AI生成骨骼动画
动作生成(miHoYo)
PFNN 动作合成经典之作-PFNN
NSM
- deformation算法
- 行为/运动控制,规划,交互方向
[TOC]
1- Ubuntu16 ()
2- Ubuntu18 (驱动版本太低,无法安装成功)
驱动410安装: 为了与UbuntuServer版本服务器一致,在18.04最新桌面版上安装410驱动,但是一直报内核报错,尝试了所有的安装方式,都无法顺利安装成功
网上也没有类似的问题,最终准备换440的驱动安装,安装成功
CUDA 驱动对应版本 https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
CUDA 下载 https://developer.nvidia.com/cuda-toolkit-archive
| CUDA Toolkit | Minimum Required Driver Version for CUDA Minor Version Compatibility* | |
|---|---|---|
| Linux x86_64 Driver Version | Windows x86_64 Driver Version | |
| CUDA 12.x | >=525.60.13 | >=528.33 |
| CUDA 11.8.x CUDA 11.7.x CUDA 11.6.x CUDA 11.5.x CUDA 11.4.x CUDA 11.3.x CUDA 11.2.x CUDA 11.1.x | >=450.80.02 | >=452.39 |
| CUDA 11.0 (11.0.3) | >=450.36.06** | >=451.22** |
\
| CUDA 12.4 GA | >=550.54.14 | >=551.61 |
|---|---|---|
| CUDA 12.3 Update 1 | >=545.23.08 | >=546.12 |
| CUDA 12.3 GA | >=545.23.06 | >=545.84 |
| CUDA 12.2 Update 2 | >=535.104.05 | >=537.13 |
| CUDA 12.2 Update 1 | >=535.86.09 | >=536.67 |
| CUDA 12.2 GA | >=535.54.03 | >=536.25 |
| CUDA 12.1 Update 1 | >=530.30.02 | >=531.14 |
| CUDA 12.1 GA | >=530.30.02 | >=531.14 |
| CUDA 12.0 Update 1 | >=525.85.12 | >=528.33 |
| CUDA 12.0 GA | >=525.60.13 | >=527.41 |
| CUDA 11.8 GA | >=520.61.05 | >=520.06 |
| CUDA 11.7 Update 1 | >=515.48.07 | >=516.31 |
| CUDA Toolkit | Linux x86_64 Driver Version | Windows x86_64 Driver Version |
|---|---|---|
| CUDA 11.7 GA | >=515.43.04 | >=516.01 |
| CUDA 11.6 Update 2 | >=510.47.03 | >=511.65 |
| CUDA 11.6 Update 1 | >=510.47.03 | >=511.65 |
| CUDA 11.6 GA | >=510.39.01 | >=511.23 |
| CUDA 11.5 Update 2 | >=495.29.05 | >=496.13 |
| CUDA 11.5 Update 1 | >=495.29.05 | >=496.13 |
| CUDA 11.5 GA | >=495.29.05 | >=496.04 |
| CUDA 11.4 Update 4 | >=470.82.01 | >=472.50 |
| CUDA 11.4 Update 3 | >=470.82.01 | >=472.50 |
| CUDA 11.4 Update 2 | >=470.57.02 | >=471.41 |
| CUDA 11.4 Update 1 | >=470.57.02 | >=471.41 |
| CUDA 11.4.0 GA | >=470.42.01 | >=471.11 |
| CUDA 11.3.1 Update 1 | >=465.19.01 | >=465.89 |
| CUDA 11.3.0 GA | >=465.19.01 | >=465.89 |
| CUDA 11.2.2 Update 2 | >=460.32.03 | >=461.33 |
| CUDA 11.2.1 Update 1 | >=460.32.03 | >=461.09 |
| CUDA 11.2.0 GA | >=460.27.03 | >=460.82 |
| CUDA 10.2.89 | >= 440.33 | >= 441.22 |
| CUDA 10.1 (10.1.105 general release, and updates) | >= 418.39 | >= 418.96 |
| CUDA 10.0.130 | >= 410.48 | >= 411.31 |
| CUDA 9.2 (9.2.148 Update 1) | >= 396.37 | >= 398.26 |
| CUDA 9.2 (9.2.88) | >= 396.26 | >= 397.44 |
| CUDA 9.1 (9.1.85) | >= 390.46 | >= 391.29 |
| CUDA 9.0 (9.0.76) | >= 384.81 | >= 385.54 |
| CUDA 8.0 (8.0.61 GA2) | >= 375.26 | >= 376.51 |
| CUDA 8.0 (8.0.44) | >= 367.48 | >= 369.30 |
| CUDA 7.5 (7.5.16) | >= 352.31 | >= 353.66 |
| CUDA 7.0 (7.0.28) | >= 346.46 | >= 347.62 |
https://developer.nvidia.com/rdp/cudnn-download
| GPU | Compute Capability |
|---|---|
| GeForce RTX 3070 | 8.6 |
| GeForce RTX 3060 | 8.6 |
Pog
[toc]
Abstract游戏作为人工智能发展的基准由来已久。最近,使用搜索和学习的方法在一组完美信息博弈中表现出了很强的表现,而使用博弈论推理和学习的方法在特定的不完美信息扑克变种中表现出了很强的表现。我们介绍了一种将引导搜索、自玩学习和博弈论推理相结合的通用算法Player of Games。players of Games是第一个在大型完备和不完备信息博弈中取得较强经验性能的算法—–这是向真正适用于任意环境的通用算法迈出的重要一步。我们证明了 Player of Games 是健全的,随着可用计算时间和近似容量的增加,收敛到完美的游戏。 Player of Games在国际象棋和围棋方面取得了强劲的表现,在单挑无限注德州扑克 中击败了最强大的公开智能体(Slumbot),并在苏格兰场击败了最先进的Agent。 一个不完美的信息游戏,说明了引导搜索、学习和博弈论推理的价值。
在 1950 年代,Arthur L. Samuel 开发了一个跳棋程序,该程序采用了现在所谓的极小极大搜索(带有 alpha-beta 剪枝)和“(死记硬背)rote learning”,通过自我对弈来改进其评估功能 [62]。这项调查启发了许多其他人,最终塞缪尔共同创立了人工智能领域 [61] 并普及了“机器学习”一词。几年前,世界目睹了一个计算机程序在围棋比赛中击败了一位长期存在的专业人士 [70]。 AlphaGo 还结合了学习和搜索。许多类似的成就发生在这两者之间,例如super-human象棋的竞赛导致DeepBlue[17],TD-Gammon通过自我对弈自学在西洋双陆棋(Backgammon )中发挥大师级的表现[82],延续了将游戏作为该领域主流进程的典型标志。
在整个成功的过程中,有一个重要的共同元素:专注于单一游戏。确实,深蓝不会下围棋,塞缪尔的程序也不会下国际象棋。同样,AlphaGo 也不会下国际象棋;然而,它的继任者 AlphaZero [71] 能够并且做到了。 AlphaZero 证明了使用 AlphaGo 方法的简化,并且以最少的人类知识,单个算法可以掌握三种不同的完美信息游戏。尽管取得了这一成功,但 AlphaZero 不能玩扑克,而且对不完美信息游戏的扩展尚不清楚。 与此同时,实现超人类扑克人工智能的方法也大不相同。强大的扑克游戏依赖于博弈论推理来确保有效隐藏私人信息。最初,超人类扑克代理人主要基于计算近似纳什均衡offline [37]。然后添加了搜索,并证明是在无限变体中取得超人成功的关键因素 [55, 11, 12]。其他大型游戏的训练也受到博弈论推理和搜索的启发,例如 Hanabi [4, 44]、The Resistance [69]、Bridge [49]、AlphaStar [83] 和(无新闻)外交【 (no-press) Diplomacy】 [ 2, 25, 3]。然而,尽管取得了显着的成功:每一次进步仍然是在一个单一的游戏中,明确使用特定领域的知识和结构来实现强大的性能。
在本文中,我们介绍了游戏玩家 (PoG),这是一种新算法,它概括了可以使用自我对弈学习、搜索和博弈论推理实现强大性能的游戏类别。 PoG 使用growing-tree反事实后悔最小化(GT-CFR):一种随时局部搜索,非均匀地构建子博弈,将树扩展到最相关的未来状态,同时迭代地改进价值和策略。此外,PoG 采用合理的自我对弈:一种学习过程,该过程使用博弈结果和应用于先前搜索中出现的情况的递归子搜索来训练价值和策略网络。
Player of Games 是第一个在具有完美和不完美信息的挑战领域中实现强大性能的算法——这是迈向可以在任意环境中学习的真正通用算法的重要一步。传统搜索的应用在不完美信息博弈中存在众所周知的问题 [61]。尽管最近在不完美信息游戏中的合理搜索取得了进展 [55, 10, 84],但评估仍然集中在单个领域(例如扑克)。 Player of Games 填补了这一空白,它使用单一算法,以及很少领域特定知识。它在这些根本不同的游戏类型中的搜索是合理的 [84]:通过重新求解子游戏,以在在线游戏期间保持一致,保证找到一个近似的纳什均衡,并在可计算可利用性的小博弈中,在实践中产生较低的可利用性。 PoG 在四种不同的游戏中表现出强大的性能:两种完全信息(国际象棋和围棋)和两种不完全信息(扑克和苏格兰场)。最后,与扑克不同的是,苏格兰场的搜索范围和游戏长度明显更长,需要长期规划。
我们从必要的背景和符号开始来描述主要算法和结果。我们在第 5 节中将我们的算法与其他方法联系起来。在这里,我们简要介绍了必要的概念,这些概念基于因子观察随机博弈 (FOSG) 形式主义。有关形式主义的更多详细信息,请参见 [40, 64]。
两个玩家之间的博弈从特定的世界状态 w^{init}开始,然后进行到后继世界状态 w ∈ W 作为玩家选择动作 a ∈ A 的结果,直到达到最终状态时游戏结束。在任何世界状态 w,我们将使用符号 A(w) ⊆ A 来指代那些在世界状态 w 中可用或合法的动作。在游戏过程中采取的一系列动作称为历史,用 h ∈ H 表示,h^{‘} \subseteq h 表示前缀历史(子序列)。在终端历史 z ⊂ H 处,每个玩家 i 收到一个效用 ui(z)。
信息状态(私有状态)是关于一个玩家的信息的状态。具体来说,玩家 i 的 si ∈ Si 是一组由于缺少信息而无法区分的历史。一个简单的例子是扑克中的一个特定决策点,玩家 i 不知道对手的私人牌;信息状态中的历史仅在决定对手私人卡的机会事件结果上有所不同,因为其他一切都是公共知识。参与者 i 执行策略 πi : Si → Δ(A),其中 Δ(A) 表示动作 A 的一组概率分布。每个参与者的目标是找到最大化他们自己预期效用的策略。
每次玩家采取行动时,每个玩家都会得到一个私人观察 Opriv(i)(w, a, w ) 和一个公开观察 Opub(w, a, w ) 作为应用行动 a 的结果,改变游戏状态w 到 w 。公共状态 spub = spub(h) ∈ Spub 是沿历史 h 遇到的公共观察序列。例如,德州扑克的公开状态由初始公开信息(筹码量和底注)、投注历史和任何公开显示的牌面代表。设 Si(spub) 是给定 spub 的玩家 i 的可能信息状态集合:每个信息状态 si ∈ Si(spub) 与 spub 中的公共观察一致,但具有不同的私人观察序列。例如,在扑克中,信息状态将包含玩家 i 的私人牌。 FOSG 的完整示例见附录 A。
公共信念状态 β = (spub, r),其中范围(或信念)r ∈ ∆(S1(spub))×∆(S2(spub)) 是代表两个参与者的可能信息状态的一对分布spub 中对信息状态的信念。图 1 描述了公共信仰状态的各个组成部分的基本描述。例如,在苏格兰场的游戏中,信息状态对应于逃避者(X 先生)的位置。一个具体的例子如图 2 所示。逃避者的真实位置是隐藏的,但可能是四个不同位置之一,侦探更怀疑逃避者在位置 63,而不是 35、62 或 78。在苏格兰场,r 中的分布之一是点质量,因为侦探没有对 X 先生隐藏任何私人信息。 
Fig2: 在苏格兰场对公共信仰状态的描述:圆圈表示位置,边缘表示交通连接,红色的条表示对X先生所在位置的私人(未透露的)信息状态的beliefs。
假设玩家使用联合策略 π = (π1, π2)。将玩家对玩家 i 的期望效用表示为 ui(π1, π2),将 -i 表示为玩家 i 的对手。最佳响应策略是针对某些 π−i 实现最大效用的任何策略 $$π_i^b:u_i(π_i^b, π_{−i}) = max_{π_i^{‘}} u_i(π^{‘}i, π{−i})$$。当且仅当 π1 是对 π2 的最佳响应且 π2 是对 π1 的最佳响应时,联合策略 π 是纳什均衡。还有近似均衡:当且仅当 ui(πib, π−i) − ui(πi, π−i) ≤ 所有参与者 i 时,π 是 $$\epsilon -Nash$$ 均衡。在两人零和博弈中,纳什均衡是最优的,因为它们最大化了两个玩家的最坏情况效用保证。此外,均衡策略是可以互换的:如果 πA 和 πB 是纳什均衡,那么$(π_1^A, π_2^B)$和 $(π_1^B, π_2^A)$ 也是均衡。因此,代理的目标是计算一种这样的最优(或近似最优)均衡策略。
人工智能领域的第一个主要里程碑是通过受极大极小定理启发的高效搜索技术获得的 [62, 17]。在具有完美信息的两人零和游戏中,该方法使用从当前世界状态 wt 开始的深度限制搜索,以及启发式评估函数来估计超出深度限制的状态值,h(wt+d ) 和博弈论推理来back up(倒推)价值 [38]。研究人员开发了显着的搜索增强功能 [52, 63],极大地提高了性能,得到了 IBM 的超越人类的DeepBlue 国际象棋程序 [17]。
然而,这种经典方法无法在围棋中实现超人类的表现,围棋的分支因子和状态空间复杂度明显高于国际象棋。在 Go [24] 的挑战下,研究人员提出了蒙特卡罗树搜索 (MCTS) [39, 18]。与极小极大搜索不同,MCTS 通过模拟构建树,从一棵以 wt 为根的空树开始,通过添加当前不在树中的模拟轨迹中遇到的第一个状态来扩展树,最后估计从 rollout 到游戏结束的值。 在围棋和其他游戏中MCTS发挥明显更强的作用 [14],在围棋中达到 6 段业余水平。然而,领域知识形式的启发式方法对于实现这些里程碑仍然是必要的。
在 AlphaGo [70] 中,价值函数和策略被合并,最初从人类专家数据中学习,然后通过自我对弈进行改进。深度网络近似值函数,先验策略有助于指导树搜索过程中动作的选择。该方法是第一个在围棋中实现超人类水平的方法 [70]。 AlphaGo Zero 移除了人类数据和围棋特定特征的初始训练 [72]。 AlphaZero 使用最少的领域知识在国际象棋和将棋以及围棋中达到了最先进的性能 [71]。
PoG 与 AlphaZero 一样,使用最少的领域知识将搜索和从自我对弈中学习结合起来。然而,与 MCTS 不同,MCTS 不适用于不完美信息游戏,PoG 的搜索算法基于反事实后悔最小化,并且对于完美和不完美信息游戏都是合理的。
在不完美信息博弈中,由隐藏信息产生的策略选择对于确定每个玩家的预期奖励至关重要。简单地玩太可预测可能会出现问题:在经典的示例游戏石头剪刀布中,玩家唯一不知道的是对手的行动选择,但是这些信息完全决定了他们可以获得的奖励。选择始终进行一个动作(例如rock)的玩家很容易被另一个做出最佳反应(例如paper)的玩家击败。纳什均衡以相等的概率执行每个动作,这将任何特定反策略的收益最小化。类似地,在扑克中,了解对手的牌或他们的策略可以产生显着更高的预期奖励,而在苏格兰场,如果知道玩家当前的位置,则有更高的机会抓住逃避者。在这些示例中,玩家可以利用隐藏信息的任何知识来执行反策略(counter-strategy),从而获得更高的奖励。因此,为了避免被利用,玩家必须以不泄露自己私人信息的方式行事。我们将这种一般行为称为博弈论推理(gametheoretic reasoning),因为它是计算(近似)极小极大优化策略的结果。在过去的 20 年里,博弈论推理对于竞争性扑克 AI 的成功至关重要。
一种计算近似最优策略的算法是反事实后悔最小化(CFR)[86]。 CFR 是一种自我对弈算法,它以最小化长期平均遗憾的方式为每个玩家 i 在每个信息状态 s 上生成策略迭代 $π_i^t(s)$。结果,CFR 在自我博弈中采用的 T次迭代平均策略$\bar{\pi}^{T}$,以 O(1/ T ) 的速率收敛到 $\epsilon-Nash$均衡。在每次迭代 ,为每个动作 a ∈ A(s) 计算 t 、反事实值 v_i(s, a) 和不玩 a 的直接遗憾,$r(s, a) = v_i(s, a) − \sum_{a \in A (s)} π (s, a) v_i(s, a)$被计算并列在一个累积后悔表中,存储 $R^T (s, a) = \sum ^T_{t=1} r^t(s, a)$。使用遗憾匹配 [27] 计算新策略: $π^{t+1}(s) = \frac{[R^t (s,a)]^+}{ \sum_a[R^t(s,a)]^+}$,其中 $[x]^+ = max (x, 0)$,如果所有遗憾都是非正的,则重置为统一值。 CFR+ [79] 是 CFR 的后继者,它在完全解决单挑限注德州扑克游戏中发挥了关键作用,这是迄今为止有待解决的最大的不完美信息游戏 [6]。 CFR+ 的一个主要组成部分是不同的策略更新机制,regret-matching+,它对累积值的定义略有不同:$Q^t(s, a) = (Q^{t−1}(s, a) + r^t(s, a))^+$,和$π^{t+1}(s, a) = \frac{ Q^t(s, a)}{\sum_b Q^t(s, b)}$。 CFR(或 CFR+)的一种常见形式是遍历公共树,而不是经典的扩展形式博弈树。计算反事实值所需的数量,例如每个参与者在他们的策略下达到每个信息状态的概率(称为他们的范围)作为信念(beliefs)被维护。最后,可以使用范围、机会概率和效用(通常更有效 [36])直接评估叶节点。
2.3 不完善信息的搜索、分解和重新求解 纳什均衡和极小极大等解决方案概念是在联合策略(joint policies)上定义的。该政策是在比赛期间确定的。搜索可以被描述为一个过程,它可能会在后续访问相同状态时返回不同的动作分布。在基于搜索的决策中,新的解决方案是在决策时计算的。每个状态可能取决于过去的游戏玩法、时间限制和随机(机会)事件的样本,这引入了重要的微妙之处,例如交叉不同搜索的解决方案兼容性 [84]。 CFR 传统上被用作求解器,通过自我对弈计算整个策略。每次迭代都会遍历整个博弈树,从树中更深的子博弈中的其他值递归计算信息状态的值。假设有人想要针对某个深度 d > 0 的游戏部分制定策略。如果有一个预言机(oracle)来计算深度 d 的值,那么 CFR 的每次迭代都可以运行到深度 d 并查询预言机以返回值。因此,策略在深度 d’ > d 处不可用。通过一组值总结深度 d 以下的策略,这些值可用于重建深度 d 及以上的策略,这是不完美信息游戏分解的基础 [15]。不完美信息博弈中的子博弈是植根于公共状态 s_pub 的博弈。为了使子博弈成为合适的博弈,它与初始信息状态上的置信分布 r 配对,s \in S_i(s_{pub})。这是完美信息博弈中子博弈的严格概括,其中每个公共状态都只有一个信息状态(因此实际上不再是私有的)和一个概率为 1 的信念。 子博弈分解一直是扑克 AI 最新发展的重要组成部分,这些发展可扩展到大型游戏,例如无限注德州扑克 [55、11、12、7]。子博弈分解使局部搜索能够在游戏过程中细化策略,类似于完美信息游戏中的经典搜索算法和传统的贝尔曼式自举来学习价值函数 [55, 69, 85, 7]。具体来说,由参数 θ 表示的反事实价值网络 (CVN) 对价值函数 vθ(β) = {v_i(s_i)}{s_i \in S_i(s{pub})},i∈{1,2} 进行编码,其中 β 包括玩家对信息的信念在 s_pub 公开信息的状态。然后可以使用函数 vθ 代替上面提到的预言机来汇总 s_pub 下子树的值。图 3 显示了使用分解的深度限制 CFR 求解器的示例。  Safe re-solving安全重解是一种技术,它仅根据先前(近似)解的摘要信息生成子博弈策略:玩家的范围和对手的反事实值。这是通过构建具有特定约束的辅助游戏来完成的。辅助博弈中的子博弈策略的生成方式保留了原始解决方案的可利用性保证,因此它们可以替换子博弈中的原始策略。在 [15] 和 [10, Section 4.1] 中可以找到辅助游戏构建的完整示例。 Continual re-solving 连续重求解是经典游戏搜索的一种类似物,适用于不完美信息游戏,它使用安全重求解的重复应用来玩游戏的一集 [55]。它首先解决以游戏开始为根的深度限制博弈树,搜索是解决问题的步骤。随着博弈的进行,对于某个信息状态 si 的每个后续决策,持续的重新求解将通过在 si 重新求解来优化当前策略。与其他搜索方法一样,它使用额外的计算来更彻底地探索玩家遇到的特定情况。 [55] 的连续重求解方法使用了一些扑克的一些属性,这在苏格兰场等其他游戏中是找不到的,因此我们使用了一种更通用的重求解方法,可以应用于更广泛的游戏类别。我们在附录 B.1 中讨论了这个更通用的重新求解变体的细节。
Safe re-solving安全重解是一种技术,它仅根据先前(近似)解的摘要信息生成子博弈策略:玩家的范围和对手的反事实值。这是通过构建具有特定约束的辅助游戏来完成的。辅助博弈中的子博弈策略的生成方式保留了原始解决方案的可利用性保证,因此它们可以替换子博弈中的原始策略。在 [15] 和 [10, Section 4.1] 中可以找到辅助游戏构建的完整示例。 Continual re-solving 连续重求解是经典游戏搜索的一种类似物,适用于不完美信息游戏,它使用安全重求解的重复应用来玩游戏的一集 [55]。它首先解决以游戏开始为根的深度限制博弈树,搜索是解决问题的步骤。随着博弈的进行,对于某个信息状态 si 的每个后续决策,持续的重新求解将通过在 si 重新求解来优化当前策略。与其他搜索方法一样,它使用额外的计算来更彻底地探索玩家遇到的特定情况。 [55] 的连续重求解方法使用了一些扑克的一些属性,这在苏格兰场等其他游戏中是找不到的,因此我们使用了一种更通用的重求解方法,可以应用于更广泛的游戏类别。我们在附录 B.1 中讨论了这个更通用的重新求解变体的细节。
我们现在描述我们的主要算法。 由于 PoG 有多个组件,我们首先分别描述它们,然后在本节末尾描述它们是如何组合的。 为清楚起见,附录 B 中提供了许多细节(包括完整的伪代码)。
PoG 的第一个主要组件是具有参数 θ 的反事实价值与策略网络 (CVPN),如图 4 所示。这些参数表示函数 fθ(β) = (v, p),其中输出 v 是反事实值( 每个玩家的每个信息状态一个),以及先前策略 p,在公共状态 s_pub(h) 中,在某些play历史 h 中,对于acting玩家的每个信息状态一个。 在我们的实验中,我们使用标准的前馈网络和残差网络。 架构的细节在 B.3 节中描述。
生长树 CFR (GT-CFR) 是一种新算法,它在随时间递增的公共博弈树上运行 CFR 变体。 GT-CFR 以初始树 L0 开始,其中包含 β 及其所有子公共状态。 然后 GT-CFR 的每次迭代 t 由两个阶段组成: 1.后悔更新阶段(在3.2.1小节中详细描述)在当前树L^t上运行几个公共树-CFR更新。 2. 扩展阶段(在 3.2.2 小节中详细描述)通过基于模拟的扩展轨迹添加新的公共状态来扩展 L^t,产生一个新的更大的树L^{t+1}。  在报告结果时,我们使用符号 PoG(s, c) 来表示运行 GT-CFR 的 PoG 和 s 次总扩展模拟,以及每个后悔更新阶段的 c 次扩展模拟,因此 GT-CFR 迭代的总数为 [s/\left c \right] 。 例如,PoG(8000, 10) 指的是 8000 次扩展模拟,每次后悔更新(800 次 GT-CFR 迭代)进行 10 次扩展。 c 可以是小数,因此例如 0.1 表示每 10 个后悔更新阶段就有一个新节点。 图 5 描绘了整个 GT-CFR 循环。 我们选择了这个特定的符号来直接比较总拓展模拟, s 与 AlphaZero。
在报告结果时,我们使用符号 PoG(s, c) 来表示运行 GT-CFR 的 PoG 和 s 次总扩展模拟,以及每个后悔更新阶段的 c 次扩展模拟,因此 GT-CFR 迭代的总数为 [s/\left c \right] 。 例如,PoG(8000, 10) 指的是 8000 次扩展模拟,每次后悔更新(800 次 GT-CFR 迭代)进行 10 次扩展。 c 可以是小数,因此例如 0.1 表示每 10 个后悔更新阶段就有一个新节点。 图 5 描绘了整个 GT-CFR 循环。 我们选择了这个特定的符号来直接比较总拓展模拟, s 与 AlphaZero。
后悔更新阶段使用同步更新、后悔匹配+和线性加权策略平均 [79] 在 Lt 上运行公共树 CFR 的 1/c 更新(迭代)。 在公共树叶节点,对置信状态 β 的 CVPN 进行查询,其值 fθ(β’ ) = (v, p) 用作以 β’ 为根的公共子博弈的反事实值的估计。
在扩展阶段,新的公共树节点被添加到 L。搜索统计信息,最初为空,在信息状态 si 上维护,在同一搜索内的所有扩展阶段累积。在每次模拟开始时,信息状态 si 从 βroot 中的信念中采样。然后,从 si 中采样一个世界状态 wroot,以及相关的历史 hroot。根据混合策略选择动作,该策略考虑了学习值(通过 πPUCT(si(h)))以及来自搜索π_{select}(si(h)) = 1/2 πPUCT(s_i(h)) + 1/2 πCFR (s_i(h))的当前活动策略 (πCFR(s_i(h)))。第一个策略由 PUCT [70] 使用反事实值 vi(si, a) 确定,该值由对手在 si 处的到达概率之和的归一化,类似于状态条件动作值,以及从查询中获得的先验策略 p。第二个是 CFR 在 si(h) 的当前政策。一旦模拟遇到信息状态s_i \in s_{pub}使得s_{pub} \notin L,模拟结束,将 spub 添加到 L,并且沿着轨迹期间访问的节点更新访问计数。与 AlphaZero [71] 类似,在一次 GT-CFR 迭代中进行 c 次模拟时,虚拟损失 [68] 被添加到 PUCT 统计数据中。 AlphaZero 总是在迭代结束时扩展单个动作/节点(具有最高 UCB 分数的动作)。完美信息博弈中的最优策略可以是确定性的,因此扩展单个动作/节点就足够了。在不完美信息博弈中,最优策略可能是随机的,对多个动作具有非零概率(这些动作的数量然后被称为支持大小)。游戏中的不确定性水平(就每个公共状态的信息状态而言)与支持大小之间存在直接联系 [66]。换句话说,最优策略可能需要的动作数量是每个公共状态的信息状态数量的函数,我们将这个数字称为最小支持大小 k。因此,PoG 不是扩展单个动作,而是扩展按先验排序的前 k 个动作。然后将与扩展动作对应的所有公共状态添加到树中(连同导致这些公共状态的所有动作)。当 PoG 扩展先前扩展的节点时,由于已经满足最小支持大小要求,因此仅额外扩展单个动作。请注意,对于完美信息游戏,扩展的作用与 AlphaZero 相同,因为支持大小 k = 1,因此添加了具有最高先验的单个动作。
在 GT-CFR 中生长树允许搜索有选择地关注对局部决策很重要的空间部分。 从一棵小树开始,随着时间的推移添加节点在收敛方面没有额外的成本: Theorem 1 定理 1. 令 Lt 为时间 t 的公共树。 假设公共状态永远不会从前瞻树中删除,所以 L^t \subseteq L^{t+1}。 对于任何给定的树 L,让 N (L) 是树的内部:GT-CFR 生成策略的所有非叶子、非终端公共状态。 令 F(L) 是 L 的边界,包含非终端叶子,其中 GT-CFR 使用反事实值的噪声估计。 设 U 是任何两种策略在任何信息状态下反事实值的最大差异,A 是任何信息状态下的最大动作数。 那么,玩家 i 在迭代 T 时的遗憾是有界的: 定理 1 中的遗憾 R^{T,full} 是 GT-CFR 迭代与任何可能策略之间的性能差距。 定理 1 表明GT-CFR 返回的平均策略以 1/√T 的速率收敛于纳什均衡,但由于价值函数中的 e-error 具有一些最小的可利用性。 当使用 GT-CFR 作为持续重新求解中每个重新求解搜索步骤的游戏求解算法时,也没有额外的成本: Theorem 2 定理 2. 假设我们玩了一个使用连续重求解的游戏,有一个初始求解和 D 重求解步骤。每个求解或重新求解步骤使用 e 噪声值函数通过 GT-CFR 的 T 次迭代找到一个近似的纳什均衡,公共状态永远不会从前瞻树中删除,最大内部大小 \sum_{s_{pub} \in N(L^T)} |S_i(S_{pub})|所有前瞻树的边界N ,所有前瞻树的边界大小总和以 F 为界,任何信息集的最大动作数为 A,任何两个策略之间的最大差值为 U 。最终策略的可利用性受(5D + 2) (F + NU \sqrt{A / T } ) 的限制。 定理 2 类似于 [55] 的定理 1,适用于 GT-CFR 并使用更详细的误差模型,该模型可以更准确地描述在近似均衡策略上训练的价值函数。它表明使用 GT-CFR 持续重新求解具有我们可能希望的一般特性:可利用性随着计算时间的增加和价值函数误差的减少而降低,并且不会随着游戏长度的增加而不受控制地增长。定理的证明在附录 E 中给出。
POG通过在每个决策点运行搜索,在自我对弈中生成数据片段。每个情节从对应于游戏开始的初始历史 h0 开始,并产生一系列历史 (h0, h1, · · · )。在时间 t,代理运行本地搜索,然后选择一个动作 at,通过在 ht 处采取动作,从环境中获得下一个历史记录 ht+1。用于训练 CVPN 的数据是通过产生的轨迹和个人搜索收集的。 在生成用于训练 CVPN 的数据时,重要的是在不同公共状态下执行的搜索与由 θ 表示的 CVPN 以及在先前公共状态沿相同轨迹进行的搜索保持一致(例如,两次搜索不应计算两个不同的最优策略)。这是可靠(sound)搜索的关键要求 [15, 55, 84],我们将sound搜索算法在自我播放中生成数据的过程称sound自我播放。 为了实现健全的自我对弈,在数据生成期间执行的搜索,在标准安全解析辅助游戏(如第 2.3 节所述)上运行 GT-CFR。辅助博弈包括在初始决策时对手决定进入子博弈的选项,或取由 fθ(β) 返回的替代值。有关此解析过程的详细构造,请参阅第 B.1 节。
由 GT-CFR 生成的策略和由健全的自我对弈生成的数据的质量关键取决于 CVPN 返回的值。 因此,为了产生高性能搜索和生成高质量数据,估计准确很重要。 在本小节中,我们将描述用于训练 CVPN 的程序。 图 6 总结了该过程。
如第 3.2 节和第 3.3 节所述,情节是由每个玩家从当前公共状态搜索 GT-CFR 生成的。 每次搜索都会从公共树叶节点 β(在图 6 中描绘为粉红色节点)产生许多网络查询。 训练过程通过监督学习改进了 CVPN。 使用基于值目标的 Huber 损失 [32] 训练值,并且策略损失是相对于目标策略的交叉熵。 将价值和策略目标添加到用于同时训练 CVPN 的训练数据的滑动窗口数据集中。 CVPN 在训练期间在参与者上异步更新。
策略目标是根据 3.3 中描述的sound-自我游戏产生的情节主线(在自我游戏中达到的历史)在公共状态开始的搜索组合而成的。具体来说,它们是根公共状态内所有信息状态的输出策略,在 GT-CFR 的遗憾更新阶段计算。 价值目标可以通过两种不同的方式获得。首先,游戏的结果被用作沿着由sound自我播放生成的情节主线的状态的 (TD(1)) 值目标。其次,价值目标也是通过引导获得的:从以输入查询为根的子博弈运行 GT-CFR 的实例。原则上,任何求解器都可以使用,因为任何以 β 为根的子博弈都有明确定义的值。因此,这一步通过 2.3 节中描述的分解来充当策略改进算子。具体来说,价值目标是在 GT-CFR 迭代 T 次后,对于发起搜索的公共状态中的所有信息状态的最终反事实值。分配不同值目标的具体方式由 B.5 节中的伪代码描述,并由 B.4 节中描述的超参数确定。
虽然求解器是查询的计算目标,但它也通过运行 GT-CFR 自己生成更多查询。其中一些递归查询也被添加到缓冲区中以备将来解决。因此,在任何给定时间,缓冲区可能包括由主自玩游戏中的搜索生成的查询或主线外求解器生成的查询。为了确保缓冲区不受递归查询的支配,我们将添加新递归查询的概率设置为小于 1(在我们的实验中,该值通常为 0.1 或 0.2;有关确切值,请参阅第 B.4 节)。
3.4.4 培训过程的一致性
一个自然的问题是,训练过程是否或在什么情况下可以确保收敛到最佳值?答案是肯定的:训练过程逐渐收敛到最优值,随着 T → ∞ 并且具有非常大的(指数)内存。 非正式地,想象一个 oracle 函数 f (β),它可以简单地记住特定 β 的值和策略,类似于表格值或策略迭代算法,除了连续键。对于以深度为 1 的某个 β 为根的任何子博弈(每个动作都会导致最终状态),可以在求解器的 T 次迭代之后为 β 计算和存储值和策略。然后可以归纳应用:由于 CFR 是确定性的,对于 GT-CFR 第一次迭代的任何子博弈,将生成有限数量的查询。这些查询中的每一个都将使用 GT-CFR 解决。最终,查询将是一个特定的查询,距离终端状态有一步,其值可以精确计算并存储在 f (β) 中。由于此值是在自游戏中或由查询求解器生成的,并且 CFR 是确定性的,因此它将产生另一个具有相同查询的自游戏游戏,除了它会从 f (β) 加载求解的值,并归纳这些值将自下而上传播。由于 CFR 是确定性的且 T 是有限的,因此尽管存在连续值键,但这些确保内存需求不是无限的。 实际上,训练过程的成功将取决于函数逼近(即神经网络架构)的表示能力和训练效率。
PoG 算法通过健全的自我对弈进行学习:每个玩家在面临要做出的决定时,使用配备反事实价值和策略网络的健全生长树 sound growing-tree CFR 搜索来生成策略,然后将其用于采样要采取的行动。这个过程生成两种类型的训练数据:搜索查询,然后单独解决(有时递归生成新查询)和完整游戏轨迹。训练过程以不同的方式使用数据:游戏的结果和解决的查询来训练网络的价值头,以及沿着主线搜索的策略输出来训练网络的策略头。在实践中,self-play 数据的生成和训练是并行发生的:actors 生成 self-play 数据(并解决查询),而训练者学习新网络并定期更新 actor。 有关算法的完整详细描述,包括超参数值和上述每个过程的具体描述,请参见附录 B。
游戏玩家建立在之前工作中开发的几个组件的基础上。在本节中,我们将描述这些过去最相关的作品以及它们与 PoG 的关系。
PoG 结合了许多最初在 AlphaZero 及其前身以及 DeepStack 中提出的元素 [70, 72, 71, 55]。具体来说,PoG 使用来自 AlphaGo 和 DeepStack 的深度神经网络的组合搜索和学习,以及来自 DeepStack 的不完全信息游戏中的博弈论推理和搜索。在不完全信息游戏中使用公共信念状态和分解是无限注德州扑克取得成功的关键组成部分 [15, 10, 55, 11, 13, 12, 7]。与 AlphaZero 的主要区别在于 PoG 中的搜索和自我对弈训练也适用于不完美信息游戏和跨游戏类型的评估。与 DeepStack 的主要区别在于使用明显较少的领域知识:使用自我对弈(而不是特定于扑克的启发式)来生成训练数据和用于游戏所有阶段的单个网络。最密切相关的算法是基于循环信念的学习 (ReBeL) [7]。与 PoG 一样,ReBeL 通过自我对弈结合了搜索、学习和博弈论推理。主要区别在于 PoG 基于(安全)连续解析和sound self-play。为了实现 ReBeL 的保证,它的测试时间搜索必须使用与训练相同的算法进行,而 PoG 可以使用第 3.1 节中描述的形式的任何基于信念的价值和策略网络(类似于例如 AlphaZero,它训练使用 800 次模拟,但随后可以在测试时使用更大的模拟限制)。 PoG 在不同游戏类型的许多不同挑战游戏中也得到了实证验证。
—-what
在寻找不完美信息博弈方面已经有大量工作。在实践中非常成功的一种方法是确定性:在决策时,对一组候选世界状态进行采样,并执行某种形式的搜索 [19, 51]。事实上,PimBot [59, 58] 正是基于这些方法并在苏格兰场取得了最先进的成果。然而,这些方法不能保证随着时间的推移收敛到最佳策略。我们在第 C.4 节中证明了这种在实践中缺乏对常见搜索算法和标准 RL 基准的收敛性。相比之下,PoG 中的搜索基于博弈论推理。其他算法已提议在搜索中添加博弈论推理:Smooth UCT [28] 将 UCT [39] 与虚构游戏相结合,但其收敛特性尚不清楚。在线结果抽样 [48] 衍生出蒙特卡罗 CFR [42] 的 MCTS 变体;然而,OOS 只能保证在单一信息状态(局部一致性)下接近近似平衡,并且尚未在大型游戏中进行评估。 PoG 使用的 GT-CFR 使用基于分解的声音搜索,并且是全局一致的 [15, 84]。
已经为两人零和游戏提出了许多 RL 算法:虚构的自我对弈 [29, 30],策略空间响应预言机 (PSRO) [43, 56, 54],双神经 CFR [46],Deep CFR 和 DREAM [8, 76],后悔策略梯度 [75],可利用性下降 [50],神经复制器动力学 (NeuRD) [31],优势后悔匹配演员评论家 [26],摩擦FoReL [60]、MAIO [57]、扩展式双甲骨文 (XDO) [53] 和神经自动课程 (NAC) [21]。这些方法使用于计算(近似)纳什均衡的经典算法适应具有采样经验和一般函数近似的 RL 设置。因此,它们结合了博弈论推理和学习。其中一些方法已显示出可扩展性:Pipeline PSRO 击败了 Stratego Barrage 中最好的公开可用代理; Deep CFR、DREAM 和 ARMAC 在大型扑克游戏中显示出可喜的结果。结合人类数据,AlphaStar 能够使用博弈论推理来创建大师级的实时策略策略 [83]。然而,他们都不能在测试时使用搜索来完善他们的策略。
最后,有些作品将搜索、学习和/或博弈论推理的某种组合应用于特定领域。神经网络已经通过 Q-learning 训练来学习玩苏格兰场 [20];然而,由此产生的政策的整体发挥实力并没有直接与任何其他已知的苏格兰场经纪人进行比较。在扑克中,Supremus 对 DeepStack 提出了许多改进,并证明它们在与人类专家比赛时产生了很大的不同 [85]。另一项工作使用了一种受 DeepStack 启发的方法应用于 The Resistance [69]。在合作环境中,一些作品利用基于信念的学习(和搜索)使用公共子博弈分解 [22, 45, 73],应用于 Hanabi [4]。搜索和强化学习相结合,产生了一个与最先进的机器人(WBridg e5) 和人类 [49]。 最近,学习和博弈论推理也被结合起来,在协作游戏 Overcooked [77] 中,在没有人类数据的情况下,产生了与人类一起玩得很好的代理。 值得注意的是(无新闻)外交游戏。 博弈论推理与最佳响应策略迭代中的学习相结合 [2]。 博弈论搜索和监督学习被用于 [25] 在两人变体上达到人类水平的表现。 最近,这三者结合在 DORA [3] 中,它学会了在没有人类数据的情况下玩外交,并且在两人变体上也达到了人类水平的表现。 PoG 与这些作品的主要区别在于它们专注于特定的游戏并利用特定领域的知识来获得强大的性能。
在本文中,我们描述了游戏玩家 **(PoG) 一种结合了搜索、学习和博弈论推理的统一算法。 PoG 由两个主要部分组成:一种新颖的生长树反事实后悔最小化(GT-CFR),以及通过自我博弈学习反事实价值和策略网络的健全自我博弈。**最值得注意的是,PoG 是一种适用于完美和不完美信息博弈的健全算法:随着计算资源的增加,PoG 可以保证产生更好的极小极大优化策略的近似。这一发现也在 Leduc 扑克(简易德州玩法)中得到了经验验证,与任何不使用搜索的纯强化学习算法不同,额外的搜索会导致测试时间近似的细化。
PoG 是此类中第一个使用最少领域知识在挑战领域展示强大性能的合理算法。在国际象棋和围棋的完美信息游戏中,PoG 的性能达到人类专家或专业人士的水平,但在给定相同资源的情况下,其性能明显弱于此类游戏的专用算法,如 AlphaZero。在不完全信息游戏无限注德州扑克中,PoG 击败了 Slumbot,这是最好的公开可用的扑克代理,并且表明不会被使用特定于扑克的启发式的本地最佳响应代理利用。在苏格兰场,PoG 击败了最先进的代理人。
PoG 有一些局限性值得在未来的工作中研究。首先,可以删除扑克中投注抽象的使用,以支持大型动作空间的一般动作减少策略。其次,PoG 目前需要枚举每个公共状态的信息状态,这在某些游戏中可能会非常昂贵;这可以通过一个生成模型来近似,该模型对世界状态进行采样并对采样的子集进行操作。最后,大量的计算资源用于在挑战领域获得强大的发挥;一个有趣的问题是,是否可以使用较少的计算资源来实现这种级别的游戏。
Contents
[toc]
1.window+R打开管理
2.输入regedit后回车,则就会打开注册表编辑器
3.里面有一个cacaheId然后删掉,果断的删掉
计算机\HKEY_CURRENT_USER\Software\ScooterSoftware\BeyondCompare\
4.找到他的老巢(安装路径)然后删除BCUnrar.dll
5.好了打开就可以用了
打开Beyond Compare 4,提示已经超出30天试用期限制,解决方法:
1)在搜索栏中输入 regedit ,打开注册表
2) 删除项目:计算机\HKEY_CURRENT_USER\Software\ScooterSoftware\Beyond Compare 4\CacheId
wget https://www.scootersoftware.com/bcompare-4.4.2.26348_amd64.deb
过期处理:
1 | rm -rf /home/xxx/.config/bcompare/registry.dat |
cRARk是为数不多的最快的RAR密码恢复工具之一。更重要的是,它完全免费使用。除了作为RAR密码恢复功能之外,cRARk还可用于不完整的密码和单词列表。它可以用字符补充单词表,这只是冰山一角。
由于其有趣的PCL语言,它使用一种强大的机制来恢复丢失或遗忘的RAR档案密码,并检查wordlist文件中的密码。尽管如此,这种方法在此列表中是最难的,并且不能在此完整地涵盖。
要使用此应用程序破解RAR密码,您需要……
1.首先,访问http://www.crark.net下载Windows或Linux版本
2.对于Windows用户,根据您的框架有两个版本:OpenCL和CUDA。
3.由于应用程序是命令行工具,您需要打开CMD窗口(Windows)或终端(Linux)并运行一些命令。
4.运行命令后,该工具会在几秒到几分钟内找到您的密码,具体取决于密码的长度。但是,如果找不到您的密码,它会通知您。


1 | cRARk -p"password.def" rarpath |
rarpath 表示要破解的文件位置,password.def是修改好的password definition filename,注意-p后面没有空格,由于win命令行的特性,需要把password.def用引号括起来,不然password和def会分开识别产生错误。password.def的生成方法见上文GUI使用中。
1 | cRARk.exe -l1 -g10 -p"password.def" -n0 rarpath |
但是随着密码位数增长,密码排列组合的结果呈指数式增长,8位密码在我电脑上就需要4个小时了。再加上rar等压缩软件的密码不限于字母数字符号,还可能是汉字或者其他符号等等,因此这个软件比较鸡肋,不是所有的都能破解。
这个软件比较适合于位数比较少的,确定符号在字母数字符号之内的密码的破解,个人电脑使用最好不要超过10位(其实字母数字符号加一起的10位用现在最好的个人电脑恐怕也要算几个星期)。
1 | md5sum |
- 录屏软件(免费)
破解
del C:\Users\Simon\AppData\Roaming\Typora
- typora.log
- profile.data
方法2:
regedit
夜神模拟器需要关闭hyper-v(虚拟机平台)
Vmware则需要开启
Win_cmd:optionalFeatures–>开启关闭此功能(需要重启)
[toc]
深度学习模型加速方向大致分为两种:
一、轻量化网络结构设计
二、模型压缩相关技术
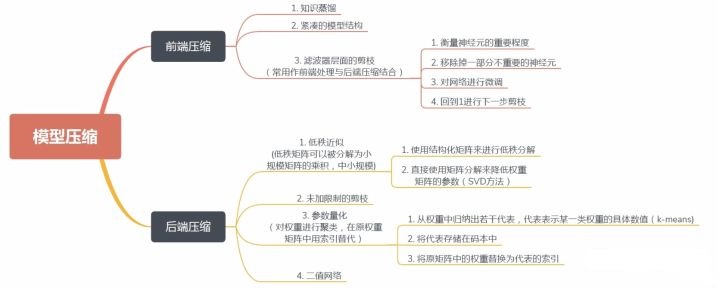
按照压缩过程对网络结构的破坏程度, 我们将模型压缩技术分为“前端压缩”与“后端缩”两部分。
所谓“前端压缩”,是指不改变原网络结构的压缩技术,主要包括知识蒸馏、紧凑的模型结构设计以及滤波器层面的剪枝等;而“后端压缩”则包括低秩近似、未加限制的剪枝、参数量化以及二值网络等,其目标在于尽可能地减少模型大小,因而会对原始网络结构造成极大程度的改造。
其中,由于“前端压缩”未改变原有的网络结构,仅仅只是在原模型的基础上减少了网络的层数或者滤波器的个数,其最终的模型可完美适配现有的深度学习库,如caffe等。相比之下,“后端压缩”为了追求极致的压缩比,不得不对原有的网络结构进行改造,如对参数进行量化表示等,而这样的改造往往是不可逆的。同时,为了获得理想的压缩效果,必须开发相配套的运行库,甚至是专门的硬件设备,其最终的结果往往是一种压缩技术对应于一套运行库,从而带来了巨大的维护成本。
ref: https://zhuanlan.zhihu.com/p/150212141
剪枝,模型量化,压缩,加速
unstructured pruning是指对于individual weights进行prune;structured pruning是指对于filter/channel/layer的prune。其中非结构化修剪方法(直接修剪权重)的一个缺点是所得到的权重矩阵是稀疏的,如果没有专用硬件/库,则不能达到压缩和加速的效果。相反,结构化修剪方法在通道或层的层次上进行修剪。由于原始卷积结构仍然保留,因此不需要专用的硬件/库来实现。在结构化修剪方法中,通道修剪是最受欢迎的,因为它在最细粒度的水平上运行,同时仍然适合传统的深度学习框架。
修建算法三阶段流程

训练:训练大型的过度参数化的模型,得到最佳网络性能,以此为基准;修剪:根据特定标准修剪训练的大模型,即重新调整网络结构中的通道或层数等,来得到一个精简的网络结构;微调:微调修剪的模型以重新获得丢失的性能,这里一般做法是将修剪后的大网络中的保留的(视为重要的)参数用来初始化修剪后的网络,即继承大网络学习到的重要参数,再在训练集上finetune几轮。
然而,在《Rethinking the value of network pruning》(ICLR 2019)这篇论文里,作者做出了几个与常见观点相矛盾的结论,通过测试目前六种最先进的剪枝算法得出以下结论:
作者选择了三个数据集和三个标准的网络结构(数据集:CIFAR-10, CIFAR-100,ImageNet,网络结构:VGG, ResNet,DenseNet),并验证了6个网络裁剪方法,接下来分别介绍这几种当下流行的剪枝算法:
作者:Alex Tian
链接:https://zhuanlan.zhihu.com/p/157562088
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
本方法出自论文《Pruning Filters For Efficient ConvNets》,论文提出了对卷积层(对Filters进行剪枝,以及Feature maps)进行剪枝操作,移除对于CNN精度影响很小的卷积核,然后进行retrain,不会造成稀疏连接(稀疏矩阵操作需要特殊的库等来处理)。

卷积核剪枝原则:(即应该去掉哪些卷积核)
相比于基于其他的标准来衡量卷积核的重要性(比如基于激活值的feature map剪枝),l1-norm是一个很好的选择卷积核的方法,认为如果一个filter的绝对值和比较小,说明该filter并不重要。之后的步骤就是retrain,论文指出对剪枝后的网络结构从头训练要比对重新训练剪枝后的网络(利用了未剪枝之前的权重)的结果差。
本方法出自论文《ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression》,主要贡献:1)基于贪心策略与最小化重建误差,设计了ThiNet剪枝方法,并且是规整的通道剪枝方法;2)将网络剪枝视作优化问题,并利用下一层的输入输出关系获取统计信息,以决定当前层的剪枝;3)在ImageNet数据集上,获得了良好的剪枝效果(主要是Resnet50与VGG-16),并在其他任务上取得了良好的迁移效果。
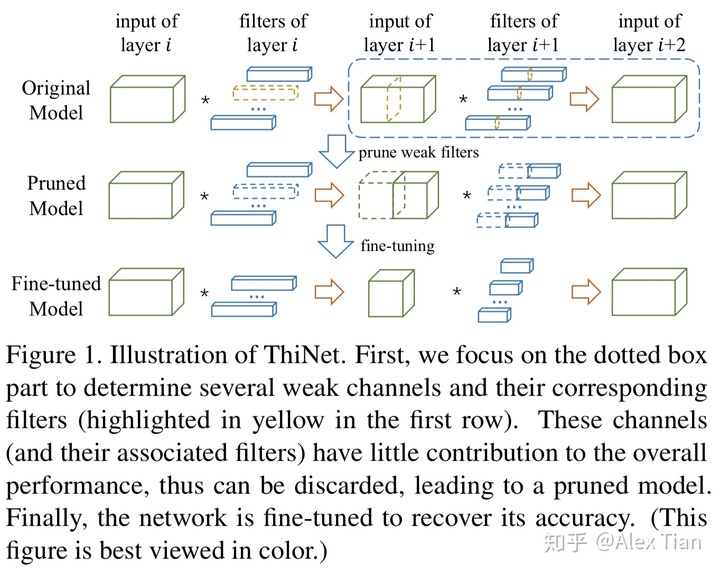
ThiNet的剪枝步骤如上图所示,对于给定的预训练模型以及固定的剪枝率,逐层裁剪冗余的滤波器(3D filters或2D kernels),总体包括通道选择、通道剪枝与fine-tuning三个阶段:
通道选择原则:
寻找通道最优子集用于估计输出特征的Channel Selection,可表示为如下优化问题:
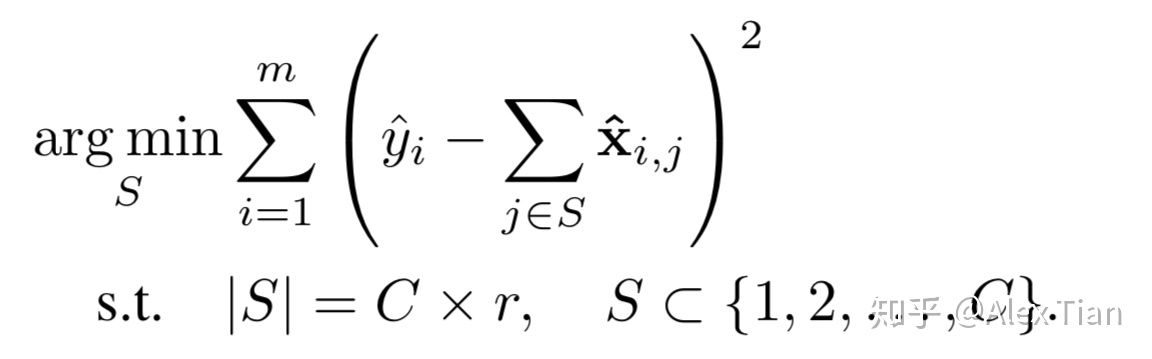
等价而言,定义T 为需要移除的通道子集,其满足 ![[公式]](/2021/12/03/AI/DL/Infrence/%7D.svg+xml) and
and ![[公式]](/2021/12/03/AI/DL/Infrence/oslash.svg+xml) ,则最优化问题可重新写成:
,则最优化问题可重新写成:
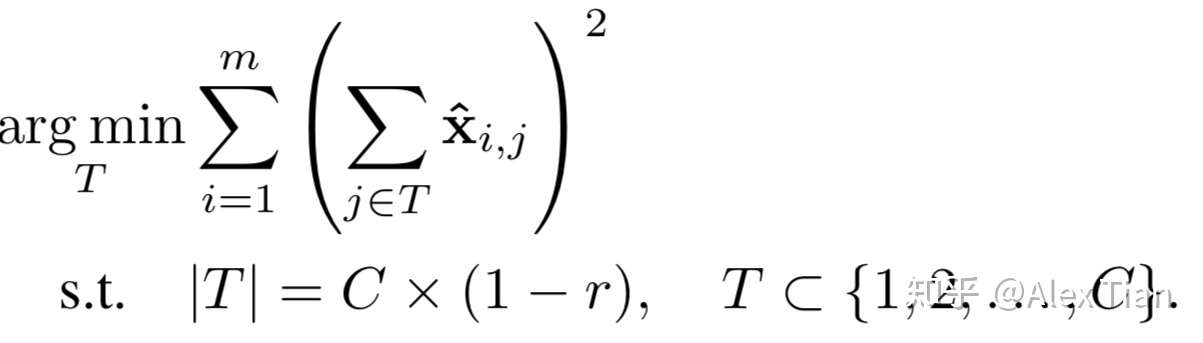
上式亦可理解为,所构建的集合T , 其所包含元素的L2 norm最小。由于集合T 通常比集合S 小,因此求解上述等价问题,具有更高的实现效率。下图是采用贪心策略(Greedy Method)求解集合T 的描述,每次迭代往T 中所添加的元素,需要确保目标函数最小。从而确保完成样本集遍历、并达成目标剪枝率之后,能够删除最不重要的输入特征,最终完成Channel Selection。

以上为应用贪心策略选取需要删除的通道集合。
(三)Regression based Feature Reconstruction
本方法出自论文《Channel Pruning for Accelerating Very Deep Neural Networks》,本文采用了通道剪枝方法,同上一种方法思路一致,考虑减少输入feature maps中的若干channels信息,然后通过调整weights使整体output feature map的信息不会丢失太多。
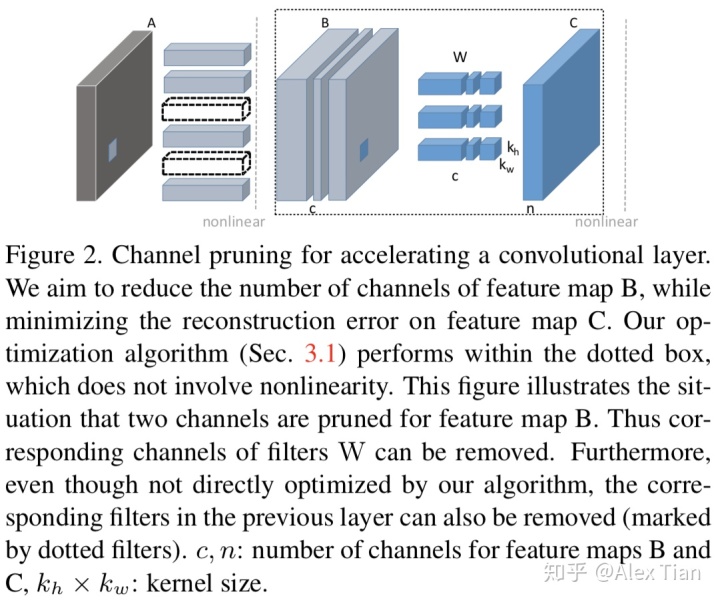
如图所示,目标就是减少B 的feature map, 那么B中的channel被剪掉,会同时使得上游对应的卷积核个数减少,以及下游对应卷积核的通道数减少。关键在于通道选择,如何选择通道而不影响信息的传递很重要。为了进行channel selection ,作者引入了β作为mask ,目标变为 :
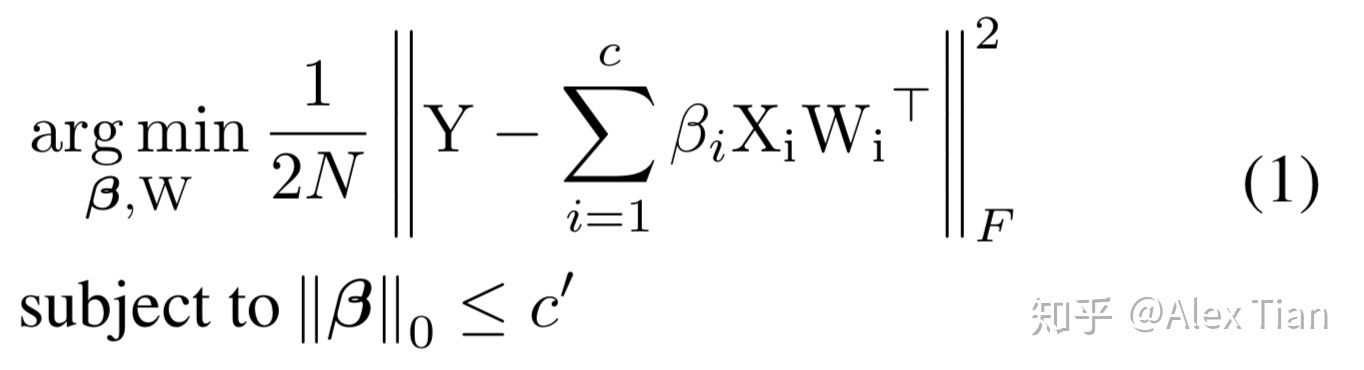
β是一个列向量,如果βi=0 则代表对应的通道被剪除,c ‘代表经过选择后的通道个数 c’<=c,因此作者分两步来优化,首先固定W,优化β ;然后固定β,优化W。而且为了增加β的稀疏度,将β的L1正则项加入优化函数;另外则增加了W的范数为1的强约束以让我们得到的W解不过于简单,原优化函数变为:
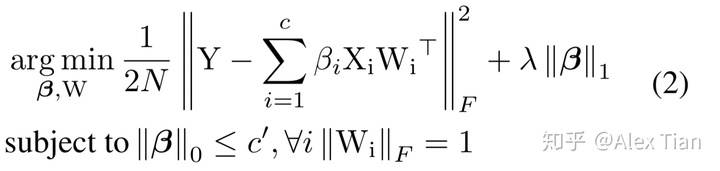
进而我们再将它变为两个分步骤的子优化问题:
(1).求参数β的子优化问题
首先,我们可固定W不变,寻求参数β的组合,即决定输入feature map的哪些input channels可以舍弃。这显然是个NP-hard的组合优化问题,作者使用了经典的启发式LASSO方式来迭代寻找最优的β值,如下公式所示:
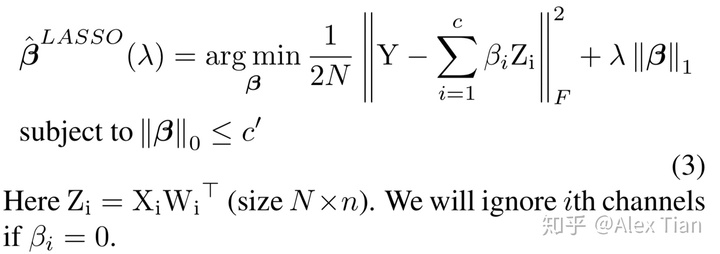
(2).求参数W的子优化问题
然后我们再固定上面得到的β不变,再求解最优的W参数值,本质上就是求解如下的MSE问题:
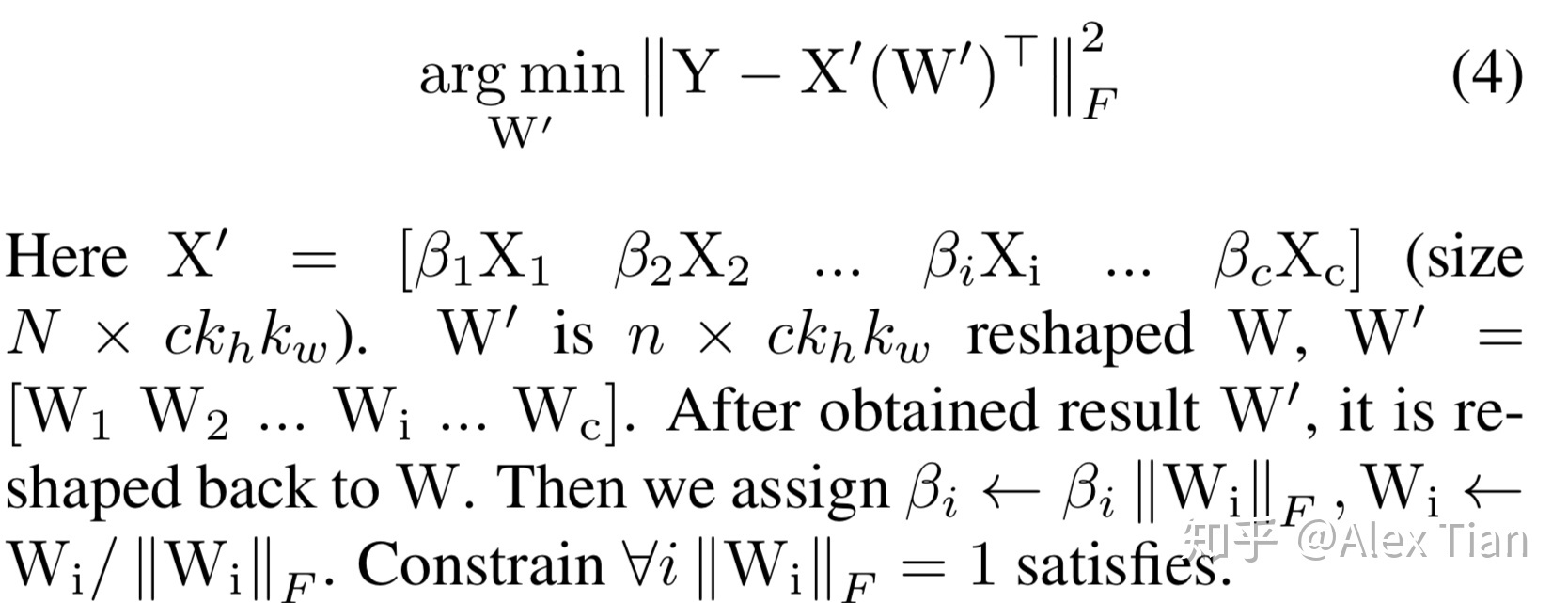
以上所介绍的方法为单个conv层pruning所使用的方法。而在将此方法应用于整个CNN model时,方法也类似,只需要sequentially将此它应用于每个层即可(当然某些特殊的多分支层需要稍稍特殊对待)。
1、量化映射方法,也就是将float-32映射到Int数据类型,每个间隔是相等的还是不相等的,这里就是均匀量化(uniform quantization)和非均匀量化(non-uniform quantization),也可以叫作线性量化和非线性量化
2、关于映射到整数是数值范围是有正负数,还是都是正数,这里就是对称量化(有正负数)和非对称量化(全是正数),非对称量化就有zero-point,zero-point的主要作用是用于做padding。
3、原精度即浮float-32,量化到什么样的数据类型,这里就有float和int;到底要选择量化后的是多少个bit,这里就有1-bit(二值网络)、2-bit(三值网络)、3-bit、4-bit、5-bit、6-bit、7-bit、8-bit,这几种量化后的数值类型是整型。
4、是固定所有网络都是相同的bit-width,还是不同的,这里就有混合精度量化(Mixed precision)
5、是从一个已经训练好的模型再进行量化,还是有fine tune的过程或者直接是从头开始训练一个量化的模型,这里就有Post-training quantization(后量化,即将已经训练完的模型参数进行量化)、quantization-aware training(量化感知训练,即在从头开始训练中加入量化)和quantization-aware fine tune(在fine tune训练中加入量化)。
[TOC]
1 | from __future__ import absolute_import |
1 | #传统的卷积 |
1 | from __future__ import absolute_import |
1 | from __future__ import absolute_import |
如果你的网络有大量相同的参数,如下:
1 | from __future__ import absolute_import |
1 | from tensorflow.contrib.slim.python.slim.nets import alexnet |
损失函数定义了我们想要最小化的数量。 对于分类问题,这通常是跨分类的真实分布和预测概率分布之间的交叉熵。 对于回归问题,这通常是预测值和真值之间的平方和差异。
某些模型(如多任务学习模型)需要同时使用多个损失函数。 换句话说,最终被最小化的损失函数是各种其他损失函数的总和。 例如,考虑预测图像中的场景类型以及每个像素的相机深度的模型。 这个模型的损失函数将是分类损失和深度预测损失的总和。
TF-Slim提供了一个易于使用的机制,通过损失模块定义和跟踪损失功能。 考虑一下我们想要训练VGG网络的简单情况:
sum_of_squares_loss = slim.losses.sum_of_squares(depth_predictions, depth_labels)
regularization_loss = slim.losses.get_regularization_losses()
slim.losses.get_total_loss(add_regularization_losses=False)
1 | import tensorflow as tf |
通过以下功能我们可以载入模型的部分变量:
1 | # Create some variables. |
通过这种方式我们可以加载不同变量名的变量!!
————————————————
版权声明:本文为CSDN博主「醉小义」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_30638831/article/details/81389533
| tf | keras | python | 依赖 | |
|---|---|---|---|---|
| TF2.0 | Keras2.3.1 | 3.6,3.7 | ||
| TF2.1 | Keras2.3.1 | 3.6,3.7 | ||
| TF2.2 | Keras2.3.1 | 3.6-3.8 | ||
| TF2.3 | Keras2.4.3 | 3.6-3.8 | h5py=2.10.0 hdf5=1.10.4 numpy=1.19.2 |
|
| TF2.4 | Keras2.4.3 | 3.6-3.8 | ||
| TF2.5 | 3.6-3.9 | |||
| TF2.6 | Keras2.6 | 3.6-3.9 |
CUDA11.1+cuDNN8.0.5+tensorflow-gpu2.4.1
CUDA11.1+cuDNN8.0.5+tensorflow-gpu2.4.1
CUDA11.1+cuDNN8.0.5+tensorflow-gpu2.4.1
1 | tf.saved_model.load( |
Loading Keras models
1 | model = tf.keras.Model(...) |
tf.gather和tf.gather_nd都是从tensor中取出index标注的部分,不同之处在于,gather一般只使用一个index来标注,而gather_nd可以使用多个index。
1 | import tensorflow.compat.v1 as tf |
1 | [[b'a' b'b'] |
1 | tf.keras.layers.Dense() |
https://www.tensorflow.org/versions/r2.3/api_docs/python/tf/keras/layers/LSTM
1 | inputs = tf.random.normal([32, 10, 8]) |
1 | 解决报错“ImportError: cannot import name 'get_config' from 'tensorflow.python.eager.context'” |
1 | module 'tensorflow_core.compat.v2' has no attribute '__internal__' |
1 | Cannot convert a symbolic Tensor (lstm/strided_slice:0) to a numpy array. |
1 | conda install -c anaconda h5py |
1 | NotImplementedError: Cannot convert a symbolic Tensor |
解决:安装 numpy==1.19.2,太高的numpy版本不行
[TOC]
| TF | Keras | python | |
|---|---|---|---|
| TF1.12 | Keras2.2.4 | ||
| TF1.13 | Keras2.2.4 | ||
| TF1.14 | Keras2.2.5 | 3.6,3.7 | |
| TF1.15 | Keras2.2.5 |
resnet模型搭建
1 | TF_CPP_MIN_LOG_LEVEL 取值 0 : 0也是默认值,输出所有信息 |
1 | update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS, scope) |
1 | update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) |
1 | from tensorflow.python.training import moving_averages |
shadow_variable = decay * shadow_variable + (1 - decay) * variable
1 | ## https://github.com/tensorflow/models/blob/master/tutorials/image/cifar10/cifar10_multi_gpu_train.py |
1 | # 设置exponential moving average |
1 | next_img, next_label = iterator.get_next() |
accuracy, update_op = tf.metrics.accuracy(labels=x, predictions=y)
tf.metrics.accuracy**返回**两个值,**accuracy**为到上一个batch为止的准确度,**update_op**为更新本批次后的准确度。
tf.layers.BatchNormalization
tf.layers.batch_normalization
tf.keras.layers.BatchNormalization
tf.nn.batch_normalization
① tf.nn.moments 这个函数的输出就是BN需要的mean和variance。
1 | tensorflow中实现BN算法的各种函数 |
ref:
tensorflow 中batch normalize 的使用(Slim.BN) https://blog.csdn.net/jiruiyang/article/details/77202674
BN 详解和使用Tensorflow实现(参数理解)https://www.cnblogs.com/WSX1994/p/10949079.html
is_training
tf.GraphKeys.UPDATE_OPS
EMA
l2_loss
tower_loss
average_grad
tf.gradients不允许您计算雅可比矩阵,它会汇总每个输出的梯度(类似于实际雅可比矩阵的每列的总和)。事实上,在TensorFlow中没有“好”的计算Jacobians的方法(基本上你必须每个输出调用tf.gradients一次,see this issue)。
关于tf.train.Optimizer.compute_gradients,是的,其结果基本相同,但是自动处理一些细节并以稍微方便的输出格式。如果你看看the implementation,你会发现它的核心是对tf.gradients(在这种情况下是别名gradients.gradients)的调用,但是对于优化器实现来说已经实现了周围的逻辑非常有用。另外,将它作为一种方法允许子类中的可扩展行为,以实现某种优化策略(不太可能在步骤compute_gradients步骤中)或辅助目的(如跟踪或调试)。
tf.clip_by_global_norm(gradients, max_gradient_norm)
- t_list 表示梯度张量
- clip_norm是截取的比率
global_norm = sqrt(sum(l2norm(t)**2 for t in t_list))
t_list[i] = t_list[i] * clip_norm / max(global_norm, clip_norm)
也就是分为两步:
- 计算所有梯度的平方和global_norm
- 如果梯度平方和 global_norm 超过我们指定的clip_norm,那么就对梯度进行缩放;否则就按照原本的计算结果,这个应该很好理解。
https://bigquant.com/community/t/topic/121493
1 | #from tensorflow.keras.layers import Layer |
[TOC]
1 | # CPU版本 |
1 | import onnxruntime |
如果GPU不可用,可以在 ~/.bashrc 中添加下面两行内容:
1 | export PATH=/usr/local/cuda/bin:$PATH |
Demo:
1 | import onnxruntime |
1 | dummy_input0 = torch.LongTensor(Batch_size, seg_length).to(torch.device("cuda")) |
https://blog.csdn.net/qq_38003892/article/details/89543299
1 | import torch |
原文链接:https://blog.csdn.net/m0_51004308/article/details/116152611
1 | b, h, w, c = model.shape |
1 | import argparse |
1 | import onnxruntime as ort |
存在的问题,动态输入的onnx模型简化是失败,但是可以转tensorrt
原文链接:https://blog.csdn.net/qq_17127427/article/details/115749006
https://www.freesion.com/article/2565433278/
1 |
PyTorch 1.3,TensorRT 6.0,ONNX 1.5
PyTorch 训练好的 CRNN 模型,转换为 ONNX 之后无法转为 TensorRT
原因:
https://github.com/onnx/onnx-tensorrt/blob/master/operators.md
↑ onnx-tensorrt 支持的操作列表,根本就不支持 RNN,包括 LSTM、GRU 等都不支持
用 TensorRT 重新构建网络,并载入训练好的权重
————————————————
原文链接:https://blog.csdn.net/tsukumo99/article/details/103498390
https://blog.csdn.net/u010454261/article/details/114936724