很多部分,每个部分都训练一个模型,然后模型聚合。
FaceNet则是没有考虑这一点,直接以数据量大和特殊的目标函数取胜。
https://github.com/deepinsight/insightface
face_recognition 史上最简单的人脸识别项目登上GitHub趋势榜
基于机器学习人脸识别face recognition具体的算法和原理
人脸识别、人脸检测、人脸对齐相关算法和论文汇总 https://github.com/polarisZhao/awesome-face
Free and open source face recognition with deep neural networks.
FaceDetection,
FaceAlignment,
FaceRecognition
Face Detection: baseline: 基于基于滑动窗口的人脸检测,将训练好了的网络改为全卷积网络,然后利用全卷积网络对于任意大小的图像输入,进行获取输出HeapMap。
人脸关键点检测: try1_1: 基于DeepID网络结构的人脸关键点检测
Identifition : deepid: 基于DeepID网络结构的人脸验证
Face alignment using MTCNN
Face Recognition using Inception-ResNet-v1 model
face_locations: 返回人脸的box
face_landmarks: 返回人脸的关键点,五官,轮廓 _raw_face_landmarks
face Recognition:
face_encodings: _raw_face_landmarks
compare_faces
特点:
face detection 提取
face alignment 对齐
face recongnition 识别
detection
alignment
FaceDetection,
FaceAlignment,
FaceRecognition
1.单个CNN人脸检测方法
2.级联CNN人脸检测方法
3.OpenCV人脸检测方法
4.Dlib人脸检测方法
5.libfacedetect人脸检测方法
6.Seetaface人脸检测方法
《A Convolution Neural Network Cascade for Face Detection》
http://www.cs.stevens.edu/~ghua/publication/CVPR15b.pdf
Face Alignment
MTCNN 包含三个级联的多任务卷积神经网络,分别是 Proposal Network (P-Net)、Refine Network (R-Net)、Output Network (O-Net),每个多任务卷积神经网络均有三个学习任务,分别是人脸分类、边框回归和关键点定位。
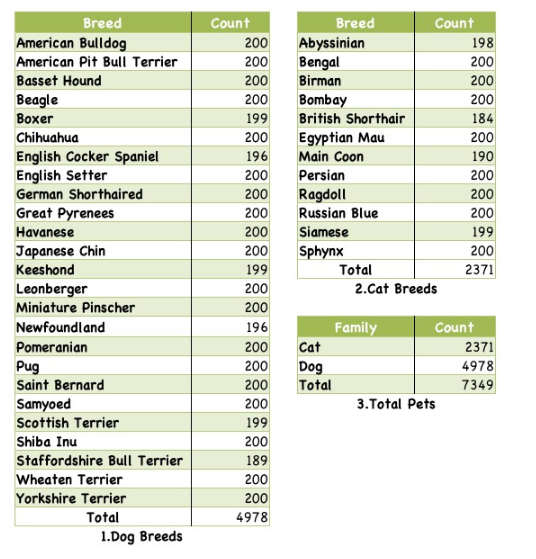
http://www.robots.ox.ac.uk/~vgg/data/pets/
37种宠物,每种宠物200张左右宠物图片,并同时包含宠物轮廓标注信息。


37种 宠物
1-Dog 种类:25
2-Cat 种类:12
[TOC]
计算机视觉领域
https://www.paperswithcode.com/area/computer-vision
UMD Faces Dataset 是一个面部数据集,主要用于身份鉴定研究,它拥有 8501 个主题共计 367,920 个面孔。该数据集分为静止图像和视频帧两部分,其中静止图像包含 367,888 张图,共计 8277 个主题;视频帧则包含 22,000 个主题视频,共计 370 万个带注释的视频帧。
https://hyper.ai/datasets/5537
300 Faces In-the-Wild Challenge (300-W)
官网介绍:https://ibug.doc.ic.ac.uk/resources/300-W/
中文介绍:https://blog.csdn.net/lgh0824/article/details/88536215
http://www.cbsr.ia.ac.cn/users/xiangyuzhu/projects/3DDFA/main.htm
300W-3D
300W-3D-Face
300W-LP 合成了300W的大姿态人脸图像。
1 | [300W-3D]: https://drive.google.com/file/d/0B7OEHD3T4eCkRFRPSXdFWEhRdlE/view?usp=sharing |
项目:3DDFA
AFLW2000-3D由AFLW数据库的前2000张图片及其三维信息组成。三维信息由3DMM重建(Blanz et.al A morphable model for the synthesis of 3d faces, SIGGRAPH’99)得到,并且包含68个特征点的三维信息。该数据库的三维数据精准度存在争议。
————————————————
1 | /media/simon/新加卷1/dataset/3d_face/AFLW2000/ |
1 | 具体包含以下内容: |
 image00040.mat
image00040.mat
常用于3D人体姿态估计
11个人
Diversity and Size
Accurate Capture and Synchronization
Support for Development
| 数据库 | 网址 | header 2 |
|---|---|---|
| FAUST | http://faust.is.tue.mpg.de/ | A data set containing 300 real, high-resolution human scans, with automatically computed ground-truth correspondences. 一个包含300个真实,高分辨率人体扫描的数据集,具有自动计算的地面实况对应关系(Max Planck Tubingen) |
| Dynamic FAUST | 3D人体动态数据库, 提供40,000个原始网格和对齐网格的数据集 |
SMPL使用的数据集
CAESAR http://store.sae.org/caesar/ 美国和欧洲的表面人体测量资源项目
10,000美元,2,400名男性和女性
使用十个对象的40,000多次扫描
dataset contains synthetic meshes of fixed topology with artist-defined deformations.
数据集包含具有艺术家定义的变形的固定拓扑的合成网格。
synthetic dataset that is widely used for evaluation of mesh registration methods. It provides 80 artificially created meshes of animals and people (with 3 subjects in a dozen different poses each).
为TOSCA添加了各种⼈造噪声⽹格,
Given static 3D scans or 3D scan sequences (in pink), we estimate the naked shape under clothing (beige)
给定3D扫描序列,我们的模型评估不穿衣服的人体。
includes high resolution 3D scan sequences of 3 males and 3 females in different clothing styles.
3男3女的高分辨率的穿不同衣服的数据集。
https://blog.csdn.net/m0_37570854/article/details/88736189
https://graphics.soe.ucsc.edu/data/BodyModels/index.html
90G
baidu faces_glintasia.zip
dropbox faces_glintasia.zip
[1] Dong Yi, Zhen Lei, Shengcai Liao, Stan Z. Li. Learning Face Representation from Scratch. arXiv:1411.7923, 2014.
[2] Ziwei Liu, Ping Luo, Xiaogang Wang, Xiaoou Tang. Deep Learning Face Attributes in the Wild, ICCV, 2015.
[3] Bansal Ankan, Nanduri Anirudh, Castillo Carlos D, Ranjan Rajeev, Chellappa, Rama. UMDFaces: An Annotated Face Dataset for Training Deep Networks, arXiv:1611.01484v2, 2016.
[4] Qiong Cao, Li Shen, Weidi Xie, Omkar M. Parkhi, Andrew Zisserman. VGGFace2: A dataset for recognising faces across pose and age. FG, 2018.
[5] Yandong Guo, Lei Zhang, Yuxiao Hu, Xiaodong He, Jianfeng Gao. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. ECCV, 2016.
[6] Jiankang Deng, Yuxiang Zhou, Stefanos Zafeiriou. Marginal loss for deep face recognition, CVPRW, 2017.
[7] Jiankang Deng, Jia Guo, Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition, arXiv:1801.07698, 2018.
[8] http://trillionpairs.deepglint.com/
[9] Wang Fei, Chen Liren, Li Cheng, Huang Shiyao, Chen Yanjie, Qian Chen, Loy, Chen Change. The Devil of Face Recognition is in the Noise, ECCV, 2018.
[10] Cao Jiajiong, Li Yingming, Zhang Zhongfei, Celeb-500K: A Large Training Dataset for Face Recognition, ICIP, 2018.
[11] Nech Aaron, Kemelmacher-Shlizerman Ira, Level Playing Field For Million Scale Face Recognition, CVPR, 2017.
[12] Sengupta Soumyadip, Chen Jun-Cheng, Castillo Carlos, Patel Vishal M, Chellappa Rama, Jacobs David W, Frontal to profile face verification in the wild, WACV, 2016.
[13] Moschoglou, Stylianos and Papaioannou, Athanasios and Sagonas, Christos and Deng, Jiankang and Kotsia, Irene and Zafeiriou, Stefanos, Agedb: the first manually collected, in-the-wild age database, CVPRW, 2017.
[14] Gary B. Huang, Manu Ramesh, Tamara Berg, and Erik Learned-Miller. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments, 2007.
[15] Zheng Tianyue, Deng Weihong, Hu Jiani, Cross-age lfw: A database for studying cross-age face recognition in unconstrained environments, arXiv:1708.08197, 2017.
[16] Zheng, Tianyue, and Weihong Deng. Cross-Pose LFW: A Database for Studying Cross-Pose Face Recognition in Unconstrained Environments, 2018.
[TOC]
Gerard Pons-Moll virtualhumans.mpi-inf.mpg.de官网

问题: 如何对衣服进行捕捉
输入: 扫描获得的4D的有纹理的人体数据
输出: 多种衣服几何模型

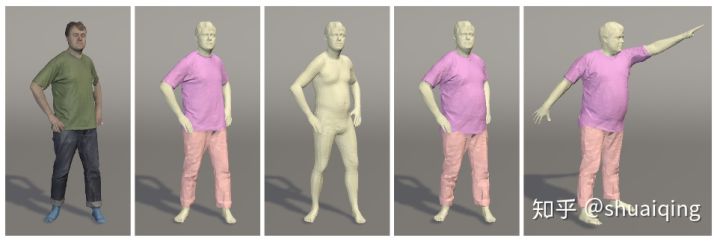
问题: 如何生成多种衣服外观的人体图片
输入: 有姿势的SMPL模型,及其分割
输出: 不同衣着的对应姿势的图片
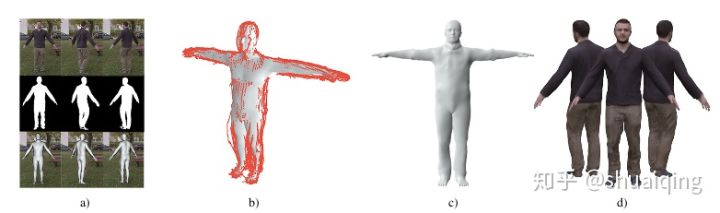
问题: 如何从RGB视频中获取细致的人体模型
输入: 单人的单目视频+轮廓
输出: 基于SMPL的细致的人体模型
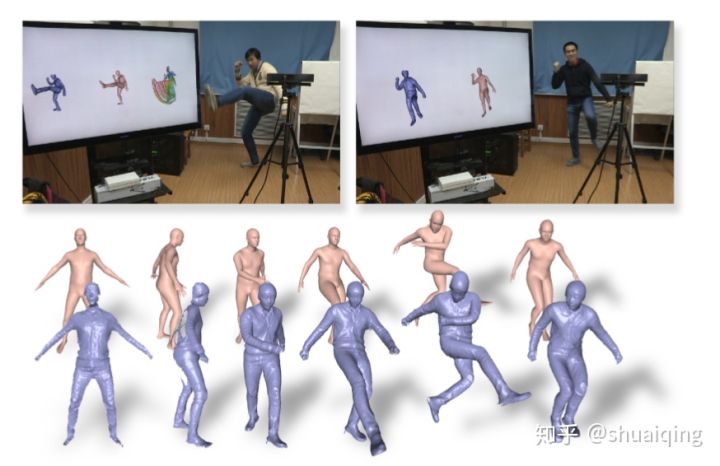
问题: 如何从RGBD数据中实时获取细致的人体模型
输入: 单人的实时的RGBD数据流
输出: 基于SMPL的细致的人体模型
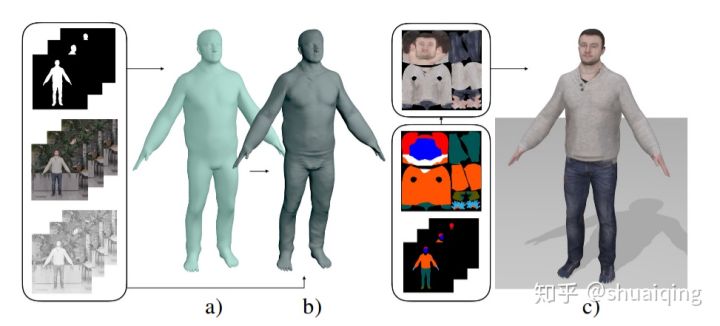
问题: 如何从RGB视频中获取细致的人体模型
输入: 单人的单目视频+轮廓信息+语义分割
输出: 基于SMPL的更细致的人体模型
和之前的区别是,
代码:
纹理拼接代码semantic human texture stitching
基于SMPL的p,$\theta$新增了W(混合皮肤)
skeleton joints J(β)
标准T-Pose
consists of N = 110210 vertices and F = 220416 faces.
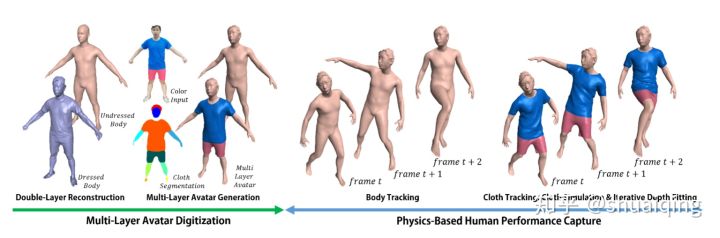
问题: 对人体与衣服同时进行重建
输入: 实时的RGBD数据
输出: 人体模型与多层的衣服模型
方法:
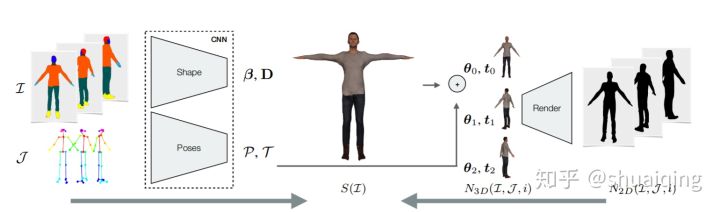
问题: 如何快速地从RGB相机的图像中去重建有衣服的人体
输入: 同一个人的几个视角下的图片
输出: SMPL+D的细致的人体形状,纹理是后处理贴的 (Octopus的网络输出的对象无法贴处理过的纹理,还在研究中)
训练: 使用合成数据训练, 渲染过程可微
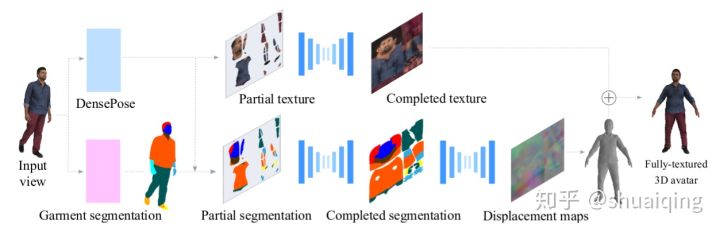
问题: 如何从单张图片中去获取有纹理的细致的人体模型
输入: 单张RGB图片
输出: 有纹理的三维人体模型-> texture map + displacement map
训练: 用之前扫描获得的人体数据生成UV map和displacement map
这篇用了几个下载人体模型的网站,需要用的时候可以看看

问题: 如何从单张图片中去获取有纹理的细致的人体模型
输入: 单张RGB图片
输出: 细致的人体模型->输出normal map和displacement map
训练: 合成,渲染
文章最后还说了另一种思路的虚拟试衣功能的方法: 对于SMPL来说, 换装等价于保留其shape参数, 更换他的normal map和displacement map
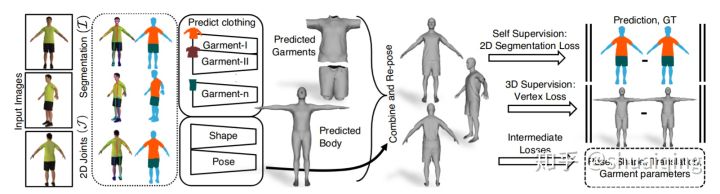
问题: 如何从单张图片中去获取有纹理的细致的人体模型
输入: 多个视角下的RGB图片->2D关键点与语义分割
输出: 在标准模型下的人体参数, 多片衣服参数
训练: 合成,渲染