max_correspondence_distance (float) – Maximum correspondence points-pair distance.
estimation_method (open3d.registration.TransformationEstimation,optional,default=registration::TransformationEstimationPointToPoint without scaling.) – Estimation method. One of (registration::TransformationEstimationPointToPoint, registration::TransformationEstimationPointToPlane)
ransac_n (int,optional,default=4) – Fit ransac with ransac_n correspondences
criteria (open3d.registration.RANSACConvergenceCriteria,optional,default=registration::RANSACConvergenceCriteria class with max_iteration=100000,and max_validation=100) – Convergence criteria
Returns
open3d.registration.RegistrationResult
open3d.registration.RegistrationResult
propertycorrespondence_set
Correspondence set between source and target point cloud.Typen x 2 int numpy array
Check if two point clouds build the polygons with similar edge lengths. That is, checks if the lengths of any two arbitrary edges (line formed by two vertices) individually drawn withinin source point cloud and within the target point cloud with correspondences are similar. The only parameter similarity_threshold is a number between 0 (loose) and 1 (strict)
/** * Translate a mat4 by the given vector * * @param {mat4} out the receiving matrix * @param {mat4} a the matrix to translate * @param {vec3} v vector to translate by * @returns {mat4} out */ function translate(out, a, v) { var x = v[0], y = v[1], z = v[2]; var a00 = void 0, a01 = void 0, a02 = void 0, a03 = void 0; var a10 = void 0, a11 = void 0, a12 = void 0, a13 = void 0; var a20 = void 0, a21 = void 0, a22 = void 0, a23 = void 0;
if (a === out) { out[12] = a[0] * x + a[4] * y + a[8] * z + a[12]; out[13] = a[1] * x + a[5] * y + a[9] * z + a[13]; out[14] = a[2] * x + a[6] * y + a[10] * z + a[14]; out[15] = a[3] * x + a[7] * y + a[11] * z + a[15]; } else { a00 = a[0];a01 = a[1];a02 = a[2];a03 = a[3]; a10 = a[4];a11 = a[5];a12 = a[6];a13 = a[7]; a20 = a[8];a21 = a[9];a22 = a[10];a23 = a[11];
Robust Reconstruction of Indoor Scenes, CVPR, 2015. S.Choi, Q.-Y. Zhou, and V. Koltun
Multiway registration is the process to align multiple pieces of geometry in a global space. Typically, the input is a set of geometries (e.g., point clouds or RGBD images) $ {𝐏_𝑖} $. The output is a set of rigid transformations ${𝐓_𝑖}$, so that the transformed point clouds ${𝐓_𝑖 P_i} $ are aligned in the global space.
Supply
《Alignment of 3D models》
《A 3D Model Alignment and Retrieval System》
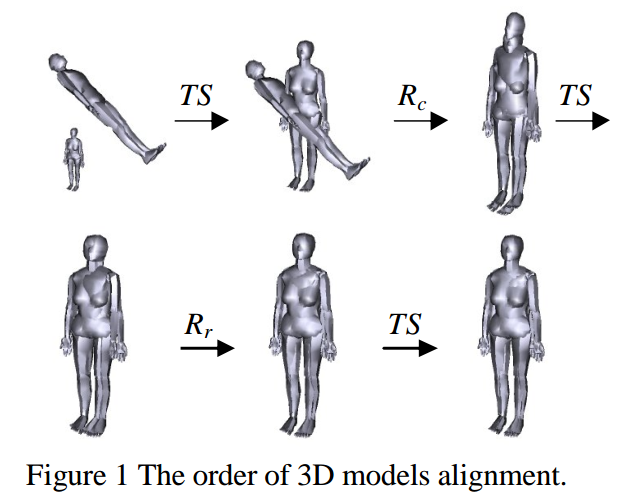
$TS -> R_c -> TS -> R_r -> TS$
AlignNet-3D
引言 Align(register) point clouds 即对齐(配准)点云,意思是将一个点云匹配到另一个点云上面,主要用来将从一个物体的不同角度得到的局部点云拼接起来,由此得到一个完整的3D模型,对点云做Alignment或Registration从本意上来说并没有什么本质的区别,尤其是在阅读学术论文的时候。
AlignNet-3D介绍 AlignNet-3D是论文AlignNet-3D: Fast Point Cloud Registration of Partially Observed Objects里研究的一种align点云的方法,论文主要研究了智能汽车的精确3D跟踪状态估计,提出了一个以学习为基础的方法AlignNet-3D来对不同时间捕获的汽车点云做Alignment,以此来估计汽车近距离内的精确运动,作者的评估表明AlignNet-3D在计算上优于global 3D registration,同时显著提高了效率。
C:\Users\Simon\AppData\Local\Temp\ccwu1HiS.o: In function main': D:/Qiansi/games/DDZ-QS-Server/AI_server_Star_call/main.cpp:22: undefined reference to ddzmove_star::get_move_type(int*)’ collect2.exe: error: ld returned 1 exit status
The terminal process “C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe -Command g++ -g D:\Qiansi\games\DDZ-QS-Server\AI_server_Star_call/main.cpp D:\Qiansi\games\DDZ-QS-Server\AI_server_Star_call/ddz_move_star.cpp -I D:\Qiansi\games\DDZ-QS-Server\AI_server_Star_call/ -o main.exe” terminated with exit code: 1.
Terminal will be reused by tasks, press any key to close it.
We have already discussed how to install ubuntu 9.04 LAMP server .If you are a new user and not familiar with command prompt you can install GUI for your ubuntu LAMP server using the 2 options
Install desktop Environment
Install Webmin
1) Install desktop Environment
First you nee to make sure you have enabled Universe and multiverse repositories in /etc/apt/sources.list file once you have enable you need to use the following command to install GUI
sudo apt-get update
sudo apt-get install ubuntu-desktop
The above command will install GNOME desktop
If you wan to install a graphical desktop manager without some of the desktop addons like Evolution and OpenOffice, but continue to use the server flavor kernel use the following command
# Install and configure X window with virtual screen sudo apt-get install xserver-xorg libglu1-mesa-dev freeglut3-dev mesa-common-dev libxmu-dev libxi-dev # Configure the nvidia-x sudo nvidia-xconfig -a --use-display-device=None --virtual=1280x1024 # Run the virtual screen in the background (:0) sudo /usr/bin/X :0 & # We only need to setup the virtual screen once # Run the program with vitural screen DISPLAY=:0 <program> # If you dont want to type `DISPLAY=:0` everytime export DISPLAY=:0
sudo nvidia-xconfig -a –use-display-device=Device0 –virtual=1280x1024
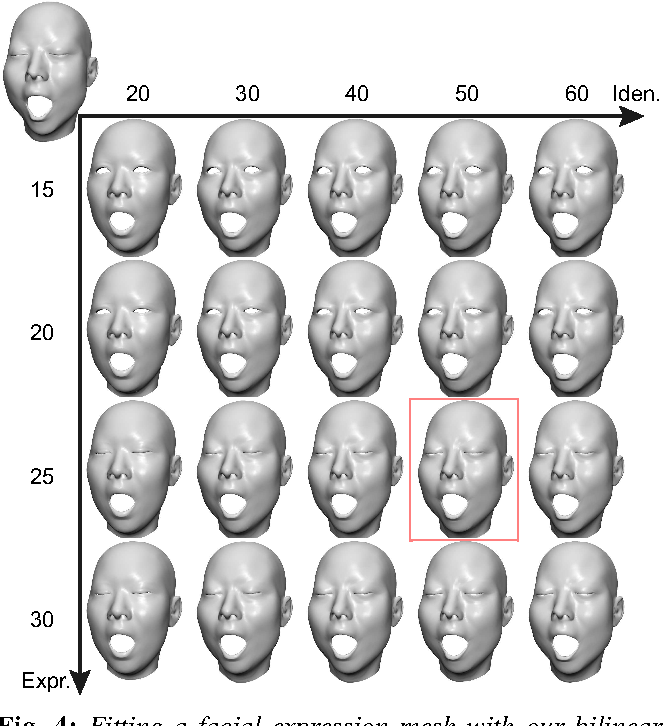
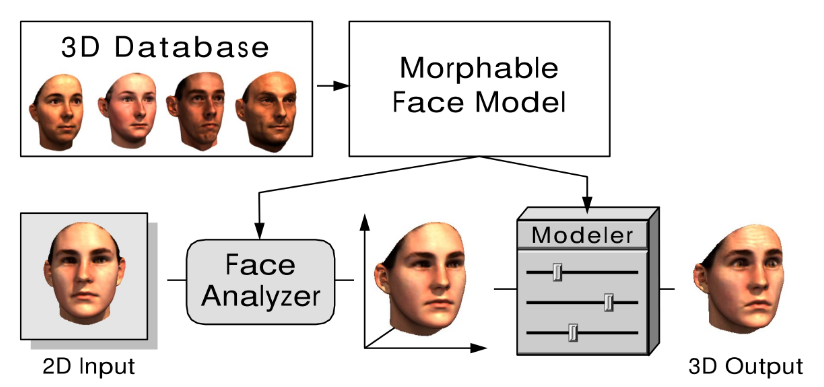
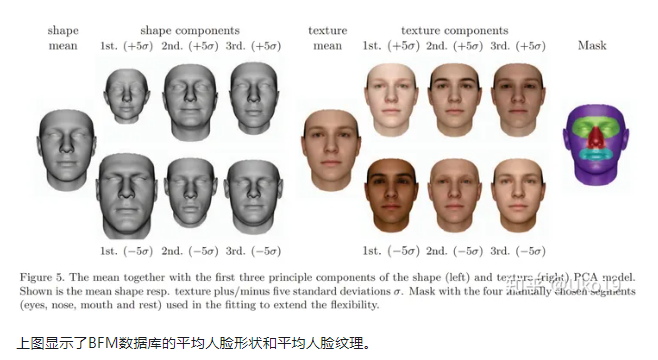
这篇文章的方法主要致力于将3DMM应用到实际开发中,作者提出一个基于C++的拟合框架,可支持Surrey Face Model (SFM), 4D Face Model (4DFM), and the Basel Face Model (BFM) 2009 and 2017数据库,目前这个拟合框架仍在更新。
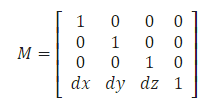
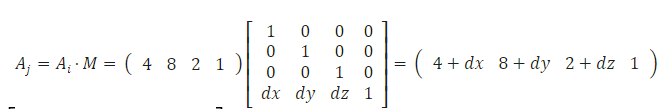









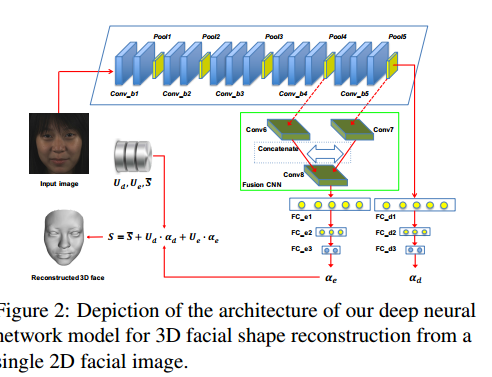







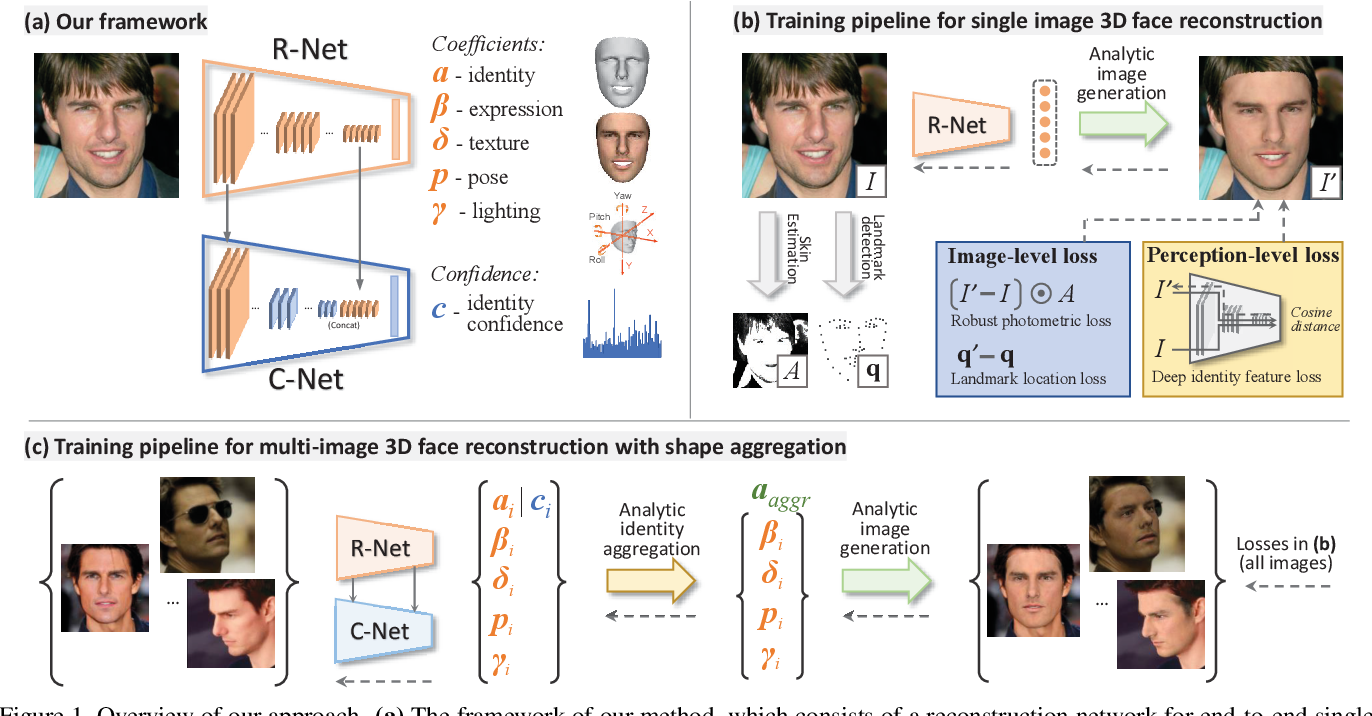

![图2。我们的方法在AFLW2000-3D上的人脸重建和对齐结果[2]。](/2020/02/10/CV_3D/CV-3D-Face-Model/2-Figure2-1.png)