#!/bin/bash # Source ROS setup script source /opt/ros/noetic/setup.bash # Source workspace setup script source ~/catkin_ws/devel/setup.bash # Set ROS Master URI # Replace 'localhost' with your ROS Master's IP if it's on a different machine export ROS_MASTER_URI=http://localhost:11311 # Set ROS Hostname # Replace 'localhost' with this machine's IP if this machine is not the ROS Master export ROS_HOSTNAME=localhost # Set ROS IP # Replace 'localhost' with this machine's IP export ROS_IP=localhost # Set Gazebo Plugin Path export GAZEBO_PLUGIN_PATH=/opt/ros/noetic/lib:$GAZEBO_PLUGIN_PATH
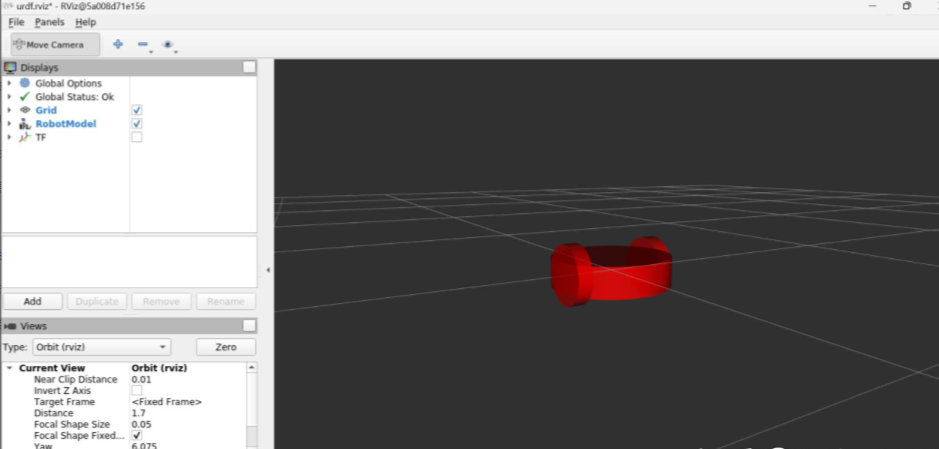
<!-- Base Link --> <linkname="base_link"> <visual> <geometry> <cylinderlength="0.1"radius="0.2"/> </geometry> </visual> <collision> <geometry> <cylinderlength="0.1"radius="0.2"/> </geometry> </collision> <inertial> <massvalue="10"/> <inertiaixx="0.1"ixy="0"ixz="0"iyy="0.1"iyz="0"izz="0.1"/> </inertial> </link>
<!-- Left Wheel --> <jointname="left_wheel_joint"type="continuous"> <parentlink="base_link"/> <childlink="left_wheel"/> <originxyz="0 0.15 0"rpy="1.57079632679 0 0"/><!-- Rotate the wheel to be perpendicular to the ground --> <axisxyz="0 0 1"/> </joint> <linkname="left_wheel"> <visual> <geometry> <cylinderlength="0.05"radius="0.1"/> </geometry> </visual> <collision> <geometry> <cylinderlength="0.05"radius="0.1"/> </geometry> </collision> <inertial> <massvalue="1"/> <inertiaixx="0.025"ixy="0"ixz="0"iyy="0.025"iyz="0"izz="0.025"/> </inertial> </link>
<!-- Right Wheel --> <jointname="right_wheel_joint"type="continuous"> <parentlink="base_link"/> <childlink="right_wheel"/> <originxyz="0 -0.15 0"rpy="1.57079632679 0 0"/><!-- Rotate the wheel to be perpendicular to the ground --> <axisxyz="0 0 1"/> </joint> <linkname="right_wheel"> <visual> <geometry> <cylinderlength="0.05"radius="0.1"/> </geometry> </visual> <collision> <geometry> <cylinderlength="0.05"radius="0.1"/> </geometry> </collision> <inertial> <massvalue="1"/> <inertiaixx="0.025"ixy="0"ixz="0"iyy="0.025"iyz="0"izz="0.025"/> </inertial> </link>
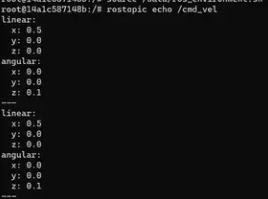
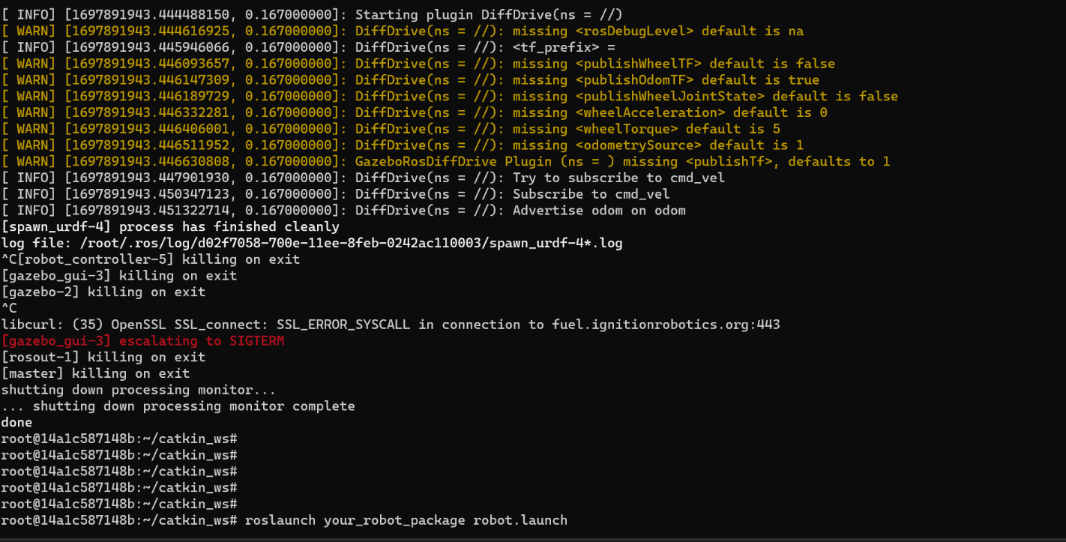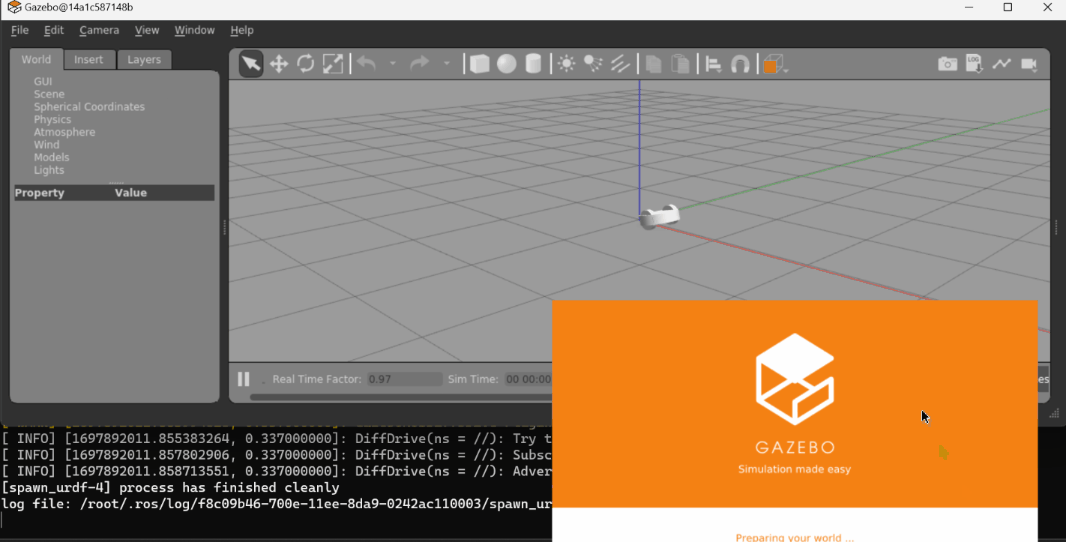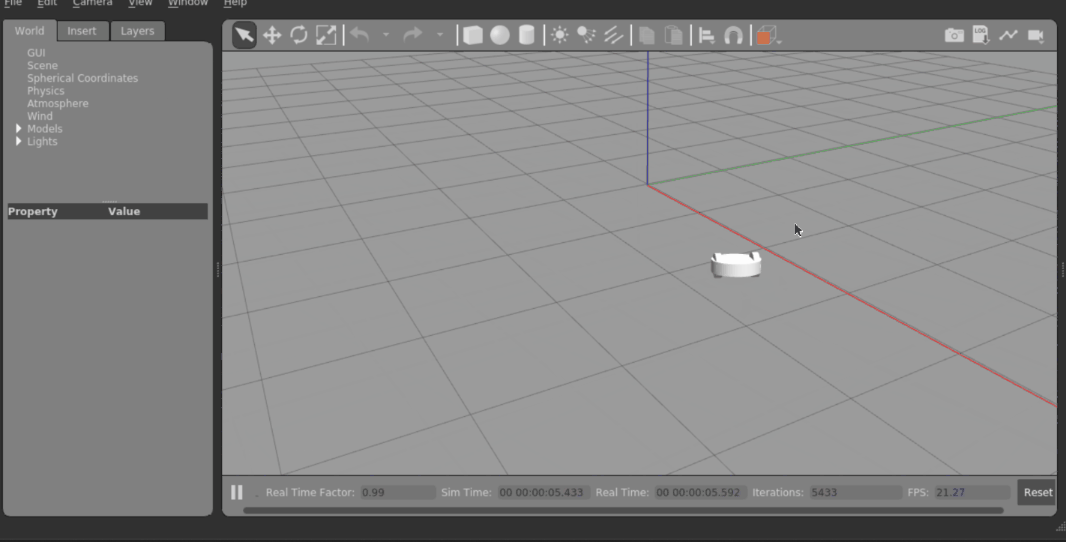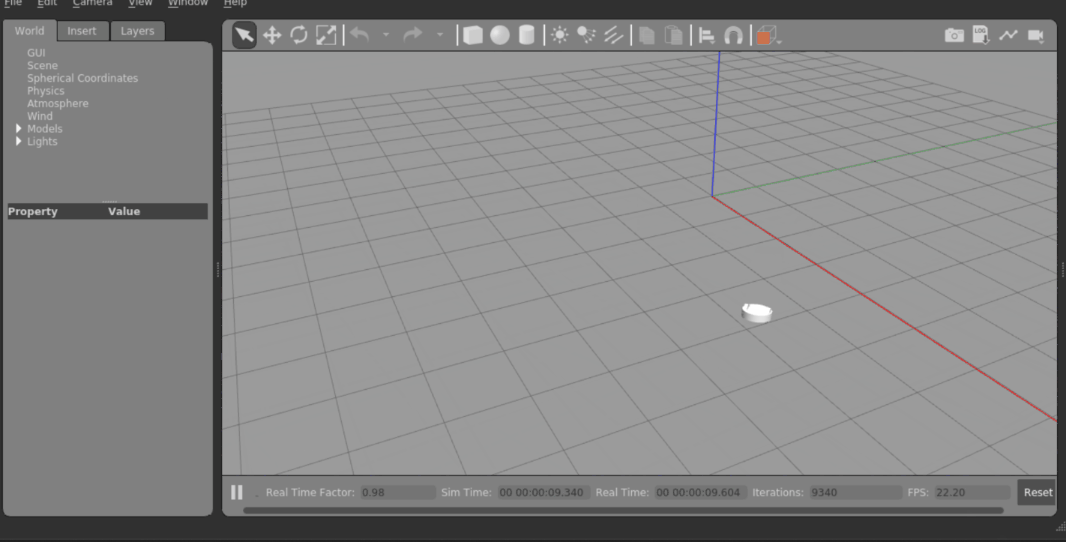
<gazebo> <pluginname="gazebo_ros_diff_drive"filename="libgazebo_ros_diff_drive.so"> <updateRate>100.0</updateRate> <leftJoint>left_wheel_joint</leftJoint> <rightJoint>right_wheel_joint</rightJoint> <wheelSeparation>0.3</wheelSeparation><!-- This should be the distance between your wheels --> <wheelDiameter>0.2</wheelDiameter><!-- This should be the diameter of your wheels --> <torque>20</torque><!-- You may need to adjust this value --> <commandTopic>cmd_vel</commandTopic> <odometryTopic>odom</odometryTopic> <odometryFrame>odom</odometryFrame> <robotBaseFrame>base_link</robotBaseFrame> </plugin> </gazebo>
<launch> <!-- Load the URDF into the ROS Parameter Server --> <paramname="robot_description"textfile="$(find your_robot_package)/urdf/two_wheel_robot.urdf" />
<!-- Launch Gazebo with the robot model --> <includefile="$(find gazebo_ros)/launch/empty_world.launch"> <argname="world_name"value="worlds/empty.world"/> <argname="paused"value="false"/> </include>
#!/bin/bash # Source ROS setup script source /opt/ros/noetic/setup.bash # Source workspace setup script source ~/catkin_ws/devel/setup.bash # Set ROS Master URI # Replace 'localhost' with your ROS Master's IP if it's on a different machine export ROS_MASTER_URI=http://localhost:11311 # Set ROS Hostname # Replace 'localhost' with this machine's IP if this machine is not the ROS Master export ROS_HOSTNAME=localhost # Set ROS IP # Replace 'localhost' with this machine's IP export ROS_IP=localhost # Set Gazebo Plugin Path export GAZEBO_PLUGIN_PATH=/opt/ros/noetic/lib:$GAZEBO_PLUGIN_PATH
from argparse import ArgumentParser from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig import deepspeed import torch from utils import DSPipeline
inputs = [ "DeepSpeed is a machine learning framework", "He is working on", "He has a", "He got all", "Everyone is happy and I can", "The new movie that got Oscar this year", "In the far far distance from our galaxy,", "Peace is the only way" ]
# Sample prompts. prompts = [ "Hello, my name is", "The president of the United States is", "The capital of France is", "The future of AI is", ] # Create a sampling params object. sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# Create an LLM. llm = LLM(model="facebook/opt-125m") # Generate texts from the prompts. The output is a list of RequestOutput objects # that contain the prompt, generated text, and other information. outputs = llm.generate(prompts, sampling_params) # Print the outputs. for output in outputs: prompt = output.prompt generated_text = output.outputs[0].text print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")