[toc]
CP-VTON
1807.07688
https://github.com/sergeywong/cp-vton
- 解决了在真实的虚拟试穿情况下面临的在大空间变形时的服装细节的保留问题。
- 通过GMM模块整合了全学习的TPS,用来获得更健壮和更强大的对齐图像。
- 在给定对齐图像的基础上,通过Try-On模块来动态合并渲染结果与变形结果。
- CP-VTON网络的性能已经在Han等人收集的数据集上进行了证明。
Motivation:
“在保留目标服装细节的情况下将服装转换为适合目标人物的体型”
几何匹配模块GMM,将目标服装转换为适合目标人物体型的形状
Try-On模块将变形后的服装与人物整合并渲染整合后的图像
架构
alignment Network 对齐网络
a single pass generative framework 单通道生成框架
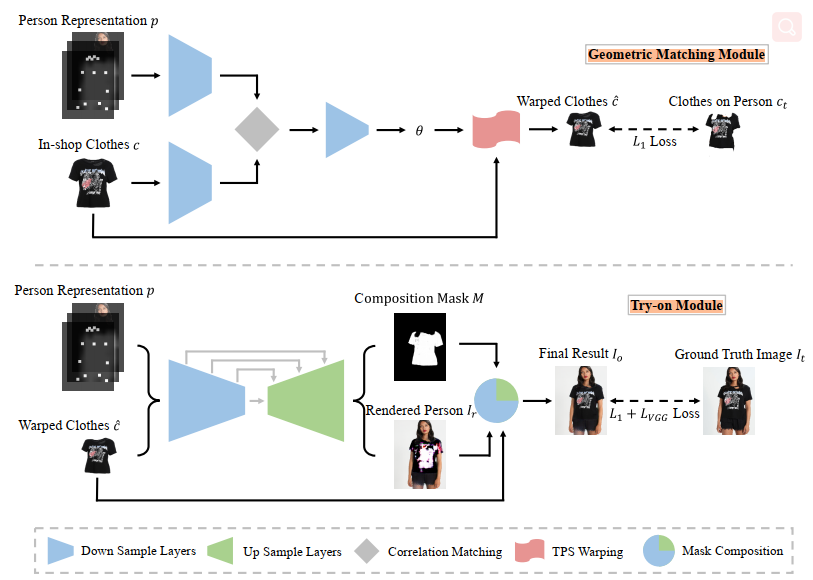
GMM模型 几何匹配模块
Geometric Matching Moduel
extracting network:
IN_cloth-agnostic_person [h, w, 22] (64, 128, 256, 512, 512 )
IN_in_shop_cloth [h, w, 3] (64, 128, 256, 512, 512 )
correlation Matching:
- 矩阵变换
regression network:
- CNN (512, 256, 128, 64 )
TPS transformation:
- TPS 理解
LOSS
- l1_loss
生成文件
- warped_cloth
- warped_mask

Tron-ON Model
GAN:
- 12-layer UNet(输出Render 和 composite)
MaskComposition:
- Mask Composition 实现:直接使用 cloth * m_composite + p_rendered * (1 - m_composite)
LOSS
- L1loss_tryon_im
- Lvgg_tryon_im
- L1loss_composition
训练时的Vision

数据转换
原始数据及格式:
image
image_parse
warped_img 【处理image_parse数据二次处理后得到】
Pose【通过OpenPose对refer image处理得到 keypoint文件,二次处理】
Cloth
Cloth-Mask
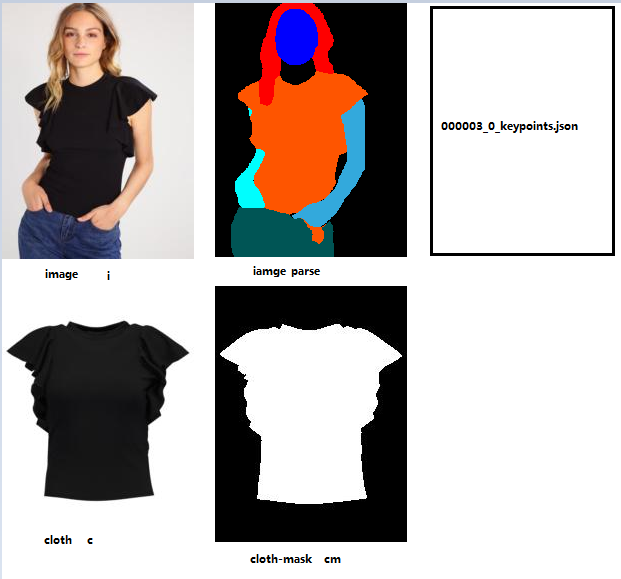
转换后数据格式:
cloth-agnostic_person(22通道):
- Pose heatmap: an 18-channel 每个通道对应一个人体姿势关键点(绘制为11×1111×11的白色矩形)。
- Body shape: a 1-channel 一个1通道的 blurred binary mask 特征图,能够粗糙地包括人体的不同部位。
- Reserved regions: an RGB image 一个包括面部和头发的RGB图像,用来维持人物身份(保证生成的是同一个人)。
1 | shape <- image-parse |
数据转换-难点理解:
0、VITON
解析VITON数据集合得到的数据有:
1 | 'viton_train_pairs.txt': imname, cloth_name |
human_colormap.mat 数据集
1、keypoints文件生成
首先原始数据取自VITON
CP-VTON use the json format for pose info as generated by OpenPose.
我们使用[OpenPose](https://github.com/cmu-computing - lab/openpose)生成json格式的pose信息。
2、Image-Parse文件生成
- LIP-SSL得到.mat文件, 保存到/VITON/segment/
- 转换VITON的human_colormap.mat文件得到
1 | function image_parse() |
3、Cloth-Mask文件生成
cloth 文件生成
1 | function conver_data() |
4、Body shape裁剪 [训练时转换]
5、保留区域的转换 [训练时转换]
6、Pose heatmap 生成
ViTON- 采用OpenPose开源库,直接从源文件img生成。