2006 《Multi-Label Neural Networks with Applications to Functional Genomics and Text Categorization》Min-Ling Zhang and Zhi-Hua Zhou. IEEE Transactions on Knowledge and Data Engineering 18, 10 (2006), 1338–1351.
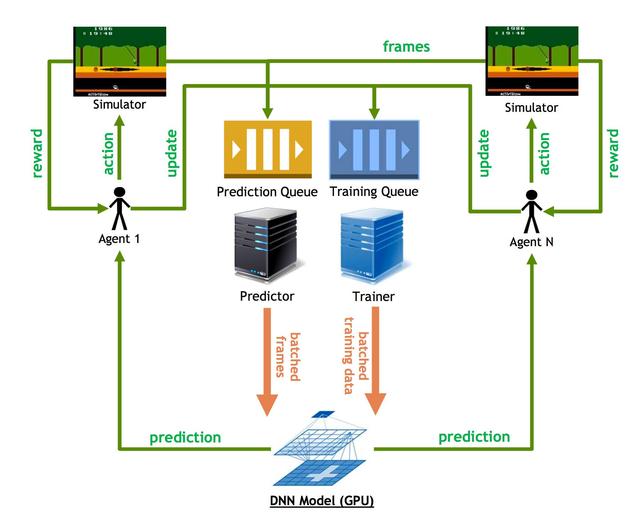
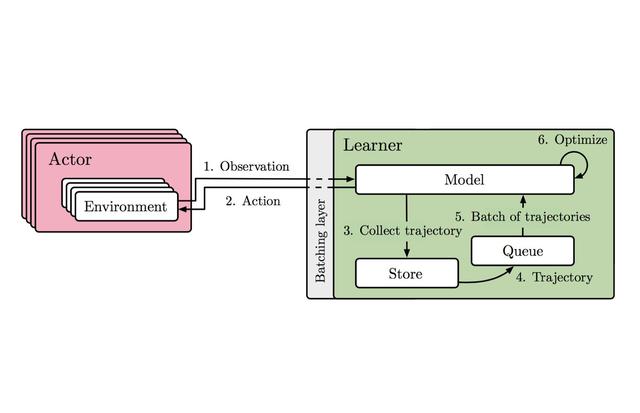
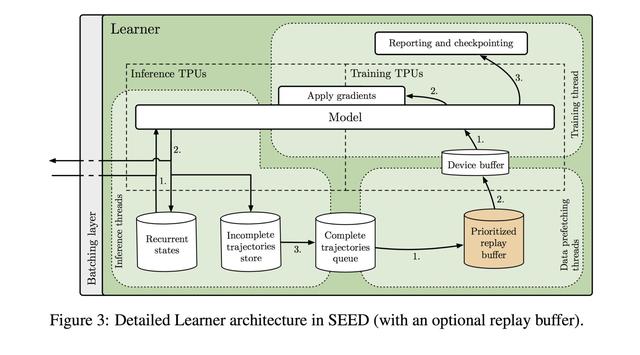
Architecture
1、方差损失
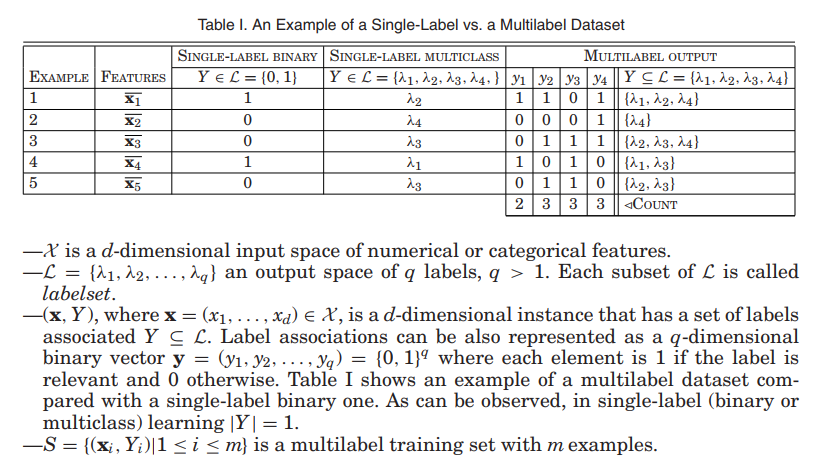
global error $$ E = \sum_{i=1}^{m}E_i $$ m multi-label instances .
Q lables $$ E_i = \sum_{j=1}^{Q}(c_j^i - d_j^i) $$ $c_j^i = c_j(X_i)$ is the actual output of the network on xi on the j-th class.
$d^i_j$ is the desired output of $X_i$ on the j-th class. 取值为1,-1
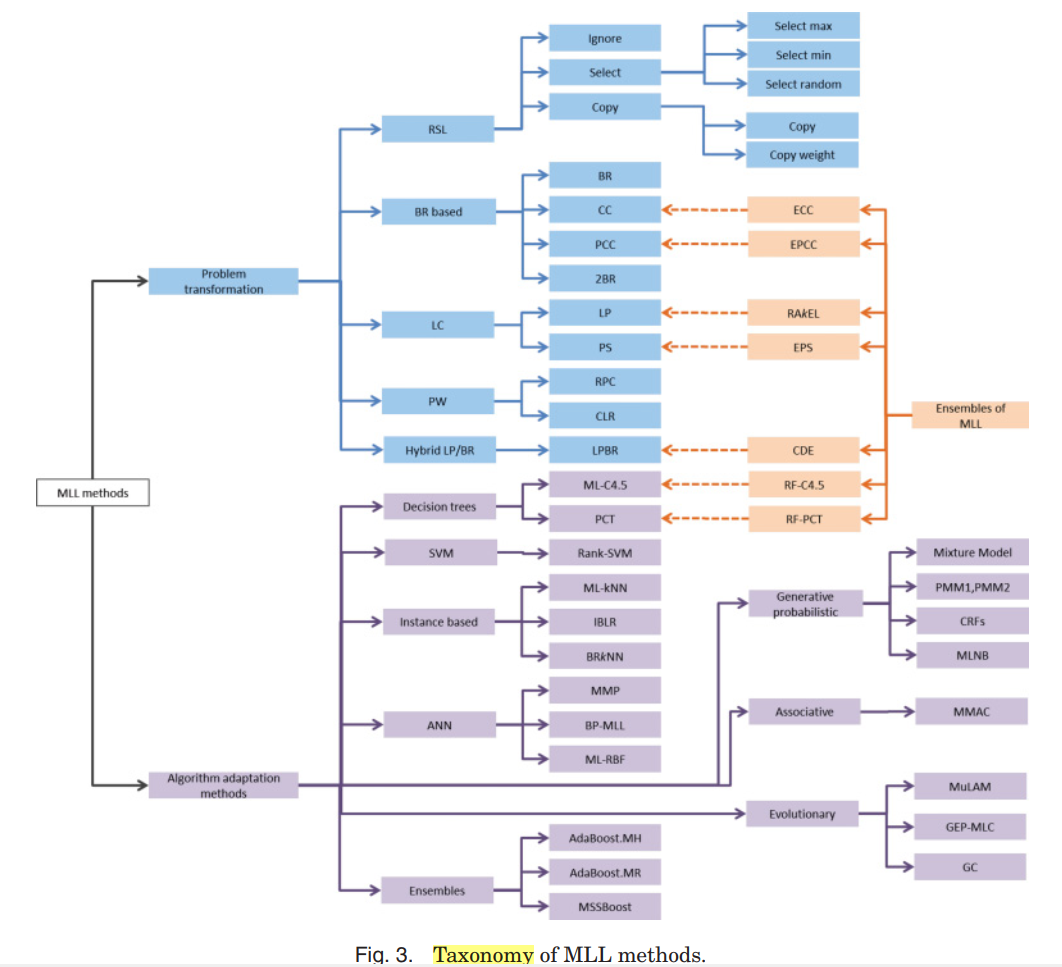
this article presents an up-to-date tutorial about multilabel learning that introduces the paradigm and describes the main contributions developed. evaluation measures, fields of application, trending topics, and resources are also presented.
《2011 [Skat] Policy Based Inference in Trick-Taking Card Games 》 【博士论文】Jeffrey Richard Long
1 2 3 4 5 6 7 8 9 10
三个贡献
【4】专家级计算机SKAT-AI (组合游戏树搜索、状态评估和隐藏信息推理三个核心方面的组合来实现这一性能) 《M. Buro, J. Long, T. Furtak, and N. R. Sturtevant. Improving state evaluation, inference, and search in trick-based card games. In Proceedings of the 21st International Joint Conference on Artificial Intelligence (IJCAI2009), 2009. 》
【26】次优解决方案方法的框架 《 J. Long, N. R. Sturtevant, M. Buro, and T. Furtak. Understanding the success of perfect information monte carlo sampling in game tree search. In Proceedings of the 24th AAAI Conference on Artificial Intelligence (AAAI2010), 2010.》
【27】一种简单的自适应对手实时建模技术。 《 J. R. Long and M. Buro. Real-time opponent modelling in trick-taking card games. In Proceedings of the 22nd International Joint Conference on Artificial Intelligence (IJCAI2011), page To appear, 2011. 》
介绍Best Defense Model的构建(三个假设)【Contract Bridge】
对手(Miner)是完全信息的,我们(Maxer)是非完全
对手在Maxer选择之后play
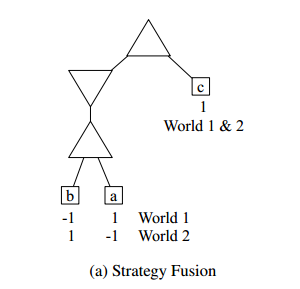
Maxer采用纯策略,不适用融合策略
this results in an algorithm for solving the best defense form of a game which frank and basin term exhaustive strategy minimisation(穷举策略最小化).
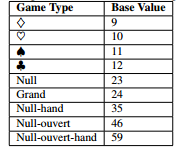
SKAT:
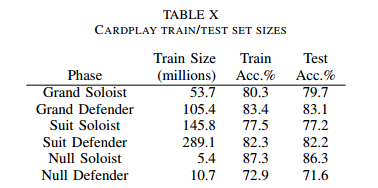
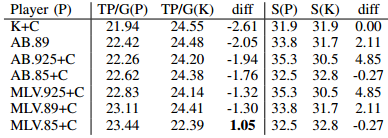
DDS(Double-Dummy Solver ): MC simulation + ab-search
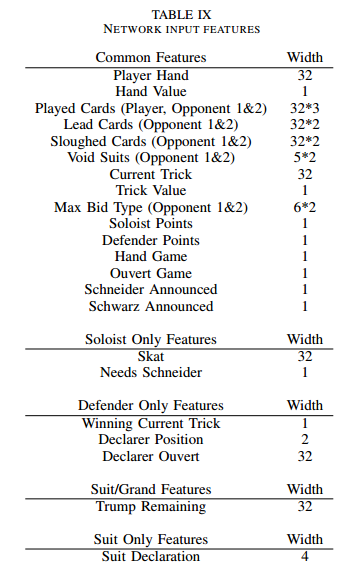
features: Suit length $\in {0…7}$: The number of cards held in each of the four suits, }~♠|. Jack constellaion $ \in {0…15}$: The exact configuration of the player’s Jacks. Ace count $ \in {0…4}$: Number of Aces held. High card count $ \in {0…8}$: Number of Aces and Tens held. King Queen count $ \in {0…8}$: Number of Kings and Queens held. Low card count $ \in {0…12}$: Number of 7s, 8s and 9s held.
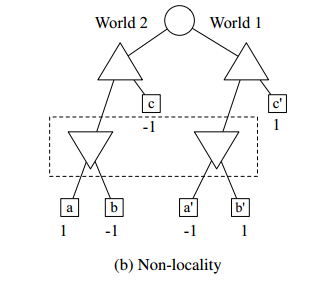
众所周知,PIMC搜索作为一种算法不会产生纳什均衡或任何其它具有可证明的游戏理论属性的策略。Frank and Basin 是第一个精确地识别并形式化这一天然的错误, pimc搜索的本身缺陷导致的[9]。从根本上说,这些错误是由于游戏的完美信息变体的重复播放不能真实地捕捉原始游戏的所有不完美的信息方面而发生的。
determines the probability that the game will favor a particular player over the other. with very high or very low bias, we expect there to be large, homogeneous sections of the game, and as long as a game-playing algorithm can find these large regions, it should perform well in such games.
inference, as we have taken it, is the problem of mapping a series of observed actions taken by a player into a probability distribution over that player’s private information. a reasonable and intuitive question to ask is whether inference is nothing more than an attempt to build a model of a particular opponent. certainly, since inference attempts to derive meaning from an opponent’s actions, it is inherently dependent on the opponent’s policy for choosing those actions — in other words, her strategy. and if the opponent does not act as we expect, could our inferences cause us to make more mistakes by misleading us?
Box(G, H, σ): Game + History -> a set of possible states S, a strategy profile σ for all players in Game G; 生成P(s) for all $s \in S$ 校正后验概率分布, 在所有可能的状态S上。
6.3 Inference in PIMC Search
6.3.2 Considerations in inference Design
PIMC search would exhaustively examine all worlds, and weigh the result of each world’s analysis by the world’s probability. When the state space is still large, this approach is not feasible if the analysis of each world is time-consuming, as is the case when using alpha-beta search on perfect information worlds.
PAC(Probably Approximately Correct,高度近似正确)学习理论是比较成熟的样本效率分析理论体系,PAC理论又称PAC-MDP理论,主要分析在一个无限长的学习过程中学习算法选择非最优动作的次数,称为该算法的样本复杂度。如果一个算法的样本复杂度有上界,那就说明该算法无论面对如何困难的学习问题,都能在无限长的学习过程中只犯有限次的“失误”,从而间接说明算法的样本效率较高。除PAC外,还要Regret分析、KWIK分析、平均损失分析等,从不同指标分析了一些系统性探索策略的样本效率,指出了它们的有效性。
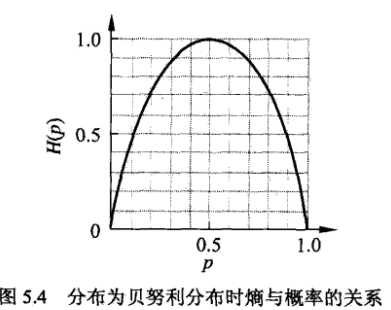




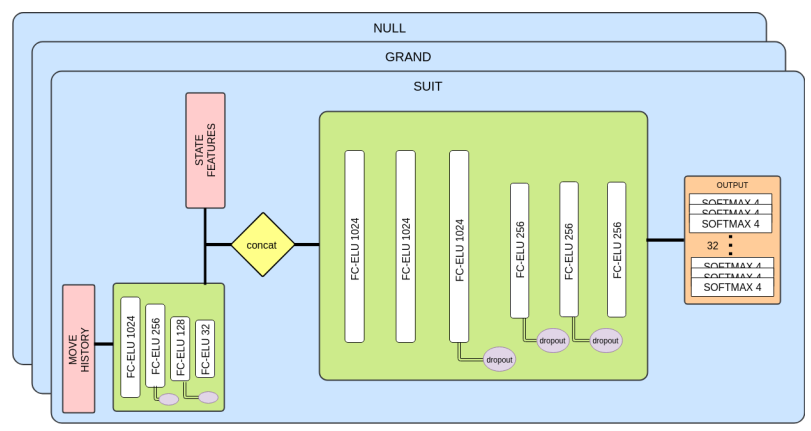
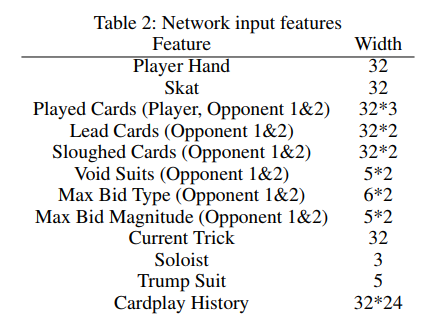
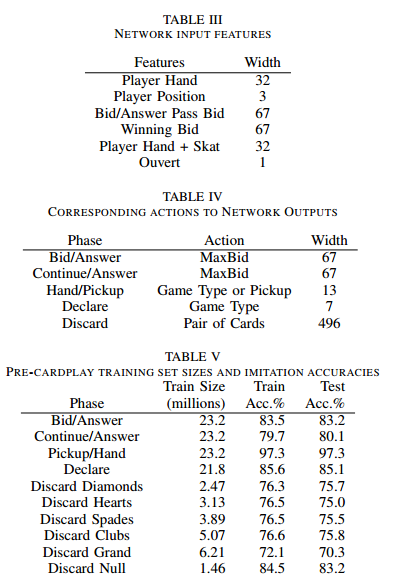
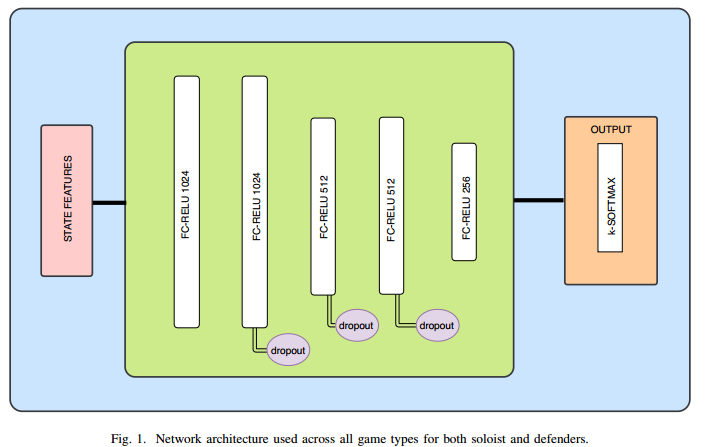

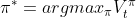 。
。