[toc]
人体解析数据集 -human parsing
| 开源 | 项目 | |||
|---|---|---|---|---|
| LIP | [open] | 2017 | SS-NAN | Single Person http://hcp.sysu.edu.cn/lip https://github.com/Engineering-Course/LIP_SSL |
| CIHP | [open] | 2018 | http://sysu-hcp.net/lip/overview.php | |
| ATR | [open] | 2015 | ||
| Chictopia10k | Co-CNN | human parsing “Human parsing with contextualized convolutional neural network.” ICCV’15, | ||
| VIP | [open] | Video Multi-Person Human Parsing | ||
| MHP | [open] | 2017 | https://lv-mhp.github.io/dataset | |
| Person-Part | [open] | 2014 | http://www.stat.ucla.edu/~xianjie.chen/pascal_part_dataset/pascal_part.html | |
| Fashionista | 2012 | |||
| DeepFashion | ||||
| VITON | 2017 | VITON | 闭源;16,253 pairs | |
| MPV | 2019 | MG-VTON | 已经闭源 |
[引文1]人体解析-human parsing
人体解析-human parsing
研究目标与意义
人体解析是指将在图像中捕获的人分割成多个语义上一致的区域,例如, 身体部位和衣物。作为一种细粒度的语义分割任务,它比仅是寻找人体轮廓的人物分割更具挑战性。 人体解析对于以人为中心的分析非常重要,并且具有许多工业上的应用,例如,虚拟现实,视频监控和人类行为分析等等。
Fashionista 数据集
论文:Parsing Clothing in Fashion Photographs
论文地址:http://www.tamaraberg.com/papers/parsingclothing.pdf

Person-part 数据集
论文:Detect What You Can: Detecting and Representing Objects using Holistic Models and Body Parts
论文地址:http://www.stat.ucla.edu/~xianjie.chen/paper/Chen14cvpr.pdf
数据集地址:http://www.stat.ucla.edu/~xianjie.chen/pascal_part_dataset/pascal_part.html

ATR 数据集
论文:Deep Human Parsing with Active Template Regression
论文地址:https://arxiv.org/pdf/1503.02391.pdf

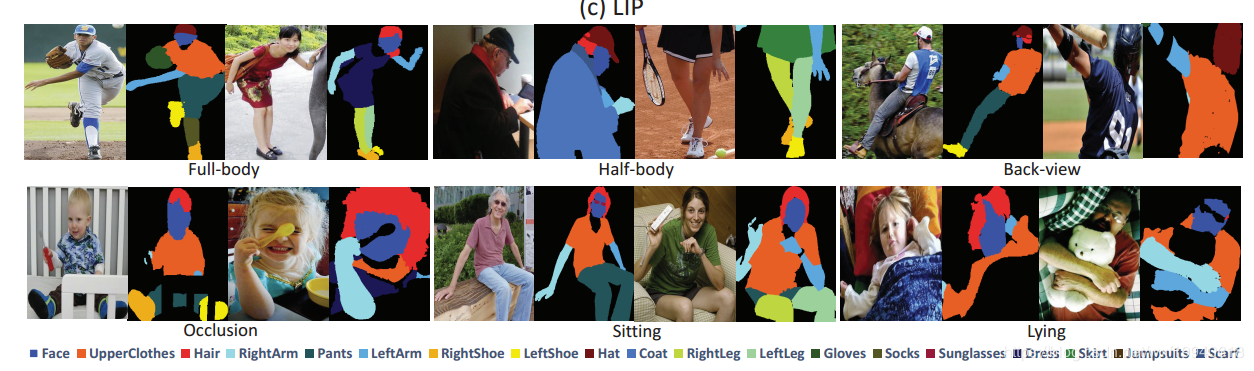
LIP数据集
论文:Look into Person: Self-supervised Structure-sensitive Learning and A New Benchmark for Human Parsing
论文地址:https://arxiv.org/pdf/1703.05446.pdf
数据集地址:http://hcp.sysu.edu.cn/lip
代码地址:https://github.com/Engineering-Course/LIP_SSL
MHP数据集
论文:Multi-Human Parsing in the Wild
论文地址:https://arxiv.org/pdf/1705.07206.pdf
数据集地址:https://lv-mhp.github.io/dataset

CIHP 数据集
论文:Instance-level Human Parsing via Part Grouping Network
论文地址:http://openaccess.thecvf.com/content_ECCV_2018/papers/Ke_
Gong_Instance-level_Human_Parsing_ECCV_2018_paper.pdf
数据集地址:http://sysu-hcp.net/lip/overview.php

DeepFashion:
DeepFashion [38] only have the pairs of the same person in different poses but do not have the image of clothes.
人体解析近年论文:
1 | 2018-ECCV-Mutual Learning to Adapt for Joint Human Parsing and Pose Estimation |
[引文2] Dataset Overview [中山大]
1. Overview
Look into Person (LIP) is a new large-scale dataset, focus on semantic understanding of person. Following are the detailed descriptions.
1.1 Volume
The dataset contains 50,000 images with elaborated pixel-wise annotations with 19 semantic human part labels and 2D human poses with 16 key points.
1.2 Diversity
The annotated 50,000 images are cropped person instances from COCO dataset with size larger than 50 * 50.The images collected from the real-world scenarios contain human appearing with challenging poses and views, heavily occlusions, various appearances and low-resolutions. We are working on collecting and annotating more images to increase diversity.
2. Download
2.1 Single Person
We have divided images into three sets. 30462 images for training set, 10000 images for validation set and 10000 for testing set.The dataset is available at Google Drive and Baidu Drive.
Besides we have another large dataset mentioned in “Human parsing with contextualized convolutional neural network.” ICCV’15, which focuses on fashion images. You can download the dataset including 17000 images as extra training data.
2.2 Multi-Person
To stimulate the multiple-human parsing research, we collect the images with multiple person instances to establish the first standard and comprehensive benchmark for instance-level human parsing. Our Crowd Instance-level Human Parsing Dataset (CIHP) contains 28280 training, 5000 validation and 5000 test images, in which there are 38280 multiple-person images in total.
You can also downlod this dataset at Google Drive and Baidu Drive.
2.3 Video Multi-Person Human Parsing
VIP(Video instance-level Parsing) dataset, the first video multi-person human parsing benchmark, consists of 404 videos covering various scenarios. For every 25 consecutive frames in each video, one frame is annotated densely with pixel-wise semantic part categories and instance-level identification. There are 21247 densely annotated images in total. We divide these 404 sequences into 304 train sequences, 50 validation sequences and 50 test sequences.
You can also downlod this dataset at OneDrive and Baidu Drive.
- VIP_Fine: All annotated images and fine annotations for train and val sets.
- VIP_Sequence: 20-frame surrounding each VIP_Fine image (-10 | +10).
- VIP_Videos: 404 video sequences of VIP dataset.
2.4 Image-based Multi-pose Virtual Try On
MPV (Multi-Pose Virtual try on) dataset, which consists of 35,687/13,524 person/clothes images, with the resolution of 256x192. Each person has different poses. We split them into the train/test set 52,236/10,544 three-tuples, respectively.
You can also downlod this dataset at Google Drive or Baidu Drive.
Baidu Drive extract password:
f6i2
引文
引文1:https://blog.csdn.net/wxf19940618/article/details/83661891